编写king-spring的目的
旨在能够了解spring整个架构核心的脉络,从而更好的理解spring的架构精神和底层原理
A tiny IoC container refer to Spring
king-spring的结构逻辑
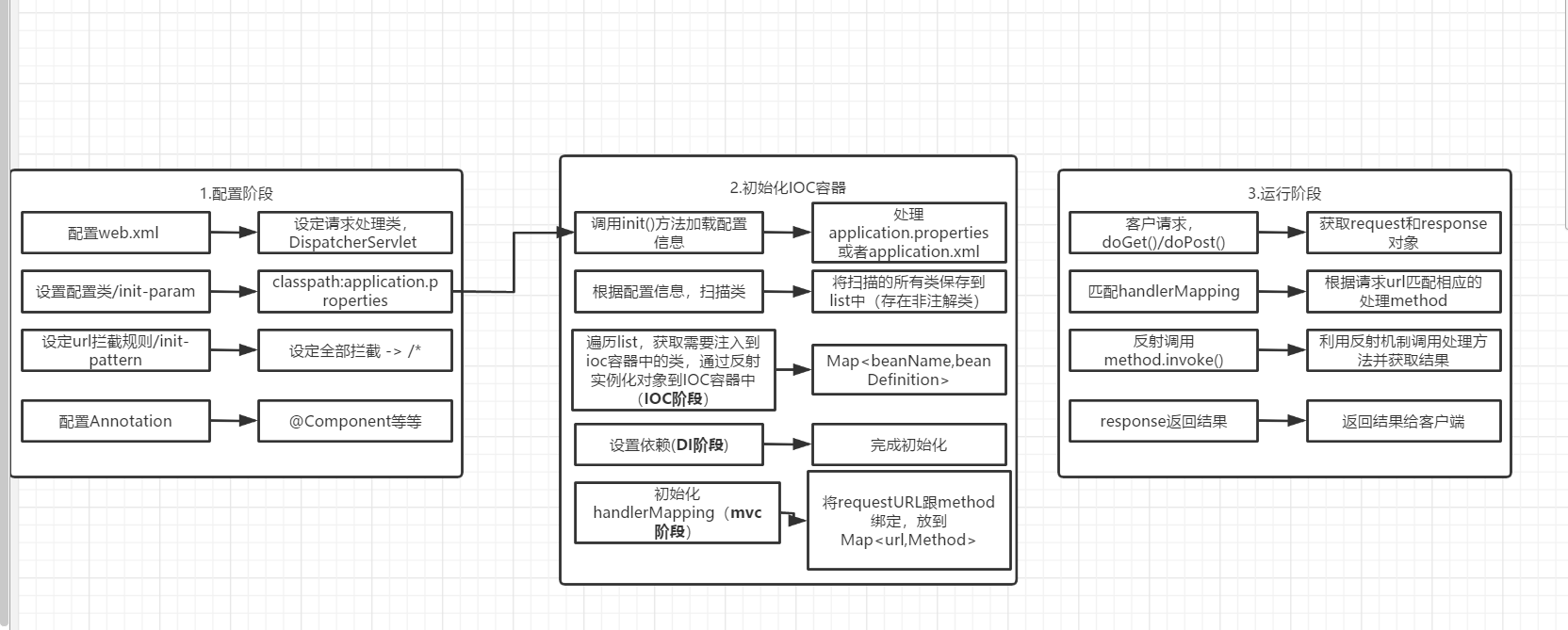
可以看到整个spring的简化版逻辑就是这样子的,核心就是IOC/DI,MVC。
那么我们接下来就模拟spring实现我们的king-spring
代码实现
配置阶段-做准备工作
配置web.xml和配置控制类 - KDispatcherServlet
创建web请求控制类 - KDispatcherServlet
配置到web.xml中
|
配置application.properties
这里采用的是properties的方式进行spring项目的配置(后期可以能会扩展成xml方式)
|
目前就配置一项,项目扫描根目录
实现扫描注解
我们应该知道,spring是通过校验某个bean是否加了特定的注解,从而决定是否加入到IOC容器中,也即是:bean的生命周期管理是否托管给spring。
常用的注解有这几个:@Component、@Service、@Controller、@Repository,后三个实际上都是基于Component的实现,所以他们的效果等同@Component,但是后三个出现的目的是为了标识业务层次,所以在使用过程中,我们最好是按照不同的业务层次使用不同的注解,而且在spring官网上提到,后面这三个注解在以后可能还会赋予其他的含义。
逐层分为两个层次(包):
业务层和web控制层
总结
做完这一步,我们基本把king-spring的整体架构搭建出来了,而且某些注解类和控制类也已经建立,但是某些细节实现还是没有完成,例如KDispatcherServlet内部还没有实现。
接下来就实现,具体的解析配置信息(application.properties)
初始化IOC容器-解析配置类
首先我们把这段代码逻辑是声明在了KDispatcherServlet的init方法中,也即是项目启动过程中就会去执行
这个过程分为四步
根据web.xml配置的contextConfigLocation解析配置类
|
根据配置类获取扫描包的路径
|
需要注意的是,扫描到的类,可能存在某些类需要过滤掉,并不是都需要加到IOC容器中,判断是否加入IOC容器中的依据是:是否被我们上面定义的注解所修饰
解析需要注入到ioc容器中的bean
|
解决IOC容器中bean 的依赖问题
也就是DI依赖注入阶段
|
控制层的url绑定处理方法
实际上就是处理IOC容器中被@KController注解修饰的类,然后再根据@KRequestMapping获取映射的url,然后再绑定url对应的处理方法。
|
处理请求
实际上就是根据请求的url,然后从上面的handlerMapping中,获取url对应的处理方法,然后执行,返回结果。
|
总结
IOC容器在上面我们是使用private Map<String,Object> beanDefinitionMap = new ConcurrentHashMap<String,Object>(256); key是beanName(默认是类名首字母小写),value是bean的实例
url映射关系我们使用的是handlerMapping,他的类型是:private Map<String,Method> handlerMapping = new ConcurrentHashMap<String,Method>(); key就是请求url,value就是url映射的method
自我实现的king-spring 使用了那些设计模式
模板模式:init方法,把初始化分为了多个步骤,每个步骤自己实现自己的逻辑
策略模式:根据注解类型选择不同的操作方式。
委托模式:doGet()、doPost().
单例模式:Constants类
项目地址
|
回过头来查看spring源码
spring的ioc容器怎么实现的呢?跟我们自己的实现有何不同
通过查看我们发现,spring在启动时,假设是注解版本那么,使用的context是
|
最后跟踪到,DefaultListableBeanFactory的registerBeanDefinition()方法,最后调用了this.beanDefinitionMap.put(beanName, beanDefinition);
也就是说BeanDefinitionMap就是我们需要查找的IOC容器
|
可以看到,他的key跟我们的定义的一样,也是通过beanName方式,但是value跟我们却不同。
BeanDefinition
他实际上就是spring对于注解的描述类。我们还记不记得,在使用@Service这样的注解时,我们是可以配置作用域,生命周期,是否懒加载等等信息。那么这些信息就是保存在BeanDefinition中。
换句话说,spring的BeanDefinition实现,更加全面,而且更加面对对对象。 我们上面的做法是直接把实例化的bean当做value,那么这样势必会造成内存的浪费。
spring的handlermapping是怎么实现的呢?
那么这个属性的定义肯定是在DispatcherServlet中的。
|
可以看到spring他的实现,是一个list,值得类型是HandlerMapping,在handlerMapping维护URl跟method 的映射关系。
我们的实现是map数据结构,key是url,value是url映射的method
那为什么不用我们的map结构呢?map架构取数据不是更加清晰么?
我觉得spring应该是考虑到冗余原则,因为如果用map方式,那么key的值就只能是url。为了保证能够获取更多的信息,那么就封装成对象,然后使用list保存 - 满足单一原则,就是我所有信息都可以用一个对象保存,干嘛还要分开成key-value的形式呢?。其实我觉得map也很不错,选择不同而已
那为什么不用map
目前存在的缺点
1.在doDispatcher方法中,调用处理方法时,请求参数的拼接是静态写死的,后期需要修改成动态拼接
思考题
spring中的bean是线程安全的么?
首先,我们要知道,spring的bean是在spring启动时,通过反射实例化出来,然后放到IOC容器中的,也就是说spring中的bean只是帮你管理而已,并没有做什么增强或者修改工作。
也就是说,bean的是不是线程安全的,那么取决于你对于bean的实现,跟spring没有任何关系。
所以这个思考题的答案是:spring中的bean是否线程安全,是这个bean的问题,如果你在bean中有操作共享资源的操作,那么就有线程安全的问题,如果没有那么就是跟线程安全的。所以bean是否是线程安全的取决于bean自身的实现,而不是spring的问题。
虽然IOC容器是基于chm实现的。 应该说,spring存取bean的操作是线程安全的。这样的因为会比较好点。
spring中的bean什么时候被回收
这个跟bean的生命周期 有关系,spring的bean生命周期有:singleton、prototype、request、session。
所以什么时候被回收,取决于,你设定的生命周期类型

