一、HBaes介绍
1.1、HBase的起源
HBase的原型是Google的BigTable论文,受到了该论文思想的启发,目前作为Hadoop的子项目来开发维护,用于支持结构化的数据存储(非结构化数据也可存储-数据挖掘)。
– 2006年Google发表BigTable白皮书。
– 2006年开始开发HBase。
– 2008年北京成功开奥运会,程序员默默地将HBase弄成了Hadoop的子项目。
– 2010年HBase成为Apache顶级项目。
– 现在很多公司二次开发出了很多发行版本,你也开始使用了。
1.2、HBase的角色
1.2.1、HMaster
功能:
1) 监控RegionServer
2) 处理RegionServer故障转移
3) 处理元数据的变更
4) 处理region的分配或移除
5) 在空闲时间进行数据的负载均衡
6) 通过Zookeeper发布自己的位置给客户端
1.2.2、RegionServer
功能:
1) 负责存储HBase的实际数据
2) 处理分配给它的Region
3) 刷新缓存到HDFS
4) 维护HLog(保存数据本身和对数据的操作)
5) 执行压缩
6) 负责处理Region分片
组件:
1) Write-Ahead logs
HBase的修改记录,当对HBase读写数据的时候,数据不是直接写进磁盘,它会在内存中保留一段时间(时间以及数据量阈值可以设定)。但把数据保存在内存中可能有更高的概率引起数据丢失,为了解决这个问题,数据会先写在一个叫做Write-Ahead logfile的文件中,然后再写入内存中。所以在系统出现故障的时候,数据可以通过这个日志文件重建。
2) HFile
这是在磁盘上保存原始数据的实际的物理文件,是实际的存储文件。
3) Store
HFile存储在Store中,一个Store对应HBase表中的一个列族。
4) MemStore
顾名思义,就是内存存储,位于内存中,用来保存当前的数据操作,所以当数据保存在WAL中之后,RegsionServer会在内存中存储键值对。
5) Region
Hbase表的分片,HBase表会根据RowKey值被切分成不同的region存储在RegionServer中,在一个RegionServer中可以有多个不同的region。
1.3、HBase的架构
HBase一种是作为存储的分布式文件系统,另一种是作为数据处理模型的MR框架。因为日常开发人员比较熟练的是结构化的数据进行处理,但是在HDFS直接存储的文件往往不具有结构化,所以催生出了HBase在HDFS上的操作。如果需要查询数据,只需要通过键值便可以成功访问。
架构图如下图所示:
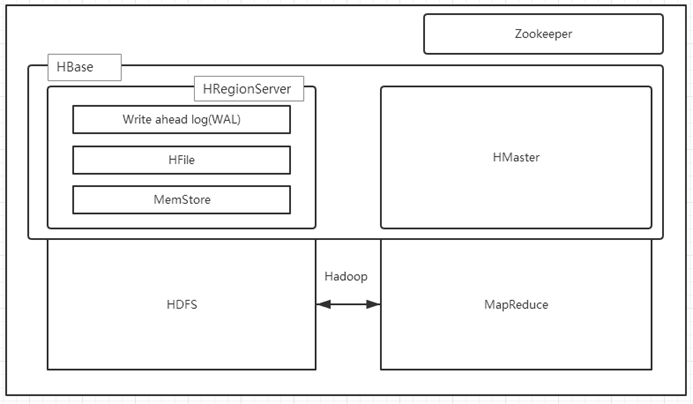
HBase内置有Zookeeper,但一般我们会有其他的Zookeeper集群来监管master和regionserver,Zookeeper通过选举,保证任何时候,集群中只有一个活跃的HMaster,HMaster与HRegionServer 启动时会向ZooKeeper注册,存储所有HRegion的寻址入口,实时监控HRegionserver的上线和下线信息。并实时通知给HMaster,存储HBase的schema和table元数据,默认情况下,HBase 管理ZooKeeper 实例,Zookeeper的引入使得HMaster不再是单点故障。一般情况下会启动两个HMaster,非Active的HMaster会定期的和Active HMaster通信以获取其最新状态,从而保证它是实时更新的,因而如果启动了多个HMaster反而增加了Active HMaster的负担。
一个RegionServer可以包含多个HRegion,每个RegionServer维护一个HLog,和多个HFiles以及其对应的MemStore。RegionServer运行于DataNode上,数量可以与DatNode数量一致,请参考如下架构图:
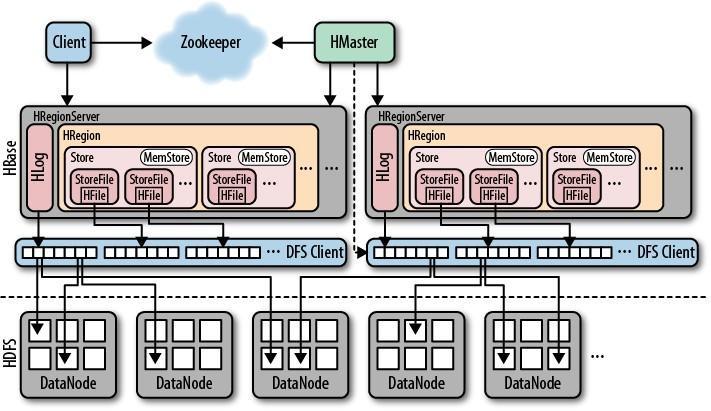
二、HBase部署与使用
2.1、部署
2.1.1、Zookeeper正常部署
首先保证Zookeeper集群的正常部署,并启动之:
$ ~/modules/zookeeper-3.4.5/bin/zkServer.sh start
2.1.2、Hadoop正常部署
Hadoop集群的正常部署并启动:
$ ~/modules/hadoop-2.7.2/sbin/start-dfs.sh $ ~/modules/hadoop-2.7.2/sbin/start-yarn.sh
2.1.3、HBase的解压
解压HBase到指定目录:
$ tar -zxf ~/softwares/installations/hbase-1.3.1-bin.tar.gz -C ~/modules/
2.1.4、HBase的配置文件
需要修改HBase对应的配置文件。
hbase-env.sh**修改内容:**
export JAVA_HOME=/home/admin/modules/jdk1.8.0_121 export HBASE_MANAGES_ZK=false //是否使用hbase内嵌的zookeeper
hbase-site.xml**修改内容:**
|
regionservers:
linux01
linux02
linux03
2.1.5、HBase需要依赖的Jar包
由于HBase需要依赖Hadoop,所以替换HBase的lib目录下的jar包,以解决兼容问题:
1) 删除原有的jar:
$ rm -rf /home/admin/modules/hbase-1.3.1/lib/hadoop-* $ rm -rf /home/admin/modules/hbase-1.3.1/lib/zookeeper-3.4.6.jar
2) 拷贝新jar,涉及的jar有:
|
尖叫提示:这些jar包的对应版本应替换成你目前使用的hadoop版本,具体情况具体分析。
查找jar包举例:
$ find /home/admin/modules/hadoop-2.7.2/ -name hadoop-annotations*
然后将找到的jar包复制到HBase的lib目录下即可。
2.1.6、HBase软连接Hadoop配置
$ ln -s ~/modules/hadoop-2.7.2/etc/hadoop/core-site.xml ~/modules/hbase-1.3.1/conf/core-site.xml $ ln -s ~/modules/hadoop-2.7.2/etc/hadoop/hdfs-site.xml ~/modules/hbase-1.3.1/conf/hdfs-site.xml
2.1.7、HBase远程scp到其他集群
$ scp -r /home/admin/modules/hbase-1.3.1/ linux02:/home/admin/modules/ $ scp -r /home/admin/modules/hbase-1.3.1/ linux03:/home/admin/modules/
2.1.8、HBase服务的启动
启动方式1**:**
|
尖叫提示:如果集群之间的节点时间不同步,会导致regionserver无法启动,抛出ClockOutOfSyncException异常。
修复提示:
a、同步时间服务
请参看帮助文档:《大数据帮助文档》
b、属性:hbase.master.maxclockskew设置更大的值
|
启动方式2*:
$ bin/start-hbase.sh
对应的停止服务:
$ bin/stop-hbase.sh
尖叫提示:如果使用的是JDK8以上版本,则应在hbase-evn.sh中移除“HBASE_MASTER_OPTS”和“HBASE_REGIONSERVER_OPTS”配置。
2.1.9、查看Hbse页面
启动成功后,可以通过“host:port”的方式来访问HBase管理页面,例如:
2.2、简单使用
2.2.1、基本操作
1) 进入HBase**客户端命令行**
$ bin/hbase shell
2) 查看帮助命令
hbase(main)> help
3) 查看当前数据库中有哪些表
hbase(main)> list
2.2.2、表的操作
1) 创建表(同时创建列镞info**)**
hbase(main)> create ‘student’,’info’
2) 插入数据到表(列镞中的列可以动态生成-*info**这个列镞必须是已经存在的)-student类似一个map集合
|
Put相同的键值,会覆盖列的值,跟map的性质一样。
例如:put ‘student’,’1001’,’info:name’,’kingge’ –那么这一列的值就会被覆盖为kingge.
这个时候产生一个问题,原先的Thomas***就消失了嘛?其实不是,之前的值还是存在的。通过时间戳来区分***。(version 版本)
3) 扫描查看表数据
|

时间戳是在插入数据时,默认添加的,目的是为了保存冗余的数据。
注意在hbase中比较大小时按位比较。那么比较大小时STARTROW,根据***ascall**码按位比较***。例如存在行的rowkey有abc、aaa、abcd、e、ac。那么STARTROW => ‘ac’.首先比较第一个字母a,这五个rowkey都满足,再比较第二个字母c,最终只有e、ac满足。故输出这两行的值
4) 查看表结构
hbase(main):012:0> describe ‘student’
5) 更新指定字段的数据(原数据依旧存在,跟java**的map**有所不同)
hbase(main) > put ‘student’,’1001’,’info:name’,’Nick’
hbase(main) > put ‘student’,’1001’,’info:age’,’100’
6) 查看“指定行”或“指定列族:**列”的数据**
hbase(main) > get ‘student’,’1001’
hbase(main) > get ‘student’,’1001’,’info:name’
7) 删除数据
删除某rowkey**的全部数据:**
hbase(main) > deleteall ‘student’,’1001’
删除某rowkey**的某一列数据:**
hbase(main) > delete ‘student’,’1002’,’info:sex’
8) 清空表数据
hbase(main) > truncate ‘student’
尖叫提示:清空表的操作顺序为先disable,然后再truncating。
9) 删除表
首先需要先让该表为disable**状态:**
hbase(main) > disable ‘student’
然后才能drop**这个表:**
hbase(main) > drop ‘student’
尖叫提示:如果直接drop表,会报错:Drop the named table. Table must first be disabled
ERROR: Table student is enabled. Disable it first.
10) 统计表数据行数(按照rowkey**统计)**
hbase(main) > count ‘student’
11) 变更表信息
将info列族中的数据存放3个版本:(默认只保留一个版本)
hbase(main) > alter ‘student’,{NAME=>’info’,VERSIONS=>3}
2.2.3 hbase的表结构

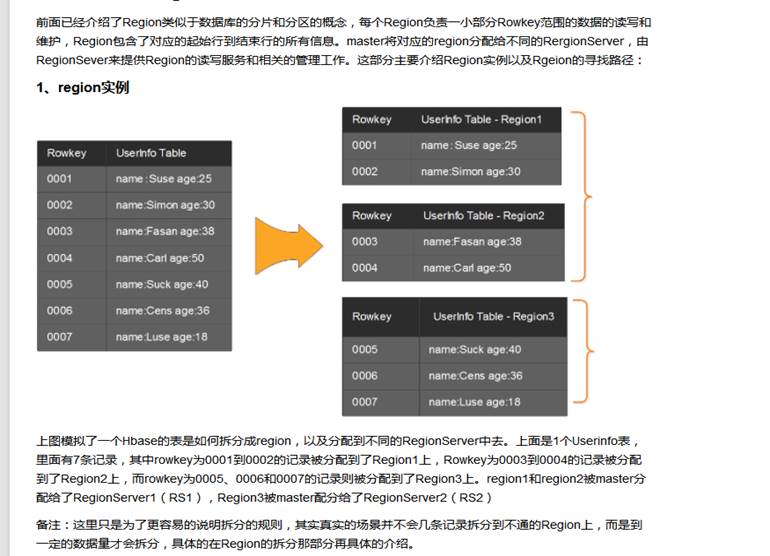
每个表必须有一个唯一的rowkey,已经时间戳(ts),info是一个列镞,也就是说info里面可能包含多个列(图中就包含name和sex两个列- nick和male是这两个列的值)。
那么我们需要给name列赋值,就需要通过一系列属性定位-

2.3、读写流程
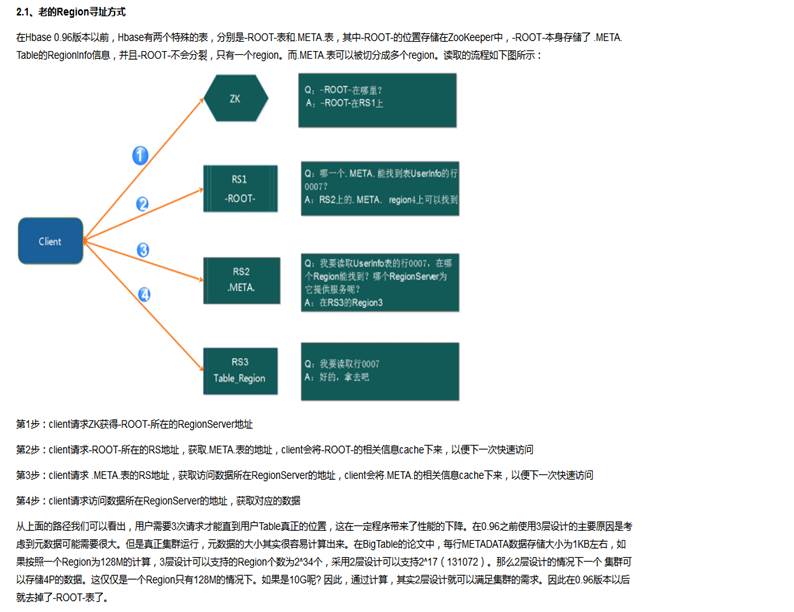
2.3.0 Region的寻址
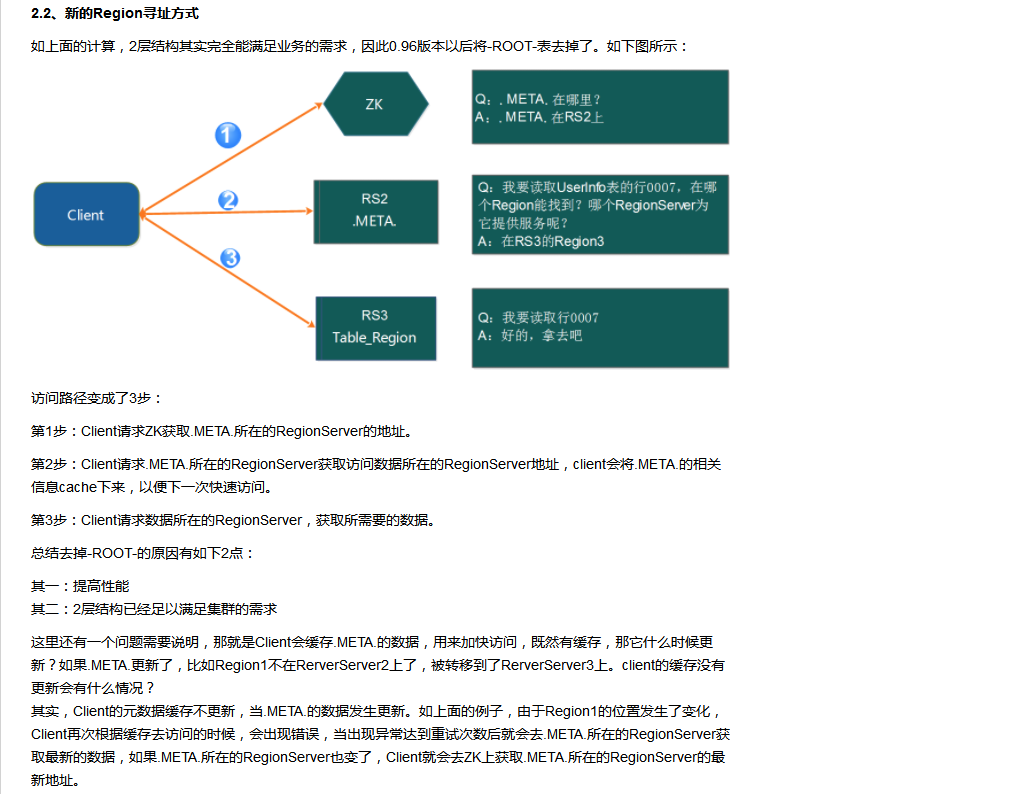
2.3.1、HBase读数据流程
1) HRegionServer保存着.META.的这样一张表以及表数据,要访问表数据,首先Client先去访问zookeeper,从zookeeper里面获取-ROOT-表所在位置,进而找到.META.表所在的位置信息,即找到这个.META.表在哪个HRegionServer上保存着。
2) 接着Client通过刚才获取到的HRegionServer的IP来访问.META.表所在的HRegionServer,从而读取到.META.,进而获取到.META.表中存放的元数据。
3) Client通过元数据中存储的信息,访问对应的HRegionServer,然后扫描所在HRegionServer的Memstore和Storefile来查询数据。
4) 最后HRegionServer把查询到的数据响应给Client。-详细的请看视频,涉及到memorystore(存储写入的数据,内存存储)和blockcache(存储读取的数据。内存存储)的hfile(物理逻辑上的输出-在hdfs中)的读取。
2.3.2、HBase写数据流程
1) Client也是先访问zookeeper,找到-ROOT-表,进而找到.META.表,并获取.META.表信息。
2) 确定当前将要写入的数据所对应的RegionServer服务器和Region。
3) Client向该RegionServer服务器发起写入数据请求,然后RegionServer收到请求并响应。
4) Client先把数据写入到HLog,以防止数据丢失。
5) 然后将数据写入到Memstore。
6) 如果Hlog和Memstore均写入成功,则这条数据写入成功。在此过程中,如果Memstore达到阈值,会把Memstore中的数据flush到StoreFile中。(溢出后,会重新创建一块memostore存储接下来需要写入的数据。当前溢出的memostore会把数据打包放入到一个队列中,等到flush,也即是说一个memstore溢出后写入,对应着一个storefile,一对多的关系)
7) 当Storefile越来越多,会触发Compact合并操作,把过多的Storefile合并成一个大的Storefile(避免datanode出现大量小文件)。当Storefile越来越大,Region也会越来越大,达到阈值后,会触发Split操作,将Region一分为二。
尖叫提示:因为内存空间是有限的,所以说溢写过程必定伴随着大量的小文件产生。
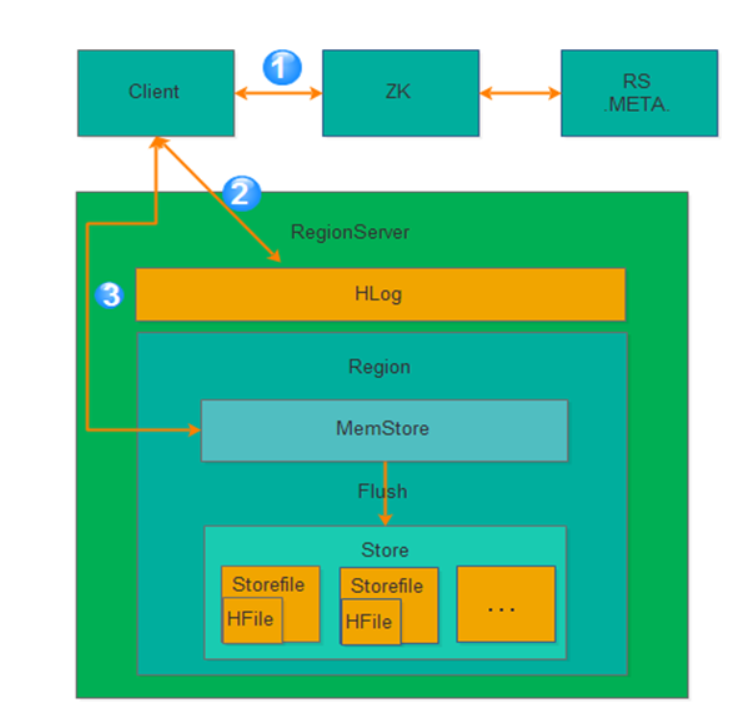
从上图可以看出氛围3步骤:
第1步:Client获取数据写入的Region所在的RegionServer
第2步:请求写Hlog
第3步:请求写MemStore
只有当写Hlog和写MemStore都成功了才算请求写入完成。MemStore后续会逐渐刷到HDFS中。
备注:Hlog存储在HDFS,当RegionServer出现异常,需要使用Hlog来恢复数据。
重申强调上述涉及到的3个机制:
\ Flush**机制:**
当MemStore达到阈值,将Memstore中的数据Flush进Storefile
涉及属性:
hbase.hregion.memstore.flush.size**:134217728**
即:128M就是Memstore的默认阈值
hbase.regionserver.global.memstore.upperLimit**:0.4**
即: 这个参数的作用是当单个HRegion内所有的Memstore大小总和超过指定值时,flush该HRegion的所有memstore。 RegionServer的flush是通过将请求添加一个队列,模拟生产消费模式来异步处理的。那这里就有一个问题,当队列来不及消费,产生大量积压请 求时,可能会导致内存陡增,最坏的情况是触发OOM。
hbase.regionserver.global.memstore.lowerLimit**:0.38**
即: 当MemStore使用内存总量达到hbase.regionserver.global.memstore.upperLimit指定值时,将会有多个 MemStores flush到文件中,MemStore flush 顺序是按照大小降序执行的,直到刷新到MemStore使用内存略小于 hbase.regionserver.global.memstore.lowerLimit。
\ Compact**机制:**
把小的Memstore文件合并成大的Storefile文件。
\ Split**机制**
当Region达到阈值,会把过大的Region一分为二。
2.4、JavaAPI
2.4.1、安装Maven并配置环境变量
$ tar -zxf ~/softwares/installations/apache-maven-3.5.0-bin.tar.gz -C ~/modules/
在环境变量中添加:
MAVEN_HOME=/home/admin/modules/apache-maven-3.5.0 export PATH=$PATH:$MAVEN_HOME/bin
2.4.2、新建Maven Project
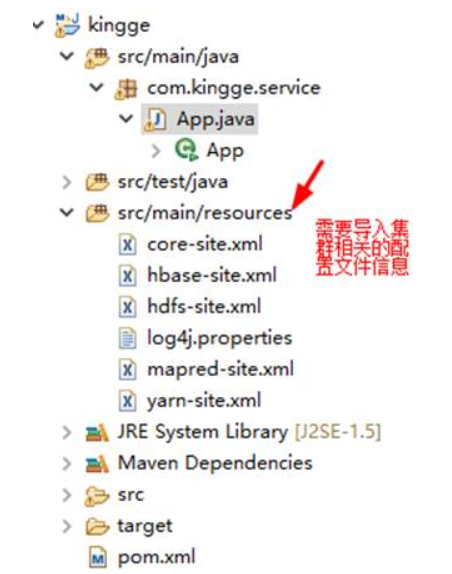
需要三个配置文件信息:core-site.xml**、hdfs-site.xml**、hbase-site.xml
新建项目后在pom.xml中添加依赖:
|
2.4.3、编写HBaseAPI
注意,这部分的学习内容,我们先学习使用老版本的API,接着再写出新版本的API调用方式。因为在企业中,有些时候我们需要一些过时的API来提供更好的兼容性。
1) 首先需要获取Configuration**对象:**
|
2) 判断表是否存在:
|
3) 创建表
|
4) 删除表
|
5) 向表中插入数据
|
6) 删除多行数据
|
7) 得到所有数据
|
8) 得到某一行所有数据
|
9) 获取某一行指定“列族:**列”的数据**
|

2.5、MapReduce
通过HBase的相关JavaAPI,我们可以实现伴随HBase操作的MapReduce过程,比如使用MapReduce将数据从本地文件系统导入到HBase的表中,比如我们从HBase中读取一些原始数据后使用MapReduce做数据分析。
2.5.1、官方HBase-MapReduce
1) 查看HBase**的MapReduce任务的所需的依赖-也就是说当前hbase想要执行mapreduce所需要的依赖**
$ bin/hbase mapredcp
2) 执行环境变量的导入(*注意此次环境变量只会在当前会话框有效,临时的*)
$ export HBASE_HOME= /opt/module/hbase-1.3.1/ $ export HADOOP_CLASSPATH=${HBASE_HOME}/bin/hbase mapredcp
2.2) 执行环境变量的导入(永久-**在hadoop启动时自动加载jar包到环境中)**
\1. 打开hadoop的 hadoop-env.sh
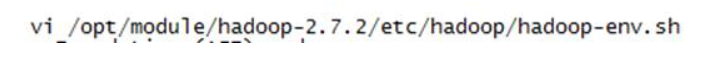
写入命令脚本(如果配置了hbase_home那么可以不书写hbase的全路径,用${HBASE_HOME} 代替即可)
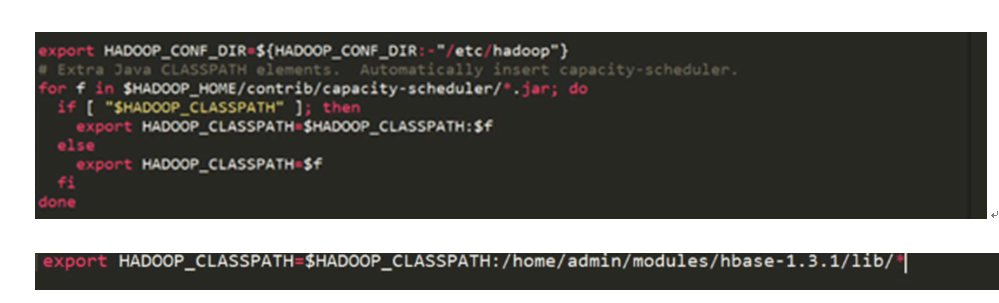
必须放在上面for循环下面,避免被覆盖,同时也要保留for循环已经为hadoop_classpath赋的值。(为了避免被覆盖推荐放到***hadoop-env.sh**的最末尾***)
export HADOOP_CLASSPATH=/opt/module/hbase-1.3.1/bin/hbase mapredcp
\3. hadoop-env.sh分发到hadoop集群
3) 运行官方的MapReduce**任务**
– 案例一:统计Student**表中有多少行数据**
$ ~/modules/hadoop-2.7.2/bin/yarn jar lib/hbase-server-1.3.1.jar rowcounter student
– 案例二:使用MapReduce**将本地数据导入到HBase**
(1) 在本地创建一个tsv**格式的文件:fruit.tsv**
1001 Apple Red 1002 Pear Yellow 1003 Pineapple Yellow
尖叫提示:上面的这个数据不要从word中直接复制,有格式错误
(2) 创建HBase**表**
hbase(main):001:0> create ‘fruit’,’info’
(3) 在HDFS**中创建input_fruit文件夹并上传fruit.tsv文件**
$ ~/modules/hadoop-2.7.2/bin/hdfs dfs -mkdir /input_fruit/
$ ~/modules/hadoop-2.7.2/bin/hdfs dfs -put fruit.tsv /input_fruit/
(4) 执行MapReduce**到HBase的fruit表中(*fruit**表必须已经存在,否则报错***)
$ ~/modules/hadoop-2.7.2/bin/yarn jar lib/hbase-server-1.3.1.jar importtsv \ -Dimporttsv.columns=HBASE_ROW_KEY,info:name,info:color fruit \ hdfs://linux01:8020/input_fruit
(5) 使用scan**命令查看导入后的结果**
hbase(main):001:0> scan ‘fruit’
–***需要注意,从mapreduce**导入数据到hbase**,一般都是结构化的数据,因为非结构化数据导入,你无法确定某一列的数据究竟是对应的是hbase**表那个列镞的列。***
2.5.2、自定义HBase-MapReduce1(hbase导入到hbase)
目标:将fruit表中的一部分数据,通过MR迁入到fruit_mr表中。
分步实现:
1) 构建ReadFruitMapper**类,用于读取fruit**表中的数据
|
2) 构建WriteFruitMRReducer**类,用于将读取到的fruit表中的数据写入到fruit_mr表中**
|
3) 构建Fruit2FruitMRRunner extends Configured implements Tool**用于组装运行Job**任务
|
4) 主函数中调用运行该Job**任务**
|
5) 打包运行任务
$ ~/modules/hadoop-2.7.2/bin/yarn jar ~/softwares/jars/hbase-0.0.1-SNAPSHOT.jar com.z.hbase.mr1.Fruit2FruitMRRunner
尖叫提示:运行任务前,如果待数据导入的表不存在,则需要提前创建之。
尖叫提示:maven打包命令:-P local clean package或-P dev clean package install(将第三方jar包一同打包,需要插件:maven-shade-plugin)
2.5.3、自定义HBase-MapReduce2
目标:实现将HDFS中的数据写入到HBase表中。
分步实现:
1) 构建ReadFruitFromHDFSMapper**于读取HDFS**中的文件数据
|
2) 构建WriteFruitMRFromTxtReducer**类**
|
3) 创建Txt2FruitRunner**组装Job**
|
4) 调用执行Job
public static void main(String[] args) throws Exception { Configuration conf = HBaseConfiguration.create(); int status = ToolRunner.run(conf, new Txt2FruitRunner(), args); System.exit(status); }
5) 打包运行
$ ~/modules/hadoop-2.7.2/bin/yarn jar ~/softwares/jars/hbase-0.0.1-SNAPSHOT.jar com.z.hbase.mr2.Txt2FruitRunner
尖叫提示:运行任务前,如果待数据导入的表不存在,则需要提前创建之。
尖叫提示:maven打包命令:-P local clean package或-P dev clean package install(将第三方jar包一同打包,需要插件:maven-shade-plugin)
2.6、与Hive的集成
2.6.1、HBase与Hive的对比
1) Hive
(1) 数据仓库
Hive的本质其实就相当于将HDFS中已经存储的文件在Mysql中做了一个双射关系,以方便使用HQL去管理查询。
(2) 用于数据分析、清洗
Hive适用于离线的数据分析和清洗,延迟较高。
(3) 基于HDFS**、MapReduce**
Hive存储的数据依旧在DataNode上,编写的HQL语句终将是转换为MapReduce代码执行。
2) HBase
(1) 数据库
是一种面向列存储的非关系型数据库。
(2) 用于存储结构化和非结构话的数据
适用于单表非关系型数据的存储,不适合做关联查询,类似JOIN等操作。
(3) 基于HDFS
数据持久化存储的体现形式是Hfile,存放于DataNode中,被ResionServer以region的形式进行管理。
(4) 延迟较低,接入在线业务使用
面对大量的企业数据,HBase可以直线单表大量数据的存储,同时提供了高效的数据访问速度。
2.6.2、HBase与Hive集成使用
尖叫提示:HBase与Hive的集成在最新的两个版本中无法兼容。所以,我们只能含着泪勇敢的重新编译:hive-hbase-handler-1.2.2.jar!!好气!!
环境准备
因为我们后续可能会在操作Hive的同时对HBase也会产生影响,所以Hive需要持有操作HBase的Jar,那么接下来拷贝Hive所依赖的Jar包(或者使用软连接的形式)。记得还有把zookeeper的jar包考入到hive的lib目录下。
|
同时在hive-site.xml**中修改zookeeper**的属性,如下:
|
1) 案例一
目标:建立Hive表,关联HBase表,插入数据到Hive表的同时能够影响HBase表。
分步实现:
(1) 在Hive**中创建表同时关联HBase*(\会自动的在\hbase**中创建相应的表*)(数据存储在hbase中**)
|
尖叫提示:完成之后,可以分别进入Hive和HBase查看,都生成了对应的表
(2) 在Hive**中创建临时中间表,用于load**文件中的数据
尖叫提示:不能将数据直接load进Hive所关联HBase的那张表中
CREATE TABLE emp( empno int, ename string, job string, mgr int, hiredate string, sal double, comm double, deptno int) row format delimited fields terminated by ‘\t’;
(3) 向Hive**中间表中load**数据
hive> load data local inpath ‘/home/admin/softwares/data/emp.txt’ into table emp;
(4) 通过insert**命令将中间表中的数据导入到Hive关联HBase的那张表中**
hive> insert into table hive_hbase_emp_table select * from emp;
(5) 查看Hive**以及关联的HBase**表中是否已经成功的同步插入了数据
Hive**:**
hive> select * from hive_hbase_emp_table;
HBase**:**
hbase> scan ‘hbase_emp_table’
2) 案例二(常用场景)
目标:在HBase中已经存储了某一张表hbase_emp_table,然后在Hive中创建一个外部表来关联HBase中的hbase_emp_table这张表,使之可以借助Hive来分析HBase这张表中的数据。
注:该案例2紧跟案例1的脚步,所以完成此案例前,请先完成案例1。
分步实现:
(1) 在Hive**中创建外部表**
|
(2) 关联后就可以使用Hive**函数进行一些分析操作了(数据存储在hbase中)**
hive (default)> select * from relevance_hbase_emp;
2.6.3 需要注意
删除表的时候,要先删除hive的表然后再删除habse的。如果反之,删除完hbase的表,那么再去删除hive的表时就会报错(这个时候,退出hive重新登录即可,但是不推荐)
2.7、与Sqoop的集成
Sqoop supports additional import targets beyond HDFS and Hive. Sqoop can also import records into a table in HBase.
之前我们已经学习过如何使用Sqoop在Hadoop集群和关系型数据库中进行数据的导入导出工作,接下来我们学习一下利用Sqoop在HBase和RDBMS中进行数据的转储。
相关参数:
| 参数 | 描述 |
|---|---|
| –column-family |
Sets the target column family for the import 设置导入的目标列族。 |
| –hbase-create-table | If specified, create missing HBase tables 是否自动创建不存在的HBase表(这就意味着,不需要手动提前在HBase中先建立表) |
| –hbase-row-key |
Specifies which input column to use as the row key.In case, if input table contains composite key, then |
| –hbase-table |
Specifies an HBase table to use as the target instead of HDFS. 指定数据将要导入到HBase中的哪张表中。 |
| –hbase-bulkload | Enables bulk loading. 是否允许bulk形式的导入。 |
1) 案例
目标:将RDBMS中的数据抽取到HBase中
分步实现:
(1) 配置sqoop-env.sh**,添加如下内容:**
export HBASE_HOME=/home/admin/modules/hbase-1.3.1
(2) 在Mysql**中新建一个数据库db_library**,一张表book
CREATE DATABASE db_library; CREATE TABLE db_library.book( id int(4) PRIMARY KEY NOT NULL AUTO_INCREMENT, name VARCHAR(255) NOT NULL, price VARCHAR(255) NOT NULL);
(3) 向表中插入一些数据
INSERT INTO db_library.book (name, price) VALUES(‘Lie Sporting’, ‘30’); INSERT INTO db_library.book (name, price) VALUES(‘Pride & Prejudice’, ‘70’); INSERT INTO db_library.book (name, price) VALUES(‘Fall of Giants’, ‘50’);
(4) 执行Sqoop**导入数据的操作**
$ bin/sqoop import \ –connect jdbc:mysql://linux01:3306/db_library \ –username root \ –password 123456 \ –table book \ –columns “id,name,price” \ –column-family “info” \ –hbase-create-table \ –hbase-row-key “id” \ –hbase-table “hbase_book” \ –num-mappers 1 \ –split-by id //一个id一条数据的分割方式,导入hbase
尖叫提示:sqoop1.4.6只支持HBase1.0.1之前的版本的自动创建HBase表的功能
解决方案:手动创建HBase表
hbase> create ‘hbase_book’,’info’
(5) 在HBase**中scan**这张表得到如下内容
hbase> scan ‘hbase_book’
思考:尝试使用复合键作为导入数据时的rowkey。
2.8、常用的Shell操作
1) satus
例如:显示服务器状态
hbase> status ‘linux01’
2) whoami
显示HBase当前用户,例如:
hbase> whoami
3) list
显示当前所有的表
hbase> list
4) count
统计指定表的记录数,例如:
hbase> count ‘hbase_book’
5) describe
展示表结构信息
hbase> describe ‘hbase_book’
6) exist
检查表是否存在,适用于表量特别多的情况
hbase> exist ‘hbase_book’
7) is_enabled/is_disabled
检查表是否启用或禁用
hbase> is_enabled ‘hbase_book’ hbase> is_disabled ‘hbase_book’
8) alter
该命令可以改变表和列族的模式,例如:
为当前表增加列族:
hbase> alter ‘hbase_book’, NAME => ‘CF2’, VERSIONS => 2
为当前表删除列族:
hbase> alter ‘hbase_book’, ‘delete’ => ‘CF2’
9) disable
禁用一张表
hbase> disable ‘hbase_book’
10) drop
删除一张表,记得在删除表之前必须先禁用
hbase> drop ‘hbase_book’
11) delete
删除一行中一个单元格的值,例如:
hbase> delete ‘hbase_book’, ‘rowKey’, ‘CF:C’
12) truncate
清空表数据,即禁用表-删除表-创建表
hbase> truncate ‘hbase_book’
13) create
创建表,例如:
hbase> create ‘table’, ‘cf’
创建多个列族:
hbase> create ‘t1’, {NAME => ‘f1’}, {NAME => ‘f2’}, {NAME => ‘f3’}
2.9、数据的备份与恢复
2.9.1、备份
停止HBase服务后,使用distcp命令运行MapReduce任务进行备份,将数据备份到另一个地方,可以是同一个集群,也可以是专用的备份集群。
即,把数据转移到当前集群的其他目录下(也可以不在同一个集群中):
$ bin/hadoop distcp \ hdfs://linux01:8020/hbase \ hdfs://linux01:8020/HbaseBackup/backup20171009
尖叫提示:执行该操作,一定要开启Yarn服务
2.9.2、恢复
非常简单,与备份方法一样,将数据整个移动回来即可。
$ bin/hadoop distcp \ hdfs://linux01:8020/HbaseBackup/backup20170930 \ hdfs://linux01:8020/hbase
2.10、节点的管理
2.10.1、服役(commissioning)
当启动regionserver时,regionserver会向HMaster注册并开始接收本地数据,开始的时候,新加入的节点不会有任何数据,平衡器开启的情况下,将会有新的region移动到开启的RegionServer上。如果启动和停止进程是使用ssh和HBase脚本,那么会将新添加的节点的主机名加入到conf/regionservers文件中。
2.10.2、退役(decommissioning)
顾名思义,就是从当前HBase集群中删除某个RegionServer,这个过程分为如下几个过程:
1) 停止负载平衡器(HMaster**上操作)**
hbase> balance_switch false
2) 在退役节点上停止RegionServer
hbase> hbase-daemon.sh stop regionserver
3) RegionServer**一旦停止,会关闭维护的所有region**
4) Zookeeper**上的该RegionServer**节点消失
5) Master**节点检测到该RegionServer**下线,开启平衡器
6) 下线的RegionServer**的region**服务得到重新分配
该关闭方法比较传统,需要花费一定的时间,而且会造成部分region短暂的不可用。
另一种方案:
1) RegionServer**先卸载所管理的region**
$ bin/graceful_stop.sh
2) 自动平衡数据
3) 和之前的2~6**步是一样的**
2.11、版本的确界
1) 版本的下界
默认的版本下界是0,即禁用。row版本使用的最小数目是与生存时间(TTL Time To Live)相结合的,并且我们根据实际需求可以有0或更多的版本,使用0,即只有1个版本的值写入cell。
2) 版本的上界
之前默认的版本上界是3,也就是一个row保留3个副本(基于时间戳的插入)。该值不要设计的过大,一般的业务不会超过100。如果cell中存储的数据版本号超过了3个,再次插入数据时,最新的值会将最老的值覆盖。(现版本已默认为1)
三、HBase的优化
3.1、高可用
在HBase中Hmaster负责监控RegionServer的生命周期,均衡RegionServer的负载,如果Hmaster挂掉了,那么整个HBase集群将陷入不健康的状态,并且此时的工作状态并不会维持太久。所以HBase支持对Hmaster的高可用配置。(也就是说,加入***HMaster**挂掉了,hbase**集群还是能工作的,只不过此时所有的读写都操作同一个reginserver**,那么会把它呈报,后面也会不工作。因为失去了HMaster**,失去了负债均衡的能力***)
1) 关闭HBase**集群(如果没有开启则跳过此步)**
$ bin/stop-hbase.sh
2) 在conf**目录下创建backup-masters**文件
$ touch conf/backup-masters
3) 在backup-masters**文件中配置高可用HMaster**节点
$ echo linux02 > conf/backup-masters
4) 将整个conf**目录scp**到其他节点
$ scp -r conf/ linux02:/opt/modules/cdh/hbase-0.98.6-cdh5.3.6/ $ scp -r conf/ linux03:/opt/modules/cdh/hbase-0.98.6-cdh5.3.6/
5) 重新启动HBase**后打开页面测试查看**
0.98版本之前:http://linux01:60010 0.98版本之后:http://linux01:16010
3.2、Hadoop的通用性优化
1) NameNode**元数据备份使用SSD**
2) 定时备份NameNode**上的元数据**
每小时或者每天备份,如果数据极其重要,可以5~10分钟备份一次。备份可以通过定时任务复制元数据目录即可。
3) 为NameNode**指定多个元数据目录**
使用dfs.name.dir或者dfs.namenode.name.dir指定。这样可以提供元数据的冗余和健壮性,以免发生故障。
4) NameNode**的dir**自恢复
设置dfs.namenode.name.dir.restore为true,允许尝试恢复之前失败的dfs.namenode.name.dir目录,在创建checkpoint时做此尝试,如果设置了多个磁盘,建议允许。
5) HDFS**保证RPC**调用会有较多的线程数
hdfs-site.xml
属性:dfs.namenode.handler.count 解释:该属性是NameNode服务默认线程数,的默认值是10,根据机器的可用内存可以调整为50~100 属性:dfs.datanode.handler.count 解释:该属性默认值为10,是DataNode的处理线程数,如果HDFS客户端程序读写请求比较多,可以调高到15~20,设置的值越大,内存消耗越多,不要调整的过高,一般业务中,5~10即可。
6) HDFS**副本数的调整**
hdfs-site.xml
属性:dfs.replication 解释:如果数据量巨大,且不是非常之重要,可以调整为2~3,如果数据非常之重要,可以调整为3~5。
7) HDFS**文件块大小的调整**
hdfs-site.xml
属性:dfs.blocksize 解释:块大小定义,该属性应该根据存储的大量的单个文件大小来设置,如果大量的单个文件都小于100M,建议设置成64M块大小,对于大于100M或者达到GB的这种情况,建议设置成256M,一般设置范围波动在64M~256M之间。
8) MapReduce Job**任务服务线程数调整**
mapred-site.xml
属性:mapreduce.jobtracker.handler.count 解释:该属性是Job任务线程数,默认值是10,根据机器的可用内存可以调整为50~100
9) Http**服务器工作线程数**
mapred-site.xml
属性:mapreduce.tasktracker.http.threads 解释:定义HTTP服务器工作线程数,默认值为40,对于大集群可以调整到80~100
10) 文件排序合并优化
mapred-site.xml
属性:mapreduce.task.io.sort.factor 解释:文件排序时同时合并的数据流的数量,这也定义了同时打开文件的个数,默认值为10,如果调高该参数,可以明显减少磁盘IO,即减少文件读取的次数。
11) 设置任务并发
mapred-site.xml
属性:mapreduce.map.speculative 解释:该属性可以设置任务是否可以并发执行,如果任务多而小,该属性设置为true可以明显加快任务执行效率,但是对于延迟非常高的任务,建议改为false,这就类似于迅雷下载。
12) MR**输出数据的压缩**
mapred-site.xml
属性:mapreduce.map.output.compress、mapreduce.output.fileoutputformat.compress 解释:对于大集群而言,建议设置Map-Reduce的输出为压缩的数据,而对于小集群,则不需要。
13) 优化Mapper**和Reducer**的个数
mapred-site.xml
属性: mapreduce.tasktracker.map.tasks.maximum mapreduce.tasktracker.reduce.tasks.maximum 解释:以上两个属性分别为一个单独的Job任务可以同时运行的Map和Reduce的数量。 设置上面两个参数时,需要考虑CPU核数、磁盘和内存容量。假设一个8核的CPU,业务内容非常消耗CPU,那么可以设置map数量为4,如果该业务不是特别消耗CPU类型的,那么可以设置map数量为40,reduce数量为20。这些参数的值修改完成之后,一定要观察是否有较长等待的任务,如果有的话,可以减少数量以加快任务执行,如果设置一个很大的值,会引起大量的上下文切换,以及内存与磁盘之间的数据交换,这里没有标准的配置数值,需要根据业务和硬件配置以及经验来做出选择。 在同一时刻,不要同时运行太多的MapReduce,这样会消耗过多的内存,任务会执行的非常缓慢,我们需要根据CPU核数,内存容量设置一个MR任务并发的最大值,使固定数据量的任务完全加载到内存中,避免频繁的内存和磁盘数据交换,从而降低磁盘IO,提高性能。
大概估算公式:
map = 2 + ⅔cpu_core
reduce = 2 + ⅓cpu_core
3.3、Linux优化
1) 开启文件系统的预读缓存可以提高读取速度(kb**)**
$ sudo blockdev –setra 32768 /dev/sda
尖叫提示:ra是readahead的缩写
2) 关闭进程睡眠池
即不允许后台进程进入睡眠状态,如果进程空闲,则直接kill掉释放资源
$ sudo sysctl -w vm.swappiness=0
3) 调整ulimit**上限,默认值为比较小的数字**
$ ulimit -n 查看允许最大进程数 $ ulimit -u 查看允许打开最大文件数
优化修改:
$ sudo vi /etc/security/limits.conf 修改打开文件数限制 末尾添加: soft nofile 1024000 hard nofile 1024000 Hive - nofile 1024000 hive - nproc 1024000 $ sudo vi /etc/security/limits.d/90-nproc.conf 修改用户打开进程数限制 修改为: # soft nproc 4096 #root soft nproc unlimited soft nproc 40960 root soft nproc unlimited
4) 开启集群的时间同步NTP
集群中某台机器同步网络时间服务器的时间,集群中其他机器则同步这台机器的时间。
5) 更新系统补丁
更新补丁前,请先测试新版本补丁对集群节点的兼容性。
3.4、Zookeeper优化
1) 优化Zookeeper**会话超时时间**
hbase-site.xml
参数:zookeeper.session.timeout 解释:In hbase-site.xml, set zookeeper.session.timeout to 30 seconds or less to bound failure detection (20-30 seconds is a good start).该值会直接关系到master发现服务器宕机的最大周期,默认值为30秒(不同的HBase版本,该默认值不一样),如果该值过小,会在HBase在写入大量数据发生而GC时,导致RegionServer短暂的不可用,从而没有向ZK发送心跳包,最终导致认为从节点shutdown。一般20台左右的集群需要配置5台zookeeper。
3.5、HBase优化
3.5.1、预分区(避免region被无线切分)(他的本质实际上就是预估rowkey的范围)
每一个region维护着startRow与endRowKey,如果加入的数据符合某个region维护的rowKey范围,则该数据交给这个region维护。那么依照这个原则,我们可以将数据索要投放的分区提前大致的规划好,以提高HBase性能。
1) 手动设定预分区(很明显生成五个分区 负无穷到1000,1000-2000,2000-3000**,3000-4000,4000-**正无穷)
hbase> create animal,’info’,’partition1’,SPLITS => [‘1000’,’2000’,’3000’,’4000’]

2) 生成16**进制序列预分区(直接指定15个分区)**
create ‘staff2’,’info’,’partition2’,{NUMREGIONS => 15, SPLITALGO => ‘HexStringSplit’}
3) 按照文件中设置的规则预分区
创建splits.txt文件内容如下:
aaaa
bbbb
cccc
dddd
然后执行:
create ‘staff3’,’partition3’,SPLITS_FILE => ‘splits.txt’
4) 使用JavaAPI**创建预分区**
|
注意:分区的rowkey必须是有序的递增。否则没有意义
例如:create animal,’info’,’partition1’,SPLITS => [‘4000’,’2000’]
上面的分区脚本很明显会分成三个分区,分别是:-无穷大到4000,4000到2000,2000到正无穷大。这样的分区很明显是存在重叠的。
3.5.2、RowKey设计
一条数据的唯一标识就是rowkey,那么这条数据存储于哪个分区,取决于rowkey处于哪个一个预分区的区间内,设计rowkey的主要目的 ,就是让数据均匀的分布于所有的region中,在一定程度上防止数据倾斜。接下来我们就谈一谈rowkey常用的设计方案。
1) 生成随机数、hash**、散列值**
|
2) 字符串反转
20170524000001转成10000042507102 20170524000002转成20000042507102
这样也可以在一定程度上散列逐步put进来的数据。
3) 字符串拼接
20170524000001_a12e 20170524000001_93i7
3.5.3、内存优化
HBase操作过程中需要大量的内存开销,毕竟Table是可以缓存在内存中的,一般会分配整个可用内存的70%给HBase的Java堆。但是不建议分配非常大的堆内存,因为GC过程持续太久会导致RegionServer处于长期不可用状态,一般16~48G内存就可以了,如果因为框架占用内存过高导致系统内存不足,框架一样会被系统服务拖死。
3.5.4、基础优化
1) 允许在HDFS**的文件中追加内容**
不是不允许追加内容么?没错,请看背景故事:
http://blog.cloudera.com/blog/2009/07/file-appends-in-hdfs/
hdfs-site.xml**、hbase-site.xml**
属性:dfs.support.append 解释:开启HDFS追加同步,可以优秀的配合HBase的数据同步和持久化。默认值为true。
2) 优化DataNode**允许的最大文件打开数**
hdfs-site.xml
属性:dfs.datanode.max.transfer.threads 解释:HBase一般都会同一时间操作大量的文件,根据集群的数量和规模以及数据动作,设置为4096或者更高。默认值:4096
3) 优化延迟高的数据操作的等待时间
hdfs-site.xml
属性:dfs.image.transfer.timeout 解释:如果对于某一次数据操作来讲,延迟非常高,socket需要等待更长的时间,建议把该值设置为更大的值(默认60000毫秒),以确保socket不会被timeout掉。
4) 优化数据的写入效率
mapred-site.xml
属性: mapreduce.map.output.compress mapreduce.map.output.compress.codec 解释:开启这两个数据可以大大提高文件的写入效率,减少写入时间。第一个属性值修改为true,第二个属性值修改为:org.apache.hadoop.io.compress.GzipCodec或者其他压缩方式。
5) 优化DataNode**存储**
属性:dfs.datanode.failed.volumes.tolerated 解释: 默认为0,意思是当DataNode中有一个磁盘出现故障,则会认为该DataNode shutdown了。如果修改为1,则一个磁盘出现故障时,数据会被复制到其他正常的DataNode上,当前的DataNode继续工作。
6) 设置RPC**监听数量**
hbase-site.xml
属性:hbase.regionserver.handler.count 解释:默认值为30,用于指定RPC监听的数量,可以根据客户端的请求数进行调整,读写请求较多时,增加此值。
7) 优化HStore**文件大小**
hbase-site.xml
属性:hbase.hregion.max.filesize 解释:默认值10737418240(10GB),如果需要运行HBase的MR任务,可以减小此值,因为一个region对应一个map任务,如果单个region过大,会导致map任务执行时间过长。该值的意思就是,如果HFile的大小达到这个数值,则这个region会被切分为两个Hfile。
8) 优化hbase**客户端缓存**
hbase-site.xml
属性:hbase.client.write.buffer 解释:用于指定HBase客户端缓存,增大该值可以减少RPC调用次数,但是会消耗更多内存,反之则反之。一般我们需要设定一定的缓存大小,以达到减少RPC次数的目的。
9) 指定scan.next**扫描HBase**所获取的行数
hbase-site.xml
属性:hbase.client.scanner.caching 解释:用于指定scan.next方法获取的默认行数,值越大,消耗内存越大。
10) flush**、compact、split机制**
当MemStore达到阈值,将Memstore中的数据Flush进Storefile;compact机制则是把flush出来的小文件合并成大的Storefile文件。split则是当Region达到阈值,会把过大的Region一分为二。
涉及属性:
即:128M就是Memstore的默认阈值
hbase.hregion.memstore.flush.size:134217728
即:这个参数的作用是当单个HRegion内所有的Memstore大小总和超过指定值时,flush该HRegion的所有memstore。RegionServer的flush是通过将请求添加一个队列,模拟生产消费模型来异步处理的。那这里就有一个问题,当队列来不及消费,产生大量积压请求时,可能会导致内存陡增,最坏的情况是触发OOM。
hbase.regionserver.global.memstore.upperLimit:0.4 hbase.regionserver.global.memstore.lowerLimit:0.38
即:当MemStore使用内存总量达到hbase.regionserver.global.memstore.upperLimit指定值时,将会有多个MemStores flush到文件中,MemStore flush 顺序是按照大小降序执行的,直到刷新到MemStore使用内存略小于lowerLimit
四、HBase项目
4.1、涉及概念梳理:命名空间
4.1.1、命名空间的结构
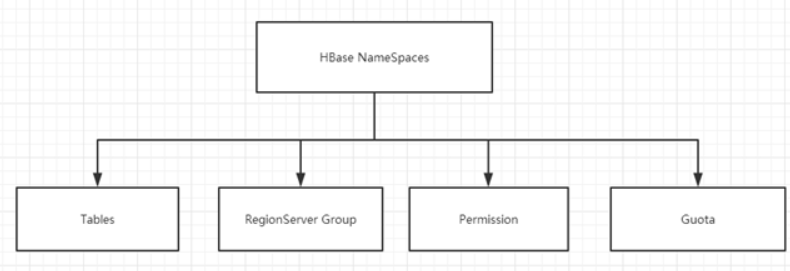
1) Table:表,所有的表都是命名空间的成员,即表必属于某个命名空间,如果没有指定,则在default默认的命名空间中。
2) RegionServer group**:**一个命名空间包含了默认的RegionServer Group。
3) Permission**:**权限,命名空间能够让我们来定义访问控制列表ACL(Access Control List)。例如,创建表,读取表,删除,更新等等操作。
4) Quota**:**限额,可以强制一个命名空间可包含的region的数量。(属性:hbase.quota.enabled)
4.1.2、命名空间的使用
1) 创建命名空间
hbase(main):002:0> create_namespace ‘ns_school’
2) 创建表时指定命名空间
hbase(main):004:0> create ‘ns_school:tbl_student’,’info’
3) 观察HDFS**中的目录结构的变化**

4.2、微博系统
4.1.1、需求分析
1) 微博内容的浏览,数据库表设计
2) 用户社交体现:关注用户,取关用户
3) 拉取关注的人的微博内容
4.1.2、代码实现
代码设计总览:
1) 创建命名空间以及表名的定义
2) 创建微博内容表
3) 创建用户关系表
4) 创建用户微博内容接收邮件表
5) 发布微博内容
6) 添加关注用户
7) 移除(取关)用户
8) 获取关注的人的微博内容
9) 测试
1) 创建命名空间以及表名的定义
|
2) 创建微博内容表
表结构:
| 方法名 | creatTableeContent |
|---|---|
| Table Name | ns_weibo:content |
| RowKey | 用户ID_时间戳 |
| ColumnFamily | info |
| ColumnLabel | 标题,内容,图片 |
| Version | 1个版本 |
代码:
|
3) 创建用户关系表
表结构:
| 方法名 | createTableRelations |
|---|---|
| Table Name | ns_weibo:relation |
| RowKey | 用户ID |
| ColumnFamily | attends、fans |
| ColumnLabel | 关注用户ID,粉丝用户ID |
| ColumnValue | 用户ID |
| Version | 1个版本 |
代码:
|
4) 创建微博收件箱表
表结构:
| 方法名 | createTableInbox |
|---|---|
| Table Name | ns_weibo:inbox |
| RowKey | 用户ID |
| ColumnFamily | info |
| ColumnLabel | 用户ID |
| ColumnValue | 取微博内容的RowKey |
| Version | 1000 |
代码:
|
5) 发布微博内容
a、微博内容表中添加1条数据
b、微博收件箱表对所有粉丝用户添加数据
代码:Message.java
|
代码:public void publishContent(String uid, String content)
|
6) 添加关注用户
a、在微博用户关系表中,对当前主动操作的用户添加新关注的好友
b、在微博用户关系表中,对被关注的用户添加新的粉丝
c、微博收件箱表中添加所关注的用户发布的微博
代码实现:public void addAttends(String uid, String… attends)
|
7) 移除(取关)用户
a、在微博用户关系表中,对当前主动操作的用户移除取关的好友(attends)
b、在微博用户关系表中,对被取关的用户移除粉丝
c、微博收件箱中删除取关的用户发布的微博
代码:public void removeAttends(String uid, String… attends)
|
8) 获取关注的人的微博内容
a、从微博收件箱中获取所关注的用户的微博RowKey
b、根据获取的RowKey,得到微博内容
代码实现:public List getAttendsContent(String uid)
|
9) 测试
– 测试发布微博内容
public void testPublishContent(WeiBo wb)
– 测试添加关注
public void testAddAttend(WeiBo wb)
– 测试取消关注
public void testRemoveAttend(WeiBo wb)
– 测试展示内容
public void testShowMessage(WeiBo wb)
代码:
|
五、总结
不一定所有的企业都会使用HBase,大数据的框架可以是相互配合相互依赖的,同时,根据不同的业务,部分框架之间的使用也可以是相互独立的。例如有些企业在处理整个业务时,只是用HDFS+Spark部分的内容。所以在学习HBase框架时,一定要有宏观思维,了解其框架特性,不一定非要在所有的业务中使用所有的框架,要具体情况具体分析,酌情选择。
5.1、HBase在商业项目中的能力
每天:
1) 消息量:发送和接收的消息数超过60亿-一天每秒七万次请求
2) 将近1000亿条数据的读写
3) 高峰期每秒150万左右操作
4) 整体读取数据占有约55%,写入占有45%
5) 超过2PB的数据,涉及冗余共6PB数据
6) 数据每月大概增长300千兆字节。
5.2、HBase2.0新特性
2017年8月22日凌晨2点左右,HBase发布了2.0.0 alpha-2,相比于上一个版本,修复了500个补丁,我们来了解一下2.0版本的HBase新特性。
最新文档:
http://hbase.apache.org/book.html#ttl
官方发布主页:
举例:
1) region**进行了多份冗余**
主region负责读写,从region维护在其他HregionServer中,负责读以及同步主region中的信息,如果同步不及时,是有可能出现client在从region中读到了脏数据(主region还没来得及把memstore中的变动的内容flush)。
2) 更多变动

