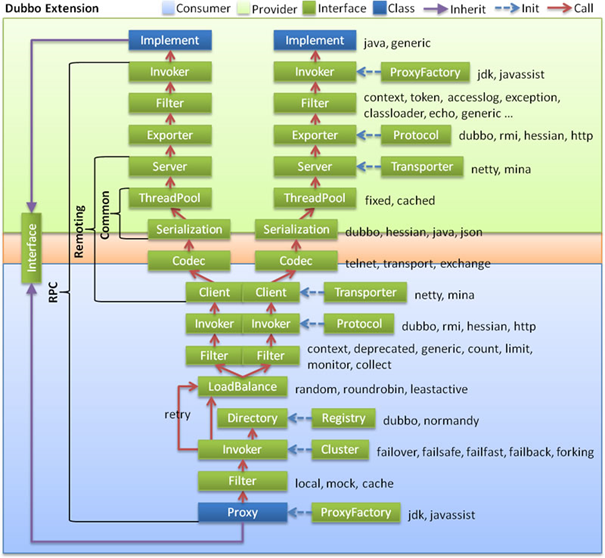
Dubbo分布式服务框架**
一、分布式概念
分布式的概念:某个业务逻辑的完成,拆分成几个功能/服务来实现,这些服务部署在不同的机器上。
官方解释:
分布式系统是由一组通过网络进行通信、为了完成共同的任务而协调工作的计算机节点组成的系统。分布式系统的出现是为了用廉价的、普通的机器完成单个计算机无法完成的计算、存储任务。其目的是利用更多的机器,处理更多的数据。
首先需要明确的是,只有当单个节点的处理能力无法满足日益增长的计算、存储任务的时候,且硬件的提升(加内存、加磁盘、使用更好的CPU)高昂到得不偿失的时候,应用程序也不能进一步优化的时候,我们才需要考虑分布式系统。因为,分布式系统要解决的问题本身就是和单机系统一样的,而由于分布式系统多节点、通过网络通信的拓扑结构,会引入很多单机系统没有的问题,为了解决这些问题又会引入更多的机制、协议,带来更多的问题。
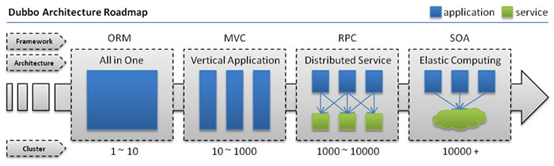
随着互联网的发展,网站应用的规模不断扩大,常规的垂直应用架构已无法应对,分布式服务架构以及流动计算架构势在必行,需一个治理系统确保架构有条不紊的演进。
1.1分布式的演化
1.1.1单一应用架构
当网站流量很小时,只需一个应用,将所有功能都部署在一起(例如),以减少部署节点和成本。
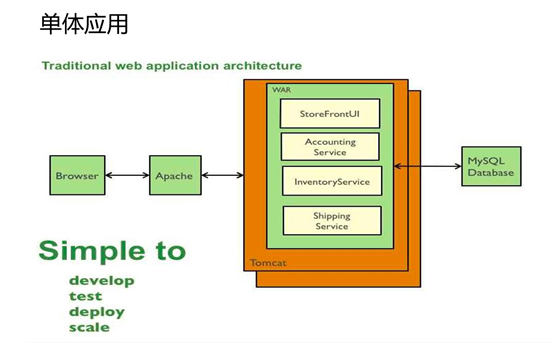
总的来说,一个项目就打包成一个war包,然后订单业务处理、商品等等所有业务都在这个war包里。
适用于小型网站,小型管理系统,将所有功能都部署到一个功能里,简单易用。
缺点:
1、性能扩展比较难
2、存在重复性开发的代码
3、不利于升级维护
4、 只能采用同一种技术,很难用不同的语言或者语言不同版本开发不同模块;
5、系统耦合性强,一旦其中一个模块有问题,整个系统就瘫痪了;一旦升级其中一个模块,整个系统就停机了;
6、 集群只能是复制整个系统,即使只是其中一个模块压力大。(可能整个订单处理,仅仅是支付模块压力过大, 按道理只需要升级支付模块,但是在单一场景里面是不能的)
最直观问题就是,
1.代码不够整洁,多个业务的功能都堆在一个包中,例如UserService、OrderService等等功能都放在com.kingge.service包中。当功能增多时,这个包会变得更加臃肿,代码阅读性很差。
2.服务之间依赖错综复杂不够清晰。
3.只能够通过部署集群来提高系统性能,资源浪费
1.1.2垂直应用架构
当访问量逐渐增大,单一应用增加机器带来的加速度越来越小,将应用拆成互不相干的几个应用,以提升效率,这样就可以单独修改某个模块而不用重启或者影响其他模块,同时也可以给某个访问量剧增的模块,单独添加服务器。
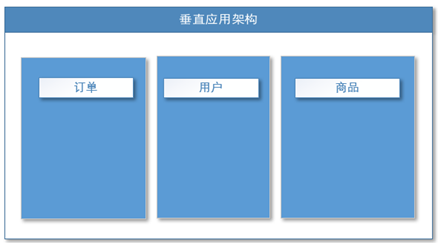
通过切分业务来实现各个模块独立部署,降低了维护和部署的难度,团队各司其职更易管理,性能扩展也更方便,更有针对性。
缺点: 公用模块无法重复利用,开发性的浪费
面对突变的应用场景,可能某个模块对于web界面会频繁修改,但是模块业务功能没有变化,这样会造成单个应用频繁修改。所以需要界面+业务逻辑的实现分离。
没有处理好应用之间的交互问题,例如订单模块可能会需要查询商品模块的信息。
1.1.3分布式服务架构
当垂直应用越来越多,应用之间交互不可避免,将核心业务抽取出来,作为独立的服务,逐渐形成稳定的服务中心,使前端应用能更快速的响应多变的市场需求。此时,用于提高业务复用及整合的分布式服务框架(RPC)是关键(例如Dubbo)。(springcloud比他更全面,Dubbo只是相当于Spring Cloud中的Eureka模块)
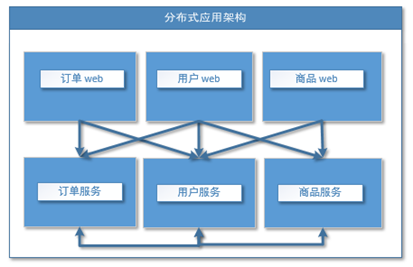
分布式服务框架很好的解决了垂直应用架构的缺点,实现界面和服务的分离,实现界面和服务,以及服务与服务之间的调度。
但是存在一个问题,那就是没有一个基于访问压力的调度中心和服务注册中心,容易造成资源浪费,什么意思呢?假设用户服务部署了200台服务器,但是在某个时间段,他的访问压力很小,订单服务的访问压力剧增,服务器不够用。那么就会造成资源浪费和倾斜,存在服务器闲置或者请求量少的情况。
1.1.4流动计算架构
当服务越来越多,容量的评估,小服务资源的浪费等问题逐渐显现,此时需增加一个调度中心基于访问压力实时管理集群容量,提高集群利用率。此时,用于提高机器利用率的资源调度和治理中心(SOA)[ Service Oriented Architecture]是关键。
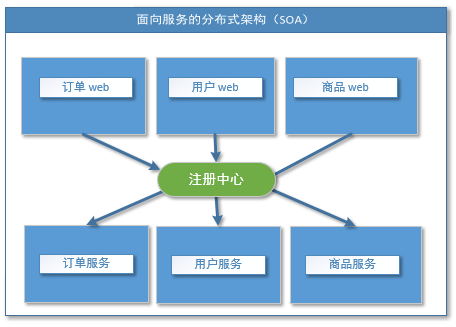
很好的解决了分布式架构的缺点。
SOA解决了服务的管理和注册,但是还是缺少服务容灾处理,网关处理以及全局配置模块等等(分别对应springcloud的hystrix、zuul、config)
1.1.5 微服务架构
其实SOA架构跟微服务架构是很接近的,其实我也不是那么清晰的能够分别这种两种架构,所以这一章节暂缺。
但是他提供了比SOA架构更加细致化的服务拆分和管理,一般常用restful的方式进行数据的传输,SOA架构的传输技术是比较复杂多样的。
他的实现,见springcloud架构
1.2 RPC
1.2.1什么叫RPC
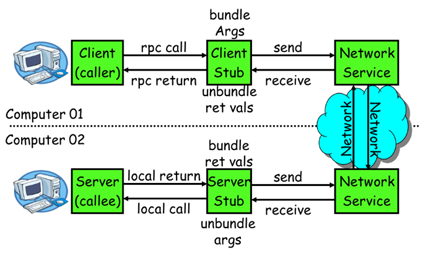
RPC【Remote Procedure Call】是指远程过程调用,是一种进程间通信方式,他是一种技术的思想,而不是规范。它允许程序调用另一个地址空间(通常是共享网络的另一台机器上)的过程或函数,而不用程序员显式编码这个远程调用的细节。即程序员无论是调用本地的还是远程的函数,本质上编写的调用代码基本相同。
1.2.2RPC基本原理
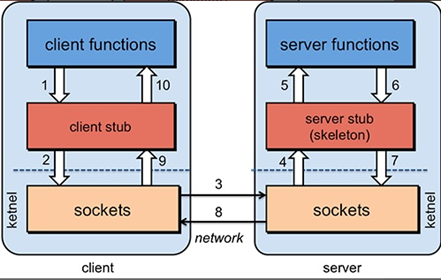
模型中多了一个stub的组件,这个是约定的接口,也就是server提供的服务。注意这里的”接口”,不是指JAVA中的interface,因为RPC是跨平台跨语言的,用JAVA写的客户端,应该能够调用用C语言提供的过程
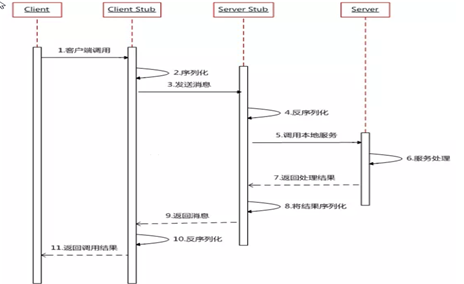
一次完整的RPC调用流程(同步调用,异步另说)如下:
1)服务消费方(client)调用以本地调用方式调用服务;
2)client stub接收到调用后负责将方法、参数等组装成能够进行网络传输的消息体;
3)client stub找到服务地址,并将消息发送到服务端;
4)server stub收到消息后进行解码;
5)server stub根据解码结果调用本地的服务;
6)本地服务执行并将结果返回给server stub;
7)server stub将返回结果打包成消息并发送至消费方;
8)client stub接收到消息,并进行解码;
9)服务消费方得到最终结果。
RPC两个核心模块:通讯,序列化。
也就是说决定RPC连接效率的核心因素了,服务之间通讯的速度,以及消息序列化和反序列化的速度(这个就是为什么hadoop会采用自己的反序列化机制而不是java的反序列化,Java的序列化是一个重量级序列化框架(Serializable),一个对象被序列化后,会附带很多额外的信息(各种校验信息,header,继承体系等),不便于在网络中高效传输。所以,hadoop自己开发了一套序列化机制(Writable),精简、高效)
常用的RPC框架:dubbo,gRPC,thrift。HSF
二、Dubbo概念和理解
2.1 概念
官网:
Apache Dubbo 是一款高性能、轻量级的开源Java RPC框架,它提供了三大核心能力:面向接口的远程方法调用,智能容错和负载均衡,以及服务自动注册和发现。即是:提供高性能和透明化的RPC远程服务调用方案,以及SOA服务治理方案
Dubbo是阿里巴巴公司开源的一个高性能优秀的服务框架,后来Dubbo 进入 Apache 孵化器。
Dubbo 采用全 Spring 配置方式,透明化接入应用,对应用没有任何 API 侵入,只需用 Spring 加载 Dubbo 的配置即可,Dubbo 基于 Spring 的 Schema 扩展 进行加载。
如果不想使用 Spring 配置,可以通过 API 的方式 进行调用。

官方文档
http://dubbo.apache.org/zh-cn/docs/user/quick-start.html
2.2 dubbo结构
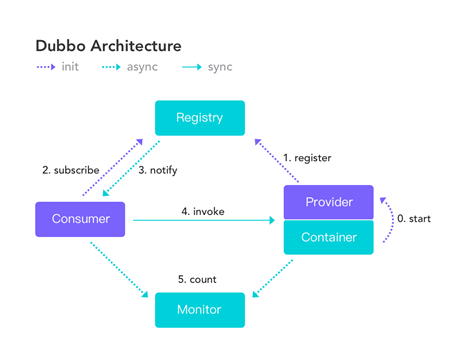
服务提供者(Provider):暴露服务的服务提供方,服务提供者在启动时,向注册中心注册自己提供的服务。
服务消费者(Consumer): 调用远程服务的服务消费方,服务消费者在启动时,向注册中心订阅自己所需的服务,服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
注册中心(Registry):注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者
监控中心(Monitor):服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心
调用关系说明
- 服务容器负责启动,加载,运行服务提供者。
- 服务提供者在启动时,向注册中心注册自己提供的服务。
- 服务消费者在启动时,向注册中心订阅自己所需的服务。
- 注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
- 服务消费者,从提供者地址列表中,基于软负载均衡算法(不是硬件级别的负载均衡),选一台提供者进行调用,如果调用失败,再选另一台调用。
- 服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。
2.3 dubbo架构
Dubbo 架构具有以下几个特点,分别是连通性、健壮性、伸缩性、以及向未来架构的升级性。
连通性
- 注册中心负责服务地址的注册与查找,相当于目录服务,服务提供者和消费者只在启动时与注册中心交互,注册中心不转发请求,压力较小
- 监控中心负责统计各服务调用次数,调用时间等,统计先在内存汇总后每分钟一次发送到监控中心服务器,并以报表展示
- 服务提供者向注册中心注册其提供的服务,并汇报调用时间到监控中心,此时间不包含网络开销
- 服务消费者向注册中心获取服务提供者地址列表,并根据负载算法直接调用提供者,同时汇报调用时间到监控中心,此时间包含网络开销
- 注册中心,服务提供者,服务消费者三者之间均为长连接,监控中心除外
- 注册中心通过长连接感知服务提供者的存在,服务提供者宕机,注册中心将立即推送事件通知消费者
- 注册中心和监控中心全部宕机,不影响已运行的提供者和消费者,消费者在本地缓存了提供者列表
- 注册中心和监控中心都是可选的,服务消费者可以直连服务提供者
健壮性
- 监控中心宕掉不影响使用,只是丢失部分采样数据
- 数据库宕掉后,注册中心仍能通过缓存提供服务列表查询,但不能注册新服务
- 注册中心对等集群,任意一台宕掉后,将自动切换到另一台
- 注册中心全部宕掉后,服务提供者和服务消费者仍能通过本地缓存通讯
- 服务提供者无状态,任意一台宕掉后,不影响使用
- 服务提供者全部宕掉后,服务消费者应用将无法使用,并无限次重连等待服务提供者恢复
伸缩性
- 注册中心为对等集群,可动态增加机器部署实例,所有客户端将自动发现新的注册中心
- 服务提供者无状态,可动态增加机器部署实例,注册中心将推送新的服务提供者信息给消费者
升级性
当服务集群规模进一步扩大,带动IT治理结构进一步升级,需要实现动态部署,进行流动计算,现有分布式服务架构不会带来阻力。下图是未来可能的一种架构:
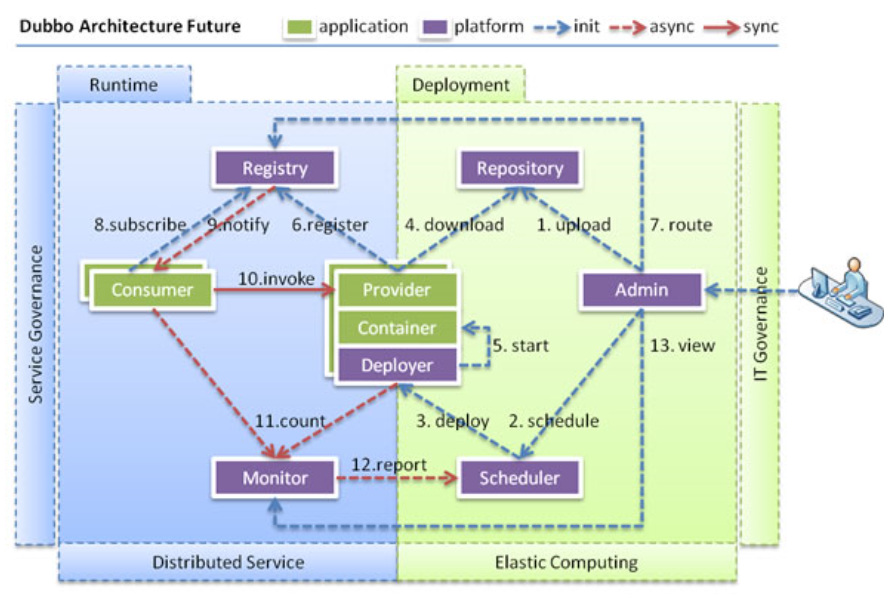
节点角色说明
| 节点 | 角色说明 |
|---|---|
Deployer |
自动部署服务的本地代理 |
Repository |
仓库用于存储服务应用发布包 |
Scheduler |
调度中心基于访问压力自动增减服务提供者 |
Admin |
统一管理控制台 |
Registry |
服务注册与发现的注册中心 |
Monitor |
统计服务的调用次数和调用时间的监控中心 |
三、Dubbo环境搭建
3.1 windows下搭建dubbo环境
3.1.1 安装zookeeper
Dubbo推荐使用zookeeper作为注册中心

1.登录zookeeper官网下载zookeeper
[https://archive.apache.org/dist/zookeeper/zookeeper-3.4.13/]{.underline}
这里以zookeeper-3.4.13为例
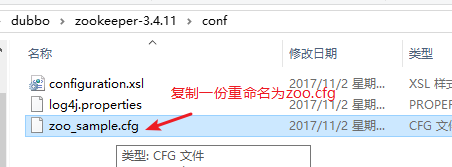
2.下载后解压修改zoo.cfg配置文件
将conf下的zoo_sample.cfg复制一份改名为zoo.cfg即可。
注意几个重要位置:
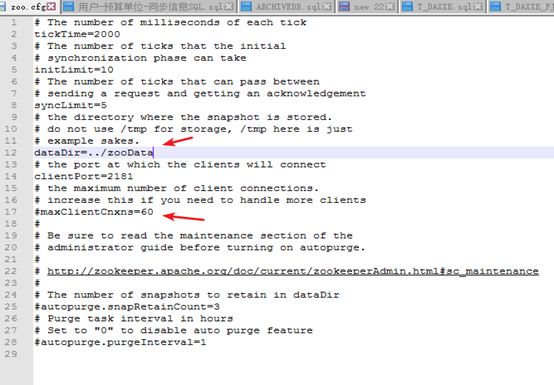
dataDir=./ 临时数据存储的目录(可写相对路径)
clientPort=2181 zookeeper的端口号
修改完成后启动zookeeper
在zookeeeper目录下新建zooData目录保存数据
3. 运行zkServer.cmd
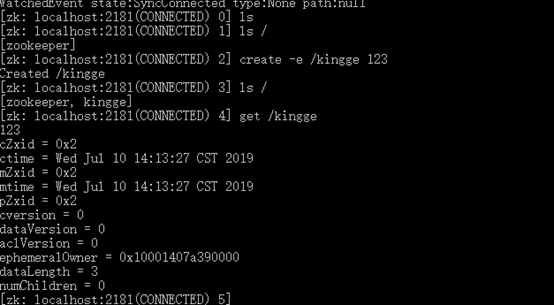
启动成功后,使用zkCli.cmd测试
ls /:列出zookeeper根目录下保存的所有节点
create -e /kingge 123:创建一个临时的kingge节点,值为123
get / kingge:获取/ kingge节点的值
3.1.2安装dubbo-admin管理控制台
dubbo本身并不是一个服务软件。它其实就是一个jar包能够帮你的java程序连接到zookeeper,并利用zookeeper消费、提供服务。所以你不用在Linux上启动什么dubbo服务。
但是为了让用户更好的管理监控众多的dubbo服务,官方提供了一个可视化的监控程序,不过这个监控即使不装也不影响使用。
1、下载dubbo-admin
[https://github.com/apache/incubator-dubbo-ops]{.underline}
下载下来后解压
2、进入目录,修改dubbo-admin配置
修改 src\main\resources\application.properties 指定zookeeper地址

3、打包dubbo-admin(maven环境已经配置好)
mvn clean package -Dmaven.test.skip=true
4、运行dubbo-admin
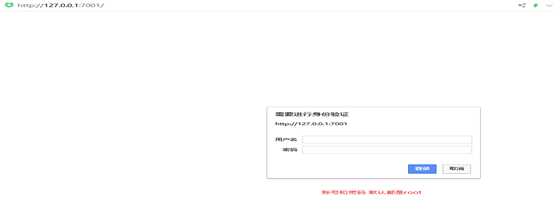
java -jar dubbo-admin-0.0.1-SNAPSHOT.jar (springboot方式启动项目)
注意:【有可能控制台看着启动了,但是网页打不开,需要在控制台按下ctrl+c即可】
默认使用root/root 登陆
3.2 linux下搭建dubbo环境
3.2.1安装zookeeper
1、安装jdk
1、下载jdk
[http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html]{.underline}
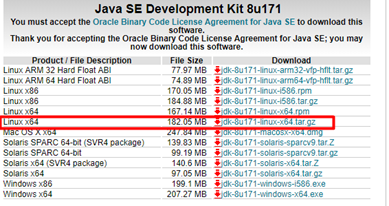
不要使用wget命令获取jdk链接,这是默认不同意,导致下载来的jdk压缩内容错误
2、上传到服务器并解压

3、设置环境变量
/usr/local/java/jdk1.8.0_171

文件末尾加入下面配置
|
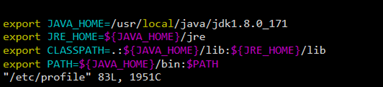
4、使环境变量生效&测试JDK

2、安装zookeeper
1、下载zookeeper
网址 [https://archive.apache.org/dist/zookeeper/zookeeper-3.4.11/]{.underline}
wget [https://archive.apache.org/dist/zookeeper/zookeeper-3.4.11/zookeeper-3.4.11.tar.gz]{.underline}
2、解压

3、移动到指定位置并改名为zookeeper

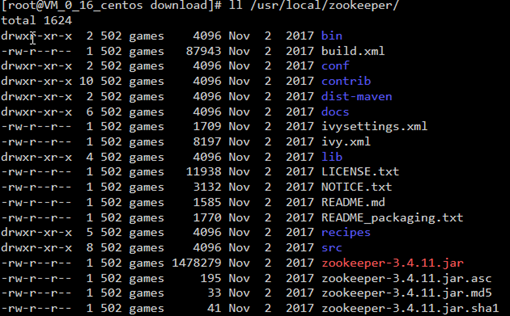
3、开机启动zookeeper(可选)
1)-复制如下脚本
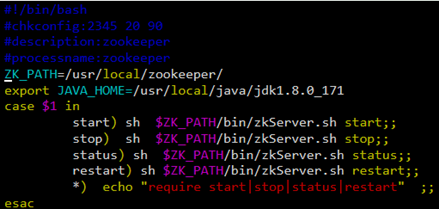
|
2)-把脚本注册为Service
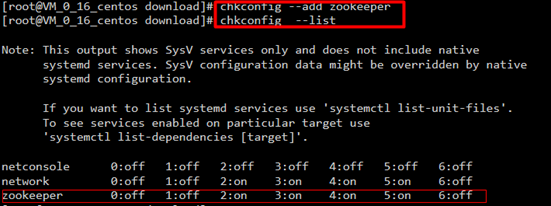
3)-增加权限
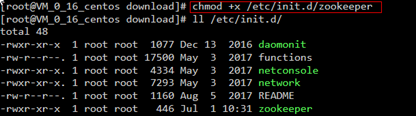
4、配置zookeeper
1、初始化zookeeper配置文件
拷贝/usr/local/zookeeper/conf/zoo_sample.cfg
到同一个目录下改个名字叫zoo.cfg
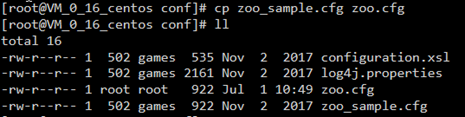
2、启动zookeeper

3.2.2安装dubbo-admin管理控制台
1、安装Tomcat8(旧版dubbo-admin是war,新版是jar不需要安装Tomcat)
1、下载Tomcat8并解压
[https://tomcat.apache.org/download-80.cgi]{.underline}
提供两种访问方式
2、解压移动到指定位置

3、开机启动tomcat8
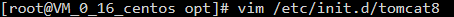
|
4、注册服务&添加权限
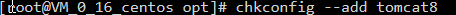

5、启动服务&访问tomcat测试

2、安装dubbo-admin
dubbo本身并不是一个服务软件。它其实就是一个jar包能够帮你的java程序连接到zookeeper,并利用zookeeper消费、提供服务。所以你不用在Linux上启动什么dubbo服务。
但是为了让用户更好的管理监控众多的dubbo服务,官方提供了一个可视化的监控程序,不过这个监控即使不装也不影响使用。
1、下载dubbo-admin
[https://github.com/apache/incubator-dubbo-ops]{.underline}

2、进入目录,修改dubbo-admin配置
修改 src\main\resources\application.properties 指定zookeeper地址

3、打包dubbo-admin
mvn clean package -Dmaven.test.skip=true
4、运行dubbo-admin
java -jar dubbo-admin-0.0.1-SNAPSHOT.jar
默认使用root/root 登陆
3.3 测试dubbo(dubbo-hello)
[http://dubbo.apache.org/zh-cn/docs/user/quick-start.html]{.underline} 官方例子
4.1)、提出需求
某个电商系统,订单服务需要调用用户服务获取某个用户的所有地址;
我们现在 需要创建两个服务模块进行测试
| 模块 | 功能 |
|---|---|
| 订单服务web模块 | 创建订单等 |
| 用户服务service模块 | 查询用户地址等 |
测试预期结果:
订单服务web模块在A服务器,用户服务模块在B服务器,A可以远程调用B的功能。
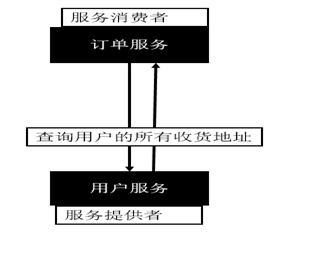
4.2)、工程架构
根据 dubbo《服务化最佳实践》
http://dubbo.apache.org/zh-cn/docs/user/best-practice.html
1、分包(就是抽取公共的接口或者实体类到一个工程)
建议将服务接口,服务模型,服务异常等均放在 API 包中,因为服务模型及异常也是 API 的一部分,同时,这样做也符合分包原则:重用发布等价原则(REP),共同重用原则(CRP)。
如果需要,也可以考虑在 API 包中放置一份 spring 的引用配置,这样使用方,只需在 spring 加载过程中引用此配置即可,配置建议放在模块的包目录下,以免冲突,如:com/alibaba/china/xxx/dubbo-reference.xml。
就是为了避免重复书写某些代码,抽取公共部分代码形成一个模块(例如下面的common-interface),其他模块需要用到时,添加依赖即可(pom文件)
2、粒度
服务接口尽可能大粒度,每个服务方法应代表一个功能,而不是某功能的一个步骤,否则将面临分布式事务问题,Dubbo 暂未提供分布式事务支持。服务接口建议以业务场景为单位划分,并对相近业务做抽象,防止接口数量爆炸。不建议使用过于抽象的通用接口,如:Map query(Map),这样的接口没有明确语义,会给后期维护带来不便。

4.3)、创建模块
1、common-interface:公共接口层(model,service,exception…)(符合分包理念)
作用:定义公共接口,也可以导入公共依赖,保存服务提供者和服务消费者的接口
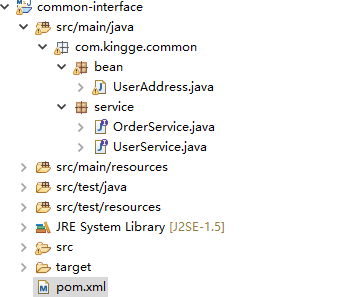

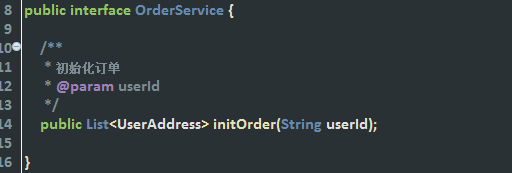
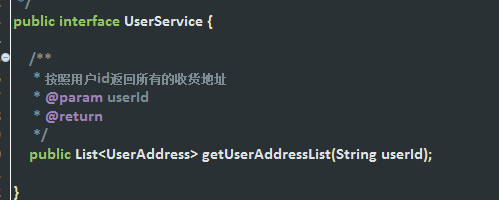
好处就是,可以让服务生产者和消费者同时依赖这个公共接口层maven项目,避免书写重复代码。
2、user-module:用户模块(对用户接口的实现,服务提供者)
- pom.xml (引用公共接口层)
|
- 用户接口实现
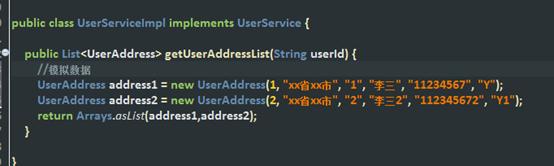
这里为了快速演示,就做了一些虚拟数据,不会去连接数据库。
到时候订单模块只需要调用即可
4、order-module:订单模块(调用用户模块)
1. pom.xml (引用公共接口层)
|
2. 订单接口实现
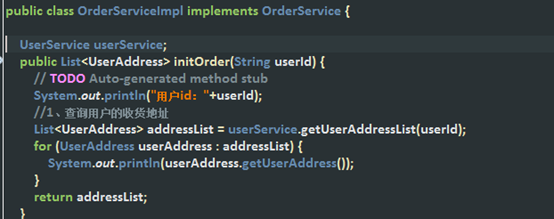
现在这样是无法进行调用的。我们order-module引入了common-interface,但是common-interface公用模块里的用户接口的具体实现在user-module,我们并没有引入user-module模块,所以上诉代码调用肯定是失败的。而且user-module模块可能还在别的服务器中(不在同一个进程中)。
所以我们需要把user-module模块的用户接口的实现类暴露出去,供order-module模块使用。
接下来使用dubbo来实现这样的功能。
4.4)、使用dubbo改造
1、改造user-module作为服务提供者
(1)引入dubbo (pom.xml引入依赖)
|
(2)配置提供者(新建provider.xml文件)

内容如下:
|
dubbo支持多种传输协议
(3)启动服务
|
运行后,打开我们之前配置的dubbo-admin

2、改造order-module作为服务消费者
(1)引入dubbo (pom.xml引入依赖)
|
(2)配置消费者信息
新建consumer.xml文件
|
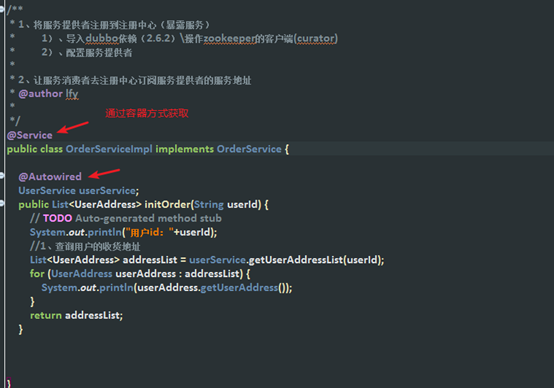
(3)修改OrderServiceImpl
(4)创建启动类,启动consumer
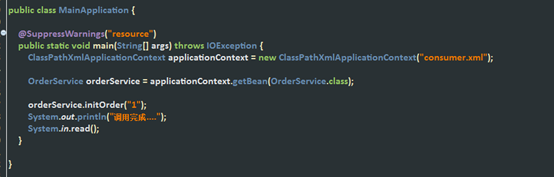
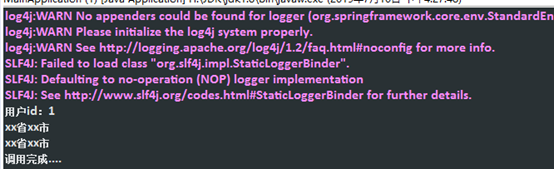
3、测试调用
调用成功
查看dubbo admin

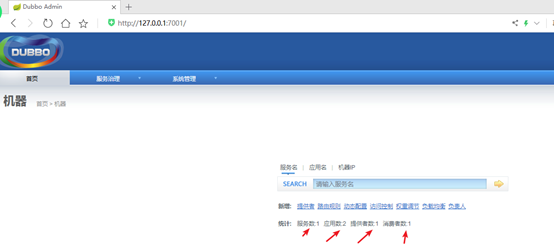
3.4 配置dubbo监控中心
3.4.1 dubbo-admin
图形化的服务管理页面;安装时需要指定注册中心地址,即可从注册中心中获取到所有的提供者/消费者进行配置管理
安装和使用方式在上面我们已经说过了,这里就不在阐述。
3.4.2 dubbo-monitor-simple
简单的监控中心;
1、下载 dubbo-ops
https://github.com/apache/incubator-dubbo-ops
2、修改配置指定注册中心地址
进入 dubbo-monitor-simple\src\main\resources\conf
修改 dubbo.properties文件
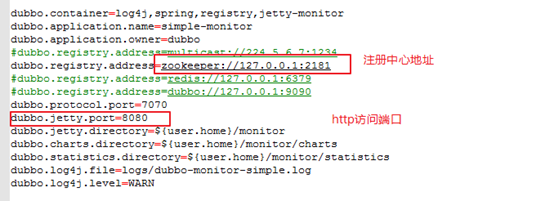
3、打包dubbo-monitor-simple
mvn clean package -Dmaven.test.skip=true
打包完成后,打开target目录,解压下面的tar.gz包
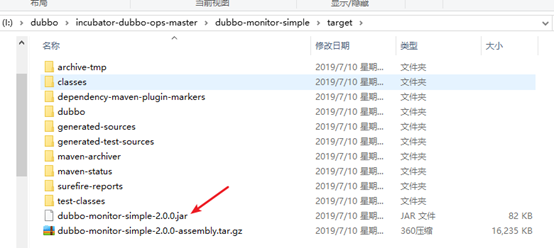
他跟3.4.1 的dubbo-admin不一样,不是一个springboot项目,不能够直接使用java –jar命令执行。
打开解压后的目录

Conf目录存放就是我们的dubbo.properties
assembly.bin目录存放运行dubbo-monitor-simple 的可执行文件

双击 start.bat 执行

4.在项目中使用simple监控中心
以3.3的例子为例:
分别在provider.xml和consumer.xml中添加以下代码
|
然后重新运行项目,再查看

四、dubbo整合springboot
改造4.3章节普通的maven项目为springboot项目,关键代码没有变化,主要是一些配置和依赖发生了变化
关于idea怎么创建多模块项目这里就不阐述了,详情可参见一下网址
[https://blog.csdn.net/tiantangdizhibuxiang/article/details/81130297]{.underline}
https://www.cnblogs.com/zjfjava/p/9696086.html
4.1 新建boot-common-interface:公共接口层(model,service,exception…)(符合分包理念)
一路next完成。
复制4.3.1 章节common-interface的相关代码到此工程
4.2 新建boot-user-module:用户模块
4.2.1 新建模块
一路next创建即可。
4.2.2 代码实现
4.2.2同理复制章节4.3.2 user-module项目代码到此项目并修改pom.xml文件
|
需要注意的是:
注意springboot的starter版本跟dubbo版本适配:
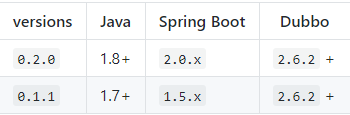
因为本人使用的是springboot2.1.6版本,故使用0.2.0版本dubbo starter
4.2.3修改application.proeprties文件
|
application.name就是服务名,不能跟别的dubbo提供端重复
registry.protocol 是指定注册中心协议
registry.address 是注册中心的地址加端口号
protocol.name 是分布式固定是dubbo,不要改。
dubbo.scan.base-packages 需要暴露的接口的实现类所在的包(跟启动类在同一个包或者子包下都不需要配置这个属性的值,因为springboot启动类会扫描注入。)
dubbo.monitor.protocol 开启simple检测中心
4.2.4 配置需要暴露的服务(通过注解方式)
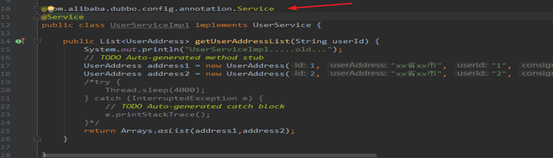
4.2.5 boot启动类开启dubbo功能
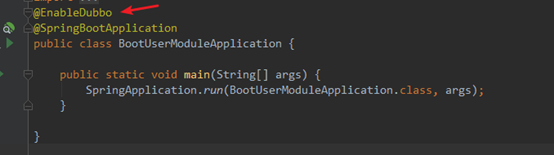
4.2.6 完整项目结构和启动服务提供者
4.3 新建boot-order-module:订单模块
4.3.1 因为我们打算通过web的方式访问controller,再去调用暴露的接口,所以需要引入web依赖
一路next即可
4.3.2 代码实现
4.3.2 同理复制章节4.3.3 order-module项目代码到此项目并修改pom.xml文件
添加一下依赖
<!--引用公用模块-->
<dependency>
<groupId>com.kingge</groupId>
<artifactId>boot-common-interface</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>
<!--引入dubbo starter-->
<dependency>
<groupId>com.alibaba.boot</groupId>
<artifactId>dubbo-spring-boot-starter</artifactId>
<version>0.2.0</version>
</dependency>
4.3.3 修改application.proeprties文件
dubbo.application.name=boot-order-module
dubbo.registry.address= zookeeper://127.0.0.1:2181
dubbo.monitor.protocol=registry
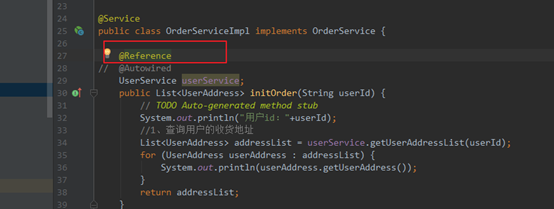
4.3.4 service使用@reference调用暴露接口
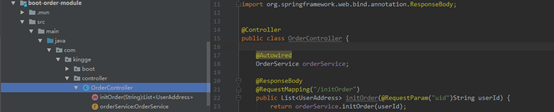
4.3.5 实现一个controller,接受请求
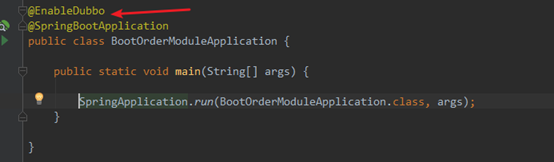
4.3.6 boot启动类开启dubbo功能
4.3.7 启动工程,并访问请求

服务调用成功
4.4 补充
整合dubbo的三种方式:官网
[http://dubbo.apache.org/zh-cn/docs/user/configuration/api.html]{.underline}
* SpringBoot与dubbo整合的三种方式:
* 1)、导入dubbo-starter,在application.properties配置属性,使用\@Service【暴露服务】使用@Reference【引用服务】使用\@EnableDubbo,开启dubbo注解功能(上面例子我们使用的就是这种方式)
* 2)、保留dubbo xml配置文件
* 导入dubbo-starter,使用\@ImportResource导入dubbo的配置文件即可
* 3)、使用注解API的方式:
* 将每一个组件手动创建到容器中,让dubbo来扫描其他的组件
第二种整合方式解决:
如果我们需要在boot-user-module服务提供者配置方法级别的超时时间,那么有没有响应的注解配置呢? 答案是没有的,那么就需要我们使用xml的方式进行配置。
1. 首先去掉@Service、@Reference、@EnableDubbo等注解
2. @ImportResource(locations=\”classpath:provider.xml\”) 使用
ImportResource注解导入外部xml文件
五、Dubbo配置
[http://dubbo.apache.org/zh-cn/docs/user/configuration/annotation.html]{.underline}
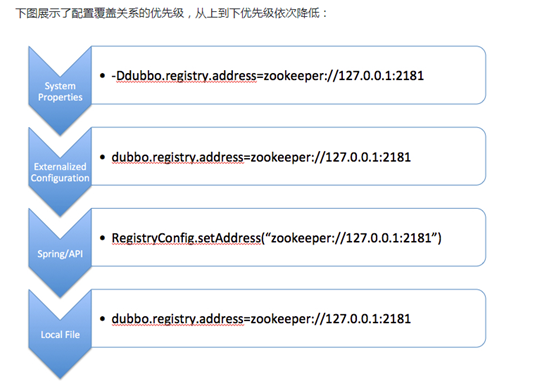
JVM 启动 -D 参数优先,这样可以使用户在部署和启动时进行参数重写,比如在启动时需改变协议的端口。
XML(springboot项目中对应的是application.properties文件) 次之,如果在 XML 中有配置,则 dubbo.properties 和代码中的相应配置项无效。
使用代码设置的方式优先级排在第三。
Properties 最后,相当于缺省值,只有 XML 没有配置时,dubbo.properties 的相应配置项才会生效,通常用于共享公共配置,比如应用名。
六、Dubbo官方提供的例子(功能)
[http://dubbo.apache.org/zh-cn/docs/user/demos/preflight-check.html]{.underline}
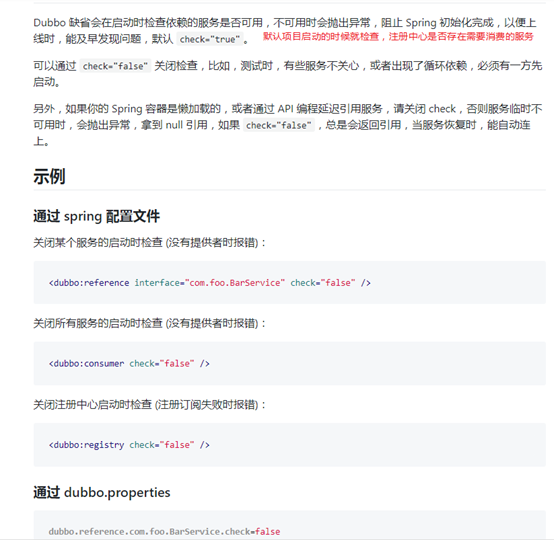
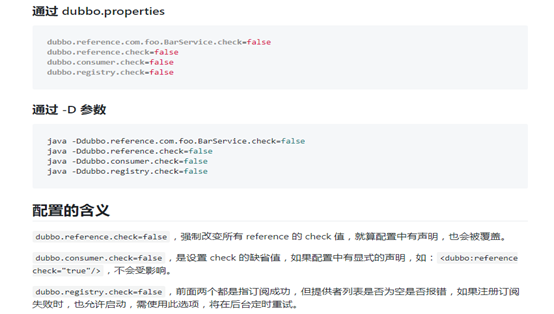
6.1启动时检查
6.2 服务超时调用和重试次数
1. timeout属性
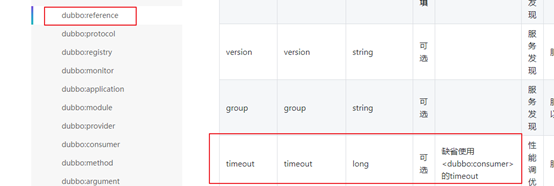

2. retries 属性
默认重试2次,也就是说一共会调用提供者服务三次(第一次调用不计次数)
如果在注册中心,提供者有三个(a1、a2、a3),那么消费者(b1)在重试获取服务的时候,这三个都会可能去调用。
b1请求a1服务超时,发现注册中心存在相同的服务a2、a3那么b1会去请求a2或者a3,当然也有可能再次请求a1
那么什么时候使用这个字段。建议在“幂等”的业务场景下使用,不要在非幂等的场景下使用。
幂等:就是提供者提供的服务,调用多次跟调用一次的起到的作用是一致的(例如对数据库的delete某条数据的操作)
非幂等:单次调用和多次调用的结果是不一样的(数据库的insert操作)
设置为0,表示不进行重试,直接报异常
6.3标签属性配置优先级


6.4多版本
当一个接口实现,出现不兼容升级时,可以用版本号过渡,版本号不同的服务相互间不引用。
可以按照以下的步骤进行版本迁移:
1.在低压力时间段,先升级一半提供者为新版本
2.再将所有消费者升级为新版本
3.然后将剩下的一半提供者升级为新版本
使用场景:新版接口需要替代旧版接口时。

Version=”*“表示任何调用新旧版本
举个例子:
使用第四章节的例子:
1.boot-user-module模块,添加一个新的UserService接口实现类,作为新接口的实现
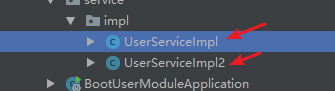
给两个接口添加版本标识(标识新旧接口)


2.修改boot-order-module模块消费者消费接口版本
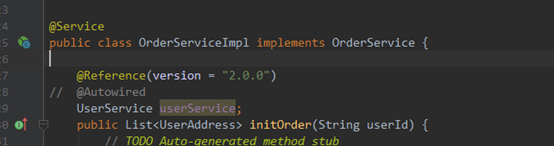
通过version属性实现新旧接口的调用
6.5本地存根

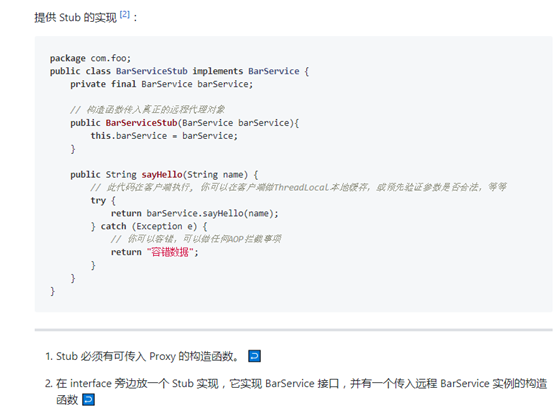
6.6 更多用法参见官网的事例
七、Dubbo高可用
7.1、zookeeper宕机与dubbo直连
现象:zookeeper注册中心宕机,还可以消费dubbo暴露的服务。
原因:
健壮性
- 监控中心宕掉不影响使用,只是丢失部分采样数据
- 数据库宕掉后,注册中心仍能通过缓存提供服务列表查询,但不能注册新服务
- 注册中心对等集群,任意一台宕掉后,将自动切换到另一台
- 注册中心全部宕掉后,服务提供者和服务消费者仍能通过本地缓存通讯
- 服务提供者无状态,任意一台宕掉后,不影响使用
- 服务提供者全部宕掉后,服务消费者应用将无法使用,并无限次重连等待服务提供者恢复
高可用:通过设计,减少系统不能提供服务的时间;
直连dubbo:因为我们知道zookeeper注册中心保存的信息主要是消息提供者的位置,那么我们消费者可以通过url的方式直接访问消息提供者提供的服务地址也是可以的。

7.2、集群下dubbo负载均衡配置
在集群负载均衡时,Dubbo 提供了多种均衡策略,缺省为 random 随机调用。
负载均衡策略
http://dubbo.apache.org/zh-cn/docs/user/demos/loadbalance.html
1.Random LoadBalance
随机,按权重设置随机概率。
在一个截面上碰撞的概率高,但调用量越大分布越均匀,而且按概率使用权重后也比较均匀,有利于动态调整提供者权重。
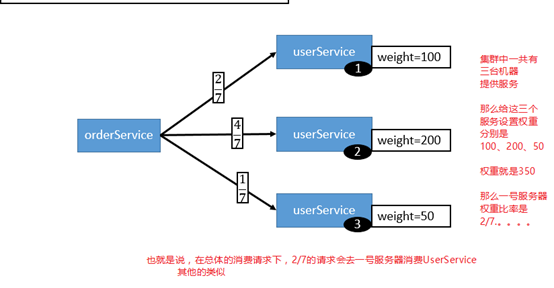
可以在Dubbo-admin设置某个服务的权重

2.RoundRobin LoadBalance
轮循,按公约后的权重设置轮循比率。
存在慢的提供者累积请求的问题,比如:第二台机器很慢,但没挂,当请求调到第二台时就卡在那,久而久之,所有请求都卡在调到第二台上。
3.LeastActive LoadBalance
最少活跃调用数,相同活跃数的随机,活跃数指调用前后计数差。
使慢的提供者收到更少请求,因为越慢的提供者的调用前后计数差会越大。
在消费服务的时候,总是查询上一个服务处理请求处理最快的那一台服务器
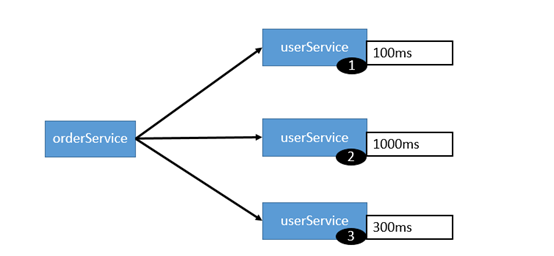
很明显请求会发到一号服务器,因为他处理最快。每次都记录请求处理的时间。
4.ConsistentHash LoadBalance
一致性 Hash,相同参数的请求总是发到同一提供者。
当某一台提供者挂时,原本发往该提供者的请求,基于虚拟节点,平摊到其它提供者,不会引起剧烈变动。算法参见:http://en.wikipedia.org/wiki/Consistent\_hashing
缺省只对第一个参数 Hash,如果要修改,请配置 \
缺省用 160 份虚拟节点,如果要修改,请配置 \
7.3、整合hystrix,服务熔断与降级处理
1、服务降级
什么是服务降级?
当服务器压力剧增的情况下,根据实际业务情况及流量,对一些服务和页面有策略的不处理或换种简单的方式处理,从而释放服务器资源以保证核心交易正常运作或高效运作。
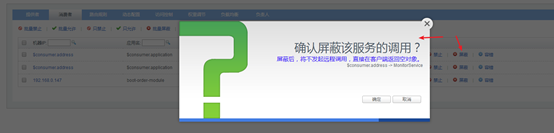
可以通过服务降级功能临时屏蔽某个出错的非关键服务,并定义降级后的返回策略。
向注册中心写入动态配置覆盖规则:
|
其中:
- mock=force:return+null 表示消费方对该服务的方法调用都直接返回 null 值,不发起远程调用。用来屏蔽不重要服务不可用时对调用方的影响。
相当于在dubbo-admin中设置如下:
- 还可以改为 mock=fail:return+null 表示消费方对该服务的方法调用在失败后,再返回 null 值,不抛异常。用来容忍不重要服务不稳定时对调用方的影响。
2、集群容错
[http://dubbo.apache.org/zh-cn/docs/user/demos/fault-tolerent-strategy.html]{.underline}
在集群调用失败时,Dubbo 提供了多种容错方案,缺省为 failover 重试。
集群容错模式
|
3、整合hystrix
Hystrix 旨在通过控制那些访问远程系统、服务和第三方库的节点,从而对延迟和故障提供更强大的容错能力。Hystrix具备拥有回退机制和断路器功能的线程和信号隔离,请求缓存和请求打包,以及监控和配置等功能
1、配置spring-cloud-starter-netflix-hystrix
spring boot官方提供了对hystrix的集成,直接在pom.xml里加入依赖:
|
然后在Application类上增加\@EnableHystrix来启用hystrix starter:
|
2、配置Provider端
在Dubbo的Provider上增加\@HystrixCommand配置,这样子调用就会经过Hystrix代理。
|
3、配置Consumer端
对于Consumer端,则可以增加一层method调用,并在method上配置@HystrixCommand。当调用出错时,会走到fallbackMethod = \”reliable\”的调用里。
|
八、Dubbo原理
1、RPC原理
|
2、netty通信原理
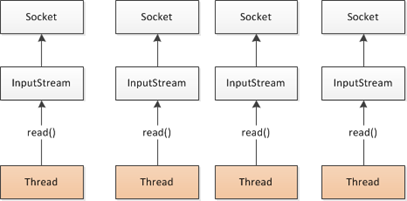
Netty是一个异步事件驱动的网络应用程序框架, 用于快速开发可维护的高性能协议服务器和客户端。它极大地简化并简化了TCP和UDP套接字服务器等网络编程。
BIO:(Blocking IO)
NIO (Non-Blocking IO)
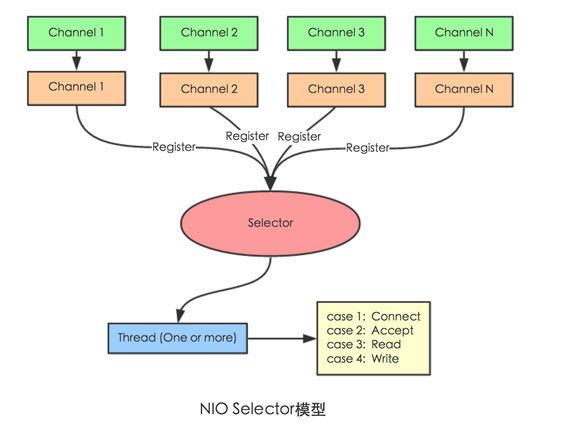
Selector 一般称 为选择器 ,也可以翻译为 多路复用器,
Connect(连接就绪)、Accept(接受就绪)、Read(读就绪)、Write(写就绪)
Netty基本原理:
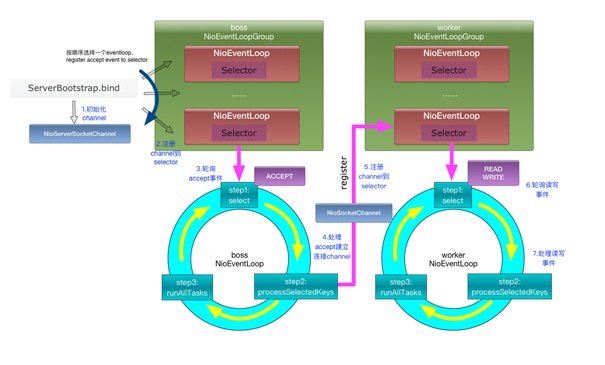
3、dubbo原理
1、dubbo原理 -框架设计
[http://dubbo.apache.org/zh-cn/docs/dev/design.html]{.underline}
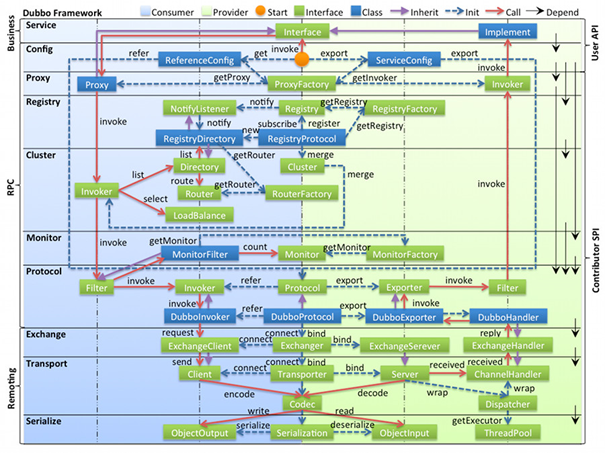
- config 配置层:对外配置接口,以 ServiceConfig, ReferenceConfig 为中心,可以直接初始化配置类,也可以通过 spring 解析配置生成配置类
- proxy 服务代理层:服务接口透明代理,生成服务的客户端 Stub 和服务器端 Skeleton, 以 ServiceProxy 为中心,扩展接口为 ProxyFactory
- registry 注册中心层:封装服务地址的注册与发现,以服务 URL 为中心,扩展接口为 RegistryFactory, Registry, RegistryService
- cluster 路由层:封装多个提供者的路由及负载均衡,并桥接注册中心,以 Invoker 为中心,扩展接口为 Cluster, Directory, Router, LoadBalance
- monitor 监控层:RPC 调用次数和调用时间监控,以 Statistics 为中心,扩展接口为 MonitorFactory, Monitor, MonitorService
- protocol 远程调用层:封装 RPC 调用,以 Invocation, Result 为中心,扩展接口为 Protocol, Invoker, Exporter
- exchange 信息交换层:封装请求响应模式,同步转异步,以 Request, Response 为中心,扩展接口为 Exchanger, ExchangeChannel, ExchangeClient, ExchangeServer
- transport 网络传输层:抽象 mina 和 netty 为统一接口,以 Message 为中心,扩展接口为 Channel, Transporter, Client, Server, Codec
- serialize 数据序列化层:可复用的一些工具,扩展接口为 Serialization, ObjectInput, ObjectOutput, ThreadPool
2、dubbo原理 -启动解析、加载配置信息
我们知道spring加载配置文件,是通过BeanDefinitionparser这个接口的实现类进行绑定的
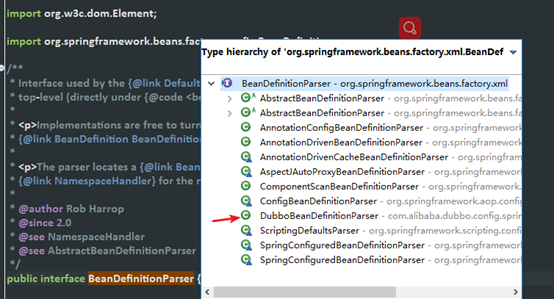
调用parse方法,解析标签
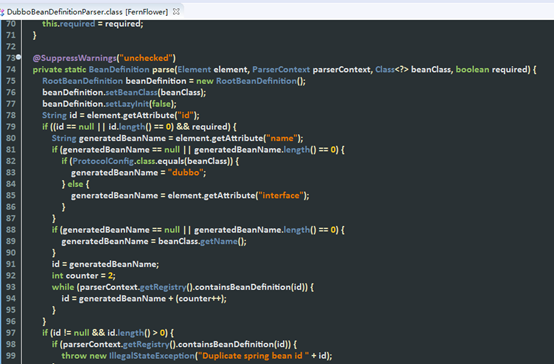
根据xml文件的每一行进行处理解析
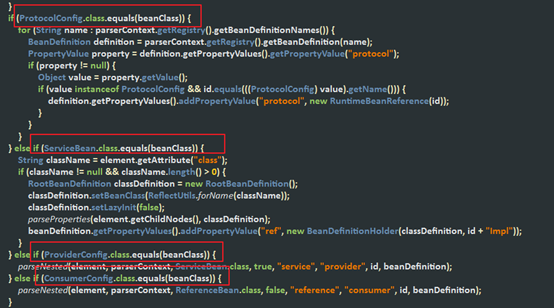
不同的标签处理逻辑是不一样的
那么每一个标签对应的类是哪一个。这个是哪里定义的呢?
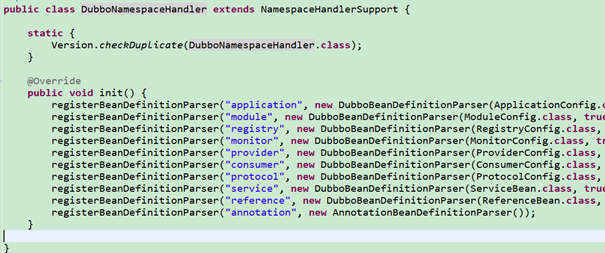
通过DubboNamespaceHandler来定义标签对应的解析类
3、dubbo原理 -服务暴露
通过上面的配置文件解析,我们知道服务相关的信息是通过解析后存放在ServiceBean中
|
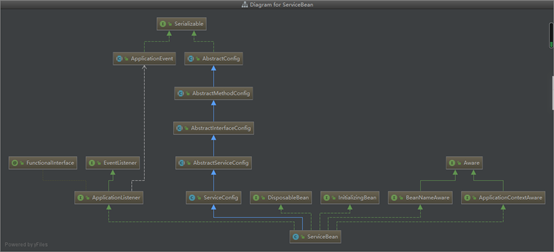
关键的两个接口
InitializingBean Spring的接口,当组件创建完对象之后, 组件属性设置完成,会调用InitializingBean中的afterPropertiesSet方法
ApplicationListener应用监听器 监听IOC容器的刷新事件.当IOC容器中,所有对象都创建完成会回调onApplicationEvent方法
设置了延迟暴露,dubbo在Spring实例化bean(initializeBean)的时候会对实现了InitializingBean的类进行回调,回调方法是afterPropertySet()
没有设置延迟或者延迟为-1,dubbo会在Spring实例化完bean之后,在刷新容器最后一步发布ContextRefreshEvent事件的时候,通知实现了ApplicationListener的类进行回调onApplicationEvent

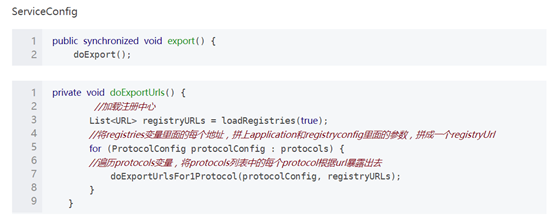


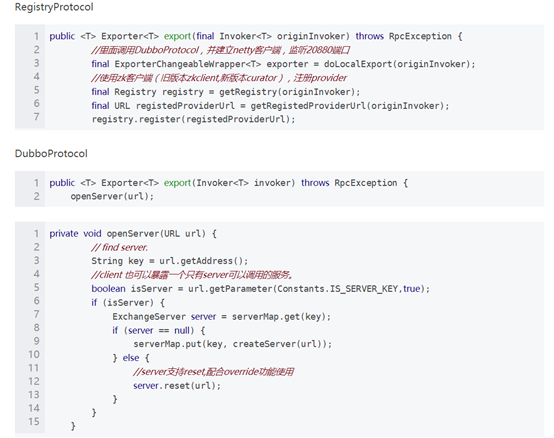

总的调用接口如下:
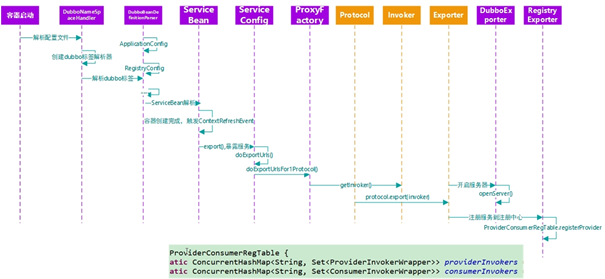
4、dubbo原理 -服务引用

5、dubbo原理 -服务调用