常用压测工具比对
1、loadrunner
性能稳定,压测结果及细粒度大,可以自定义脚本进行压测,但是太过于重大,功能比较繁多
2、apache ab(单接口压测最方便)
模拟多线程并发请求,ab命令对发出负载的计算机要求很低,既不会占用很多CPU,也不会占用太多的内存,但却会给目标服务器造成巨大的负载, 简单DDOS攻击等
3、webbench
webbench首先fork出多个子进程,每个子进程都循环做web访问测试。子进程把访问的结果通过pipe告诉父进程,父进程做最终的统计结果。
Jmeter介绍和安装
Jmeter基本介绍和使用场景
压测不同的协议和应用
1) Web - HTTP, HTTPS (Java, NodeJS, PHP, ASP.NET, …)
2) SOAP / REST Webservices
3) FTP
4) Database via JDBC
5) LDAP 轻量目录访问协议
6) Message-oriented middleware (MOM) via JMS
7) Mail - SMTP(S), POP3(S) and IMAP(S)
8) TCP等等
使用场景及优点
1)功能测试
2)压力测试
3)分布式压力测试
4)纯java开发
5)上手容易,高性能
4)提供测试数据分析
5)各种报表数据图形展示
Jmeter4.0安装
简介:GUI图形界面的安装
1、需要安装JDK8。或者JDK9,JDK10
2、快速下载
windows: http://mirrors.tuna.tsinghua.edu.cn/apache//jmeter/binaries/apache-jmeter-4.0.zip
mac或者linux:http://mirrors.tuna.tsinghua.edu.cn/apache//jmeter/binaries/apache-jmeter-4.0.tgz
3、文档地址:http://jmeter.apache.org/usermanual/get-started.html
4、建议安装JDK环境,虽然JRE也可以,但是压测https需要JDK里面的 keytool工具
下载完成解压后
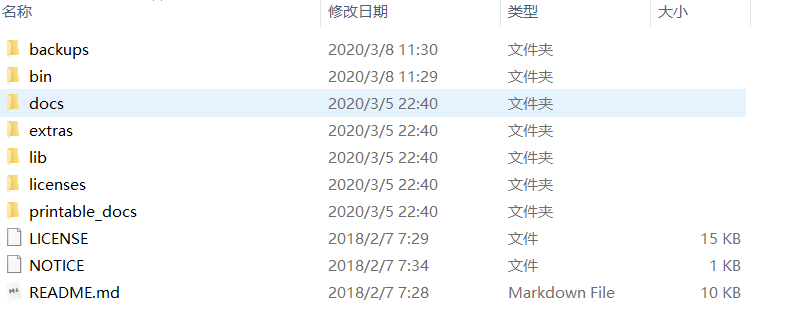
目录
bin:核心可执行文件,包含配置
jmeter.bat: windows启动文件:也就是说,在windows平台下,直接双击这个bat文件,即可启动jmeter。
jmeter: mac或者linux启动文件:
jmeter-server:mac或者Liunx分布式压测使用的启动文件
jmeter-server.bat:mac或者Liunx分布式压测使用的启动文件
jmeter.properties: 核心配置文件,例如可以设置GUI界面的语言(中文还是英文)
extras:插件拓展的包
lib:核心的依赖包
ext:核心包
junit:单元测试包
Jmeter语言版本中英文切换
1、控制台修改
menu -> options -> choose language
2、配置文件修改
bin目录 -> jmeter.properties
默认 #language=en
改为 language=zh_CN
Jmeter使用
首先我们双击jmeter.bat 启动jmeter:
创建线程组
右键TestPlan,开始创建测试计划,首先创建线程组,作用是控制总体并发
接着看测试组的界面设置
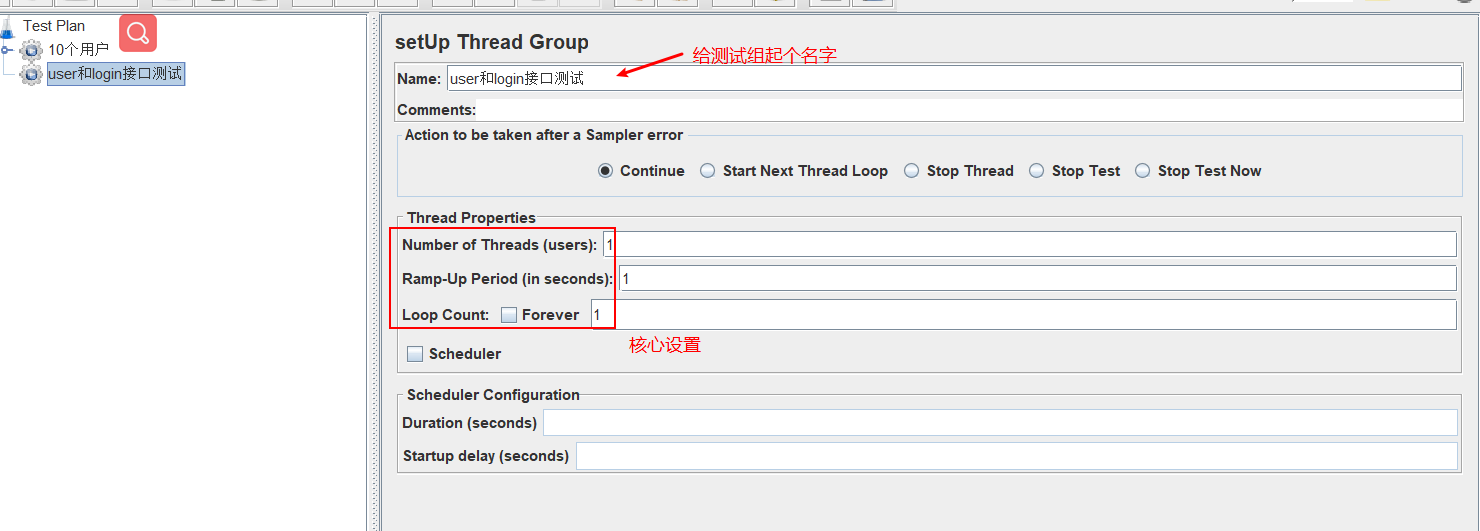
这里主要介绍着三个重要的设置:
线程数:虚拟用户数。一个虚拟用户占用一个进程或线程,也就是说,你想模拟100个人访问接口,那么这里就填100。
准备时长(Ramp-Up Period(in seconds)):全部线程启动的时长,比如100个线程,20秒,则表示20秒内100个线程都要启动完成,每秒启动5个线程。也就是说,这个参数模拟的是,用户访问数量的逐渐上涨,随着时间的增加,慢慢增长到设置的“线程数”。因为在真实的环境中,访问某个接口的用户量是慢慢上涨的,一般不会是1s内暴增很多个 用户。 - 总而言之,就是在这个时间过后达到上面设置的线程数。
循环次数:每个线程发送的次数,假如值为5,100个线程,则会发送500次请求,可以勾选永远循环,那么就会一直重复发送请求。
我这里为这三个参数自上而下设置的是:10、5、1。 表示,一共模拟十个用户请求,5s内发送这十个请求,也就意味着每两秒请求两次接口,第五秒后请求结束。1表示,这进行一轮测试,也就是发送完10个请求后便停止请求。
那么如果你想模拟,每秒并发1000,持续发送5次,那么就需要由上到下设置为:1000/1/5。
创建采样器 - 模拟请求
我们在上面通过线程组创建了请求的频率和请求的用户数等设置,那么我们怎么开始发送请求呢?那么这个时候就需要采样器。
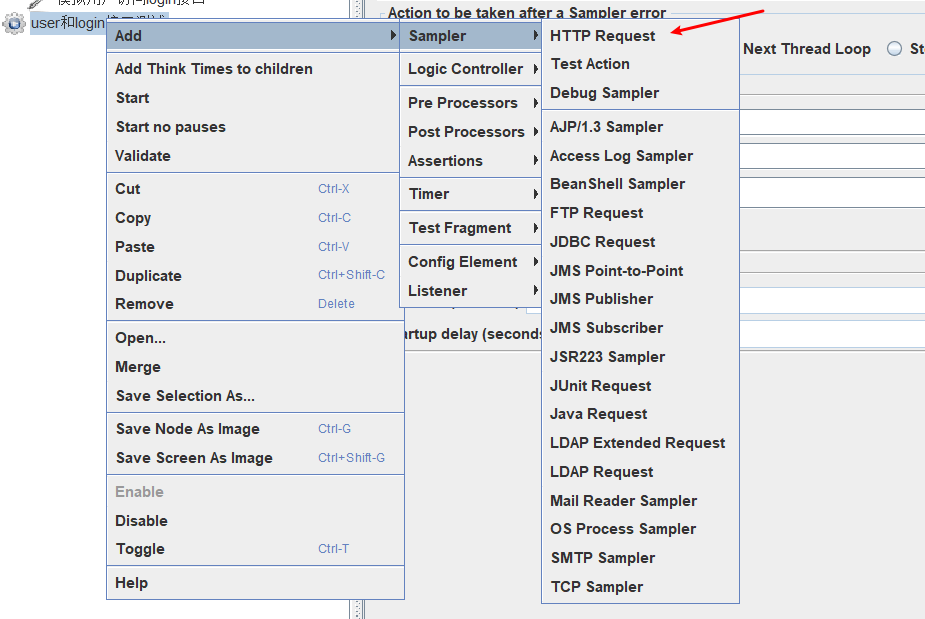
可以看到,你可以在线程组下面创建多种类型的请求采样器。我这里创建的是http请求采样器。
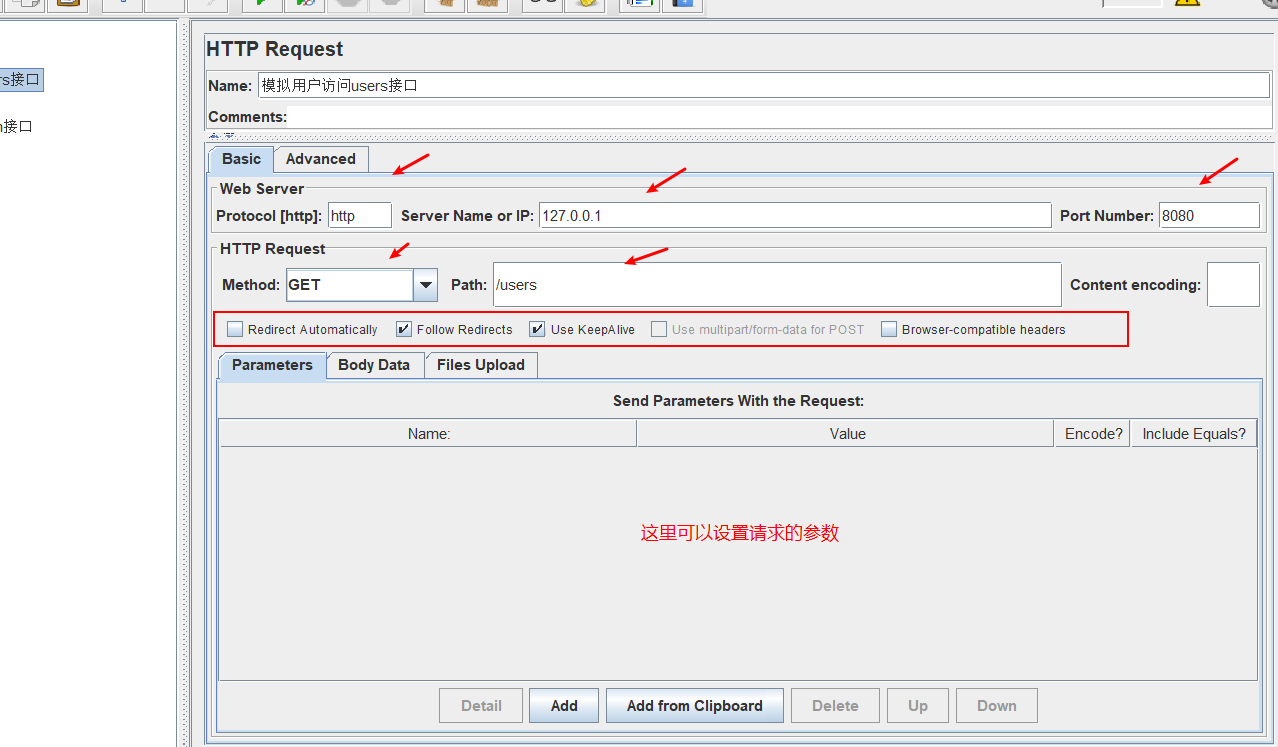
设置完成后,我们就可以,点击上面的启动按钮,这样就可以发送请求,可以看到,请求后台的接口,每两秒打印两次输出,一共打印了五次,一共是10个请求(因为线程组设置10个请求5s内发完,只进行一轮请求)
看到这里我们,可能会有疑问,那就是,我怎么看请求返回的值或者请求的状态呢?能不能跟踪请求呢?
创建结果收集树 - 查看测试结果
我们可以右键线程组,然后创建一个结果收集器。
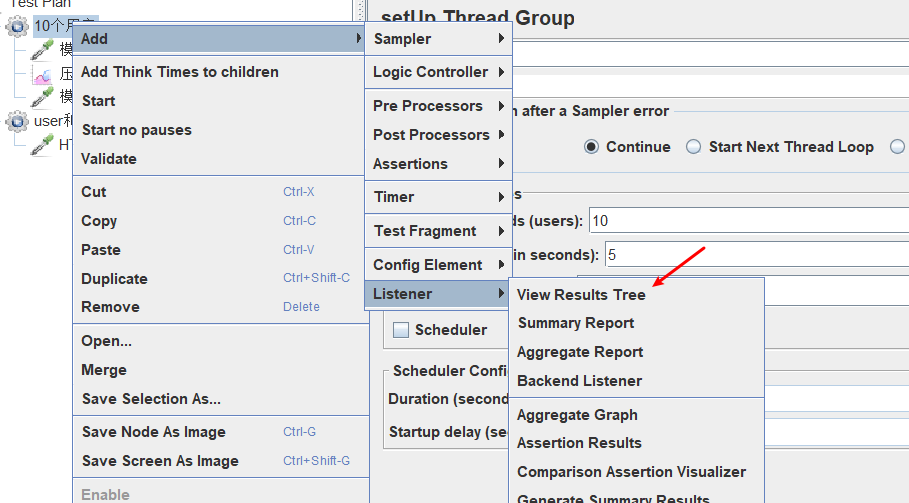
启动采样器发出请求后,查看结果收集树。
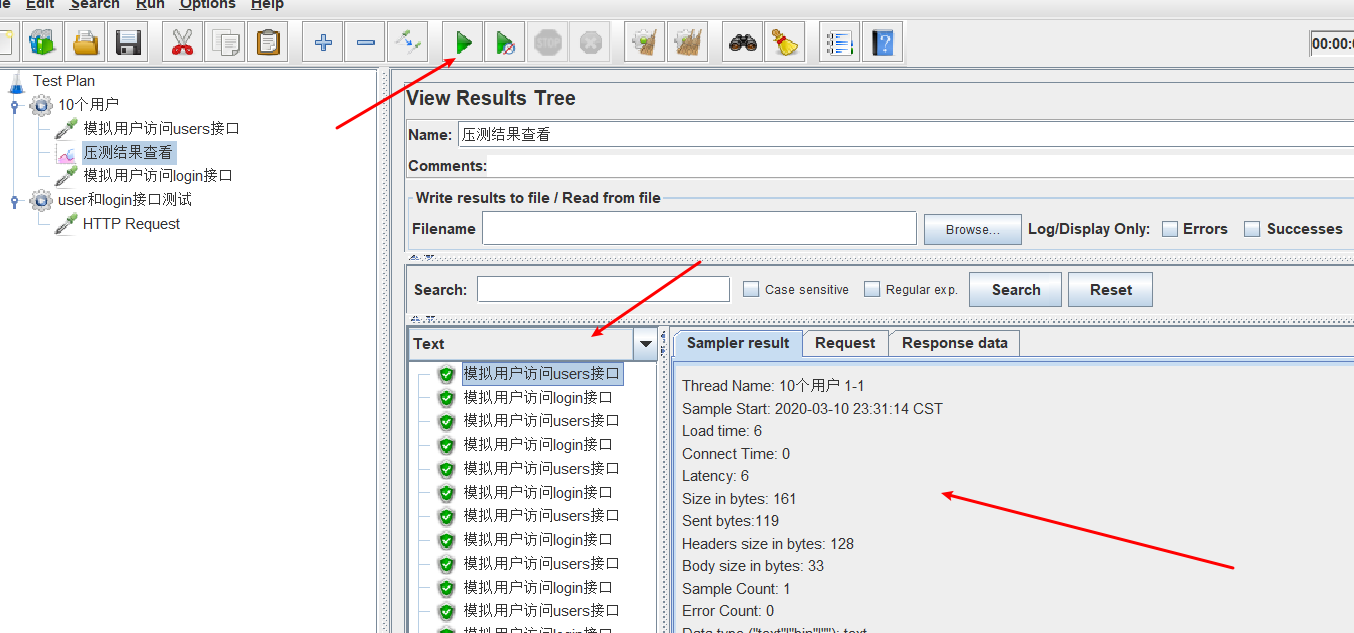
可以看到在线程组下面每个请求的详细信息包括返回值。
上面的结果树是在线程组上面进行添加,也就意味着,线程组下面多个采样器,那么他们都将使用同一个结果数查看(可以看到上面结果树输出了users、login接口两个的请求信息),当然你也可以专门为某一个接口创建单独的结果树(右键采样器,创建即可)
模拟一次性请求多个接口
上面的演示,我们是在线程组下面只创建了一个 采样器。实际上我们可以在线程组下面创建多个采样器。那么这样就意味着,多个接口同时遵循线程组的设置信息。
例如:

如图,创建了两个采样器,那么当启动线程组的时候,是会同时请求这两个接口的,这样就可以模拟在某一秒的时候,同时去请求多个接口,这种业务场景在现实中也是很常见的。
上面线程组设置是:10、5、1。启动线程组,查看结果收集树:

可以看到,确实是两个采样器使用了通个线程组的配置。1s内发送了两个请求,访问了users接口和login接口。然后一共发送5s,users和login接口各自请求了10次,只进行一轮请求。
Jmeter的断言
他的作用就是,结合采样器使用。通过自定义一些判断依据,判断请求接口是否成功,是否达到我们想要的结果。例如我们可以增加一个判断响应状态是202的断言,只有当请求接口相应状态码是202,那么就说明请求成功,否则可以自定义一些错误信息。
响应断言
增加断言: 线程组 -> 添加 -> 断言 -> 响应断言

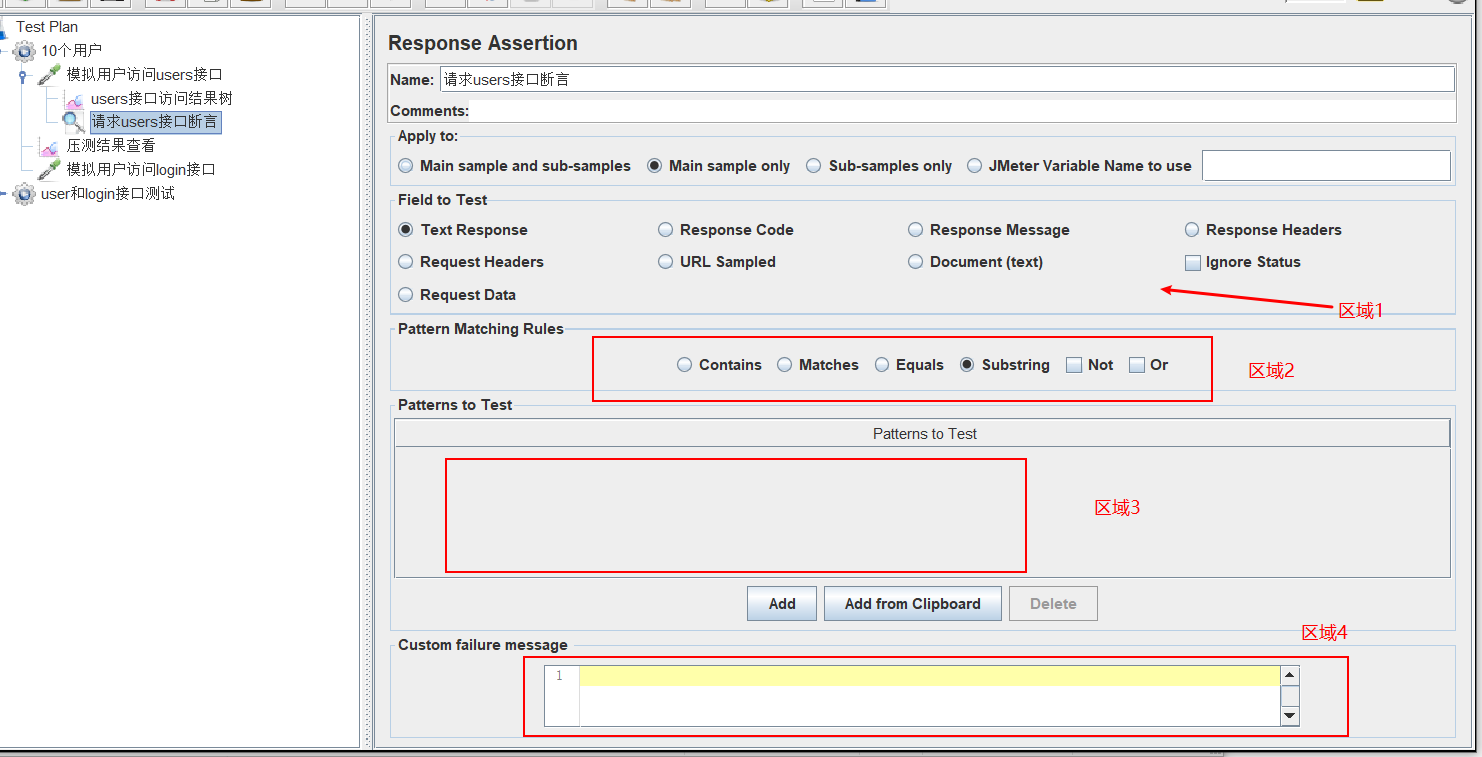
apply to(应用范围):
Main sample only: 仅当前父取样器 进行断言,一般一个请求,如果发一个请求会触发多个,则就有sub sample(比较少用)
要测试的响应字段:也就是区域1的内容
响应文本:即响应的数据,比如json等文本
响应代码:http的响应状态码,比如200,302,404这些
响应信息:http响应代码对应的响应信息,例如:OK, Found
Response Header: 响应头
模式匹配规则:也就是区域2的内容
包括:包含在里面就成功
匹配:响应内容完全匹配,不区分大小写
equals:完全匹配,区分大小写
Substring:判断子串
匹配值:也就是区域3的内容
根据匹配规则,设定值
自定义匹配失败信息:也就是区域4的内容
当匹配失败的时候,返回的错误说明。
例子:
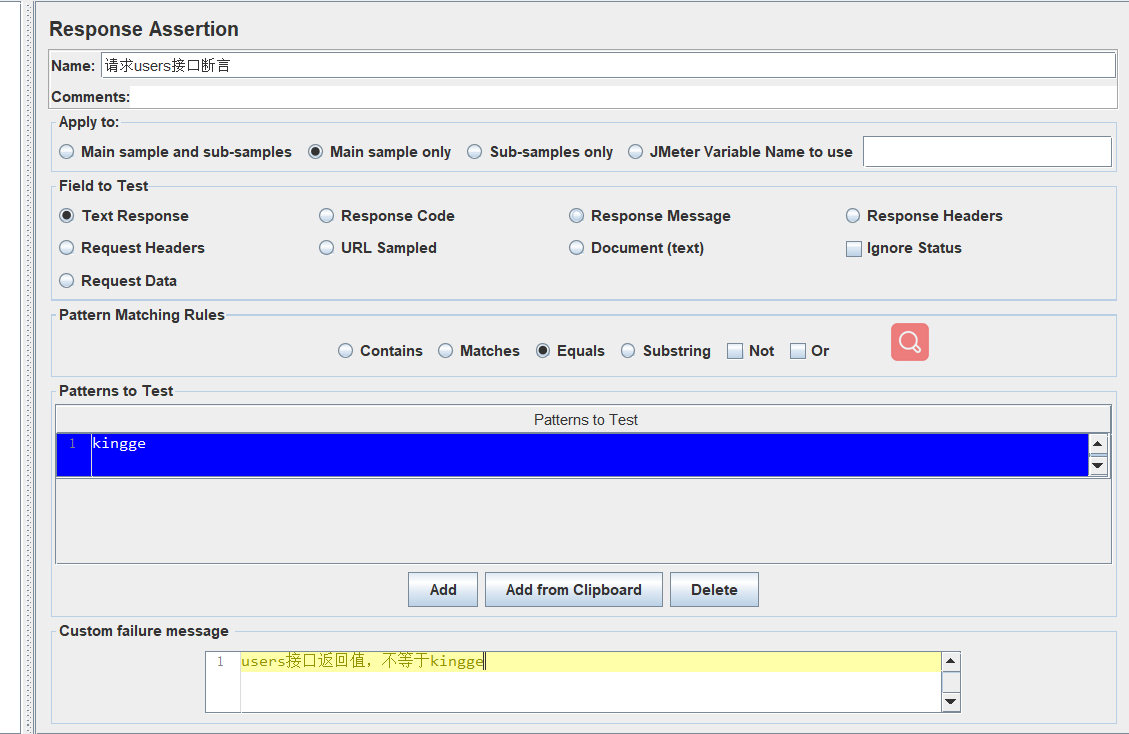
我们根据接口相应数据,进行判断。当响应数据等于kingge的时候,请求成功,否则请求失败,提示下面的错误信息“users接口返回值,不等于kingge”
我们知道正常访问users接口的返回值是“laojiang”,当我们启动采样器请求users接口,肯定是断言失败的。
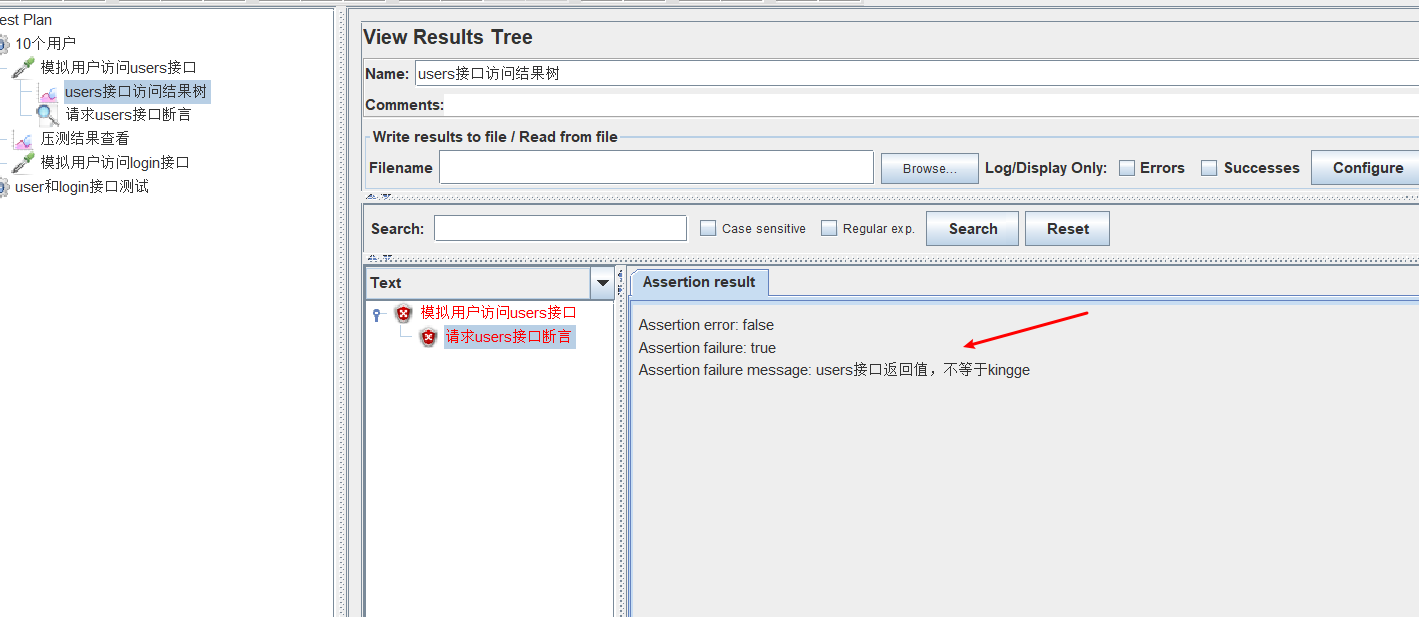
断言失败,查看结果树任务结果颜色标红(通过结果数里面双击不通过的记录,可以看到错误信息)
每个sample采样器下面可以加单独的结果树,然后同时加多个断言,最外层可以加个结果树进行汇总,这样的架构是最常用的。
第一部分总结
我们一般进行接口测试,对应在jmeter需要创建一个线程组。一个接口可能调用了多个接口,那么这个时候我们就需要在线程组下面创建多个采样器,同时在线程组下面创建一个多个采样器共同使用的结果树,这样的好处是,可以查看所有采样器的请求结果。,当然我们也可以在线程组下面创建一个或者多个断言,进行某些规则的匹配从而判断采样器请求是否满足我们的需求(需要注意,这个时候线程组下面的所有采样器,统一使用创建的断言)。
我们也可以单独为某个接口采样器创建相应的结果树和断言,这样能够单独查看某个接口的请求情况和单独的断言判断。
Jmeter压测结果聚合报告
新增聚合报告:1. 增加线程组整体的聚合报告,统计线程组下所有的采样器请求数据报告:
线程组->添加->监听器->聚合报告(Aggregate Report)
2.给单个采样器添加聚合报告:
sample采样器->添加->监听器->聚合报告(Aggregate Report)
下面演示的是,给users采样器添加一个聚合报告。
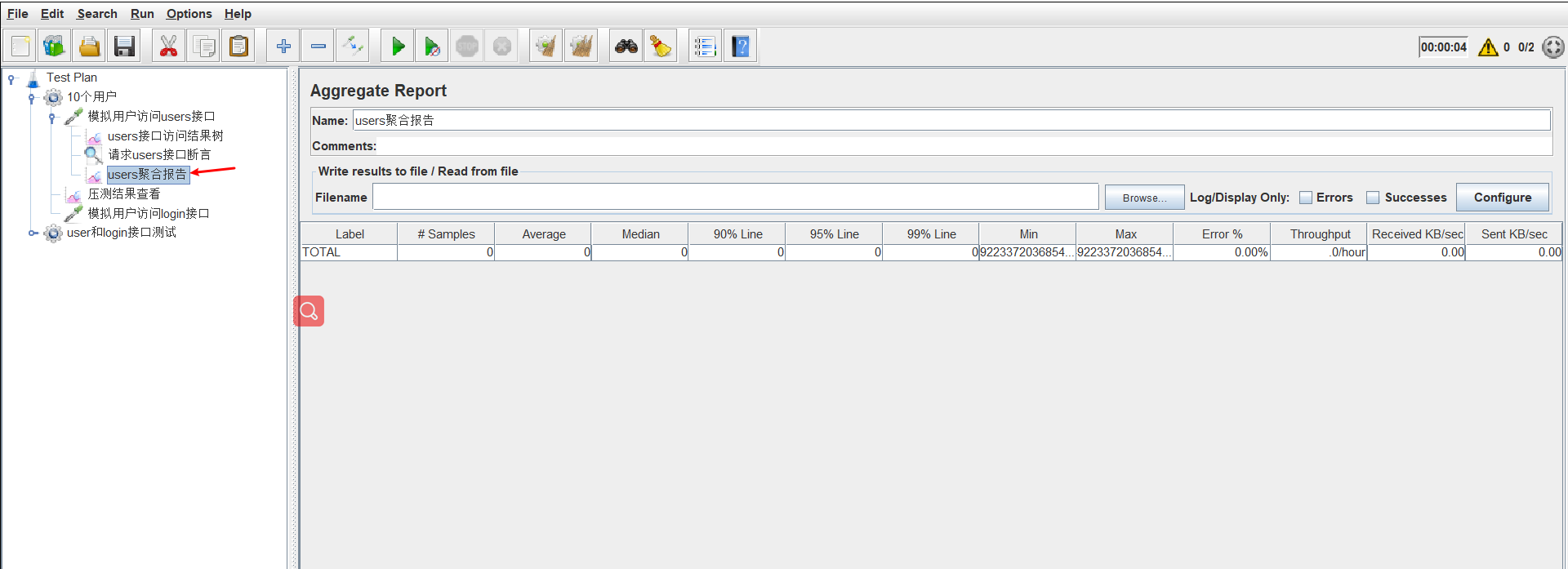
这里我们设置线程组的参数为30/5/2。也就是一共发送两轮请求,每轮发送30个,每轮发送5s,也就是每秒发送5个请求。
启动采样器,查看结果:
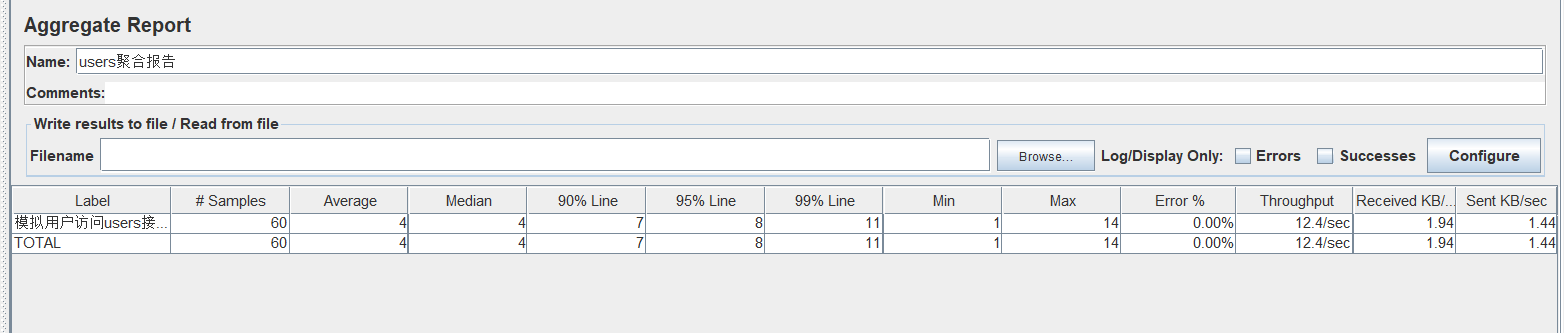
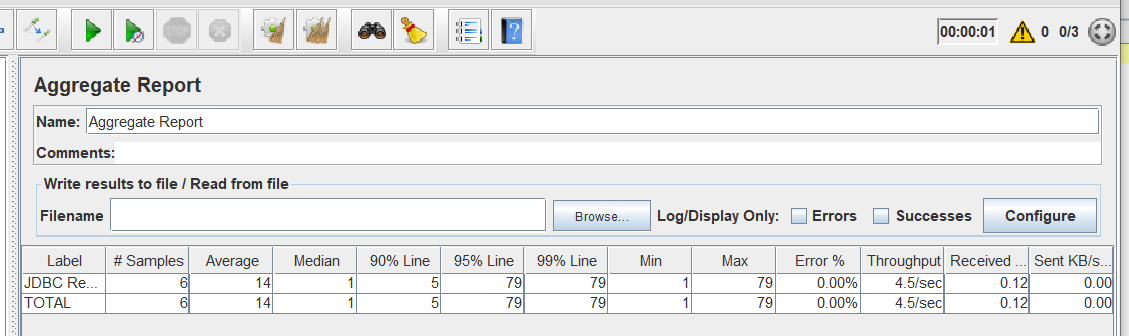
lable: sampler的名称
Samples: 一共发出去多少请求,上面的60个请求
Average: 平均响应时间,4ms
Median: 中位数,也就是 50% 用户的响应时间,4ms
90% Line : 90% 用户的响应不会超过该时间 (90% of the samples took no more than this time. The remaining samples at least as long as this)
95% Line : 95% 用户的响应不会超过该时间
99% Line : 99% 用户的响应不会超过该时间
min : 最小响应时间
max : 最大响应时间
Error%:错误的请求的数量/请求的总数
Throughput: 吞吐量——默认情况下表示每秒完成的请求数(Request per Second) 可类比为qps
KB/Sec: 每秒接收数据量
所以在实际的压测过程中,我们会关注Throughput吞吐量,随着我们通过增加并发数,观察Throughput的值,他的最大值是多少,那么相应的并发数就是最大并发数,再增大并发数,吞吐量反而会下降了。
测试案例
我们进行测试users接口,线程组设置为3000/5/10。
通过逐渐增加并发数,查看吞吐量的瓶颈。
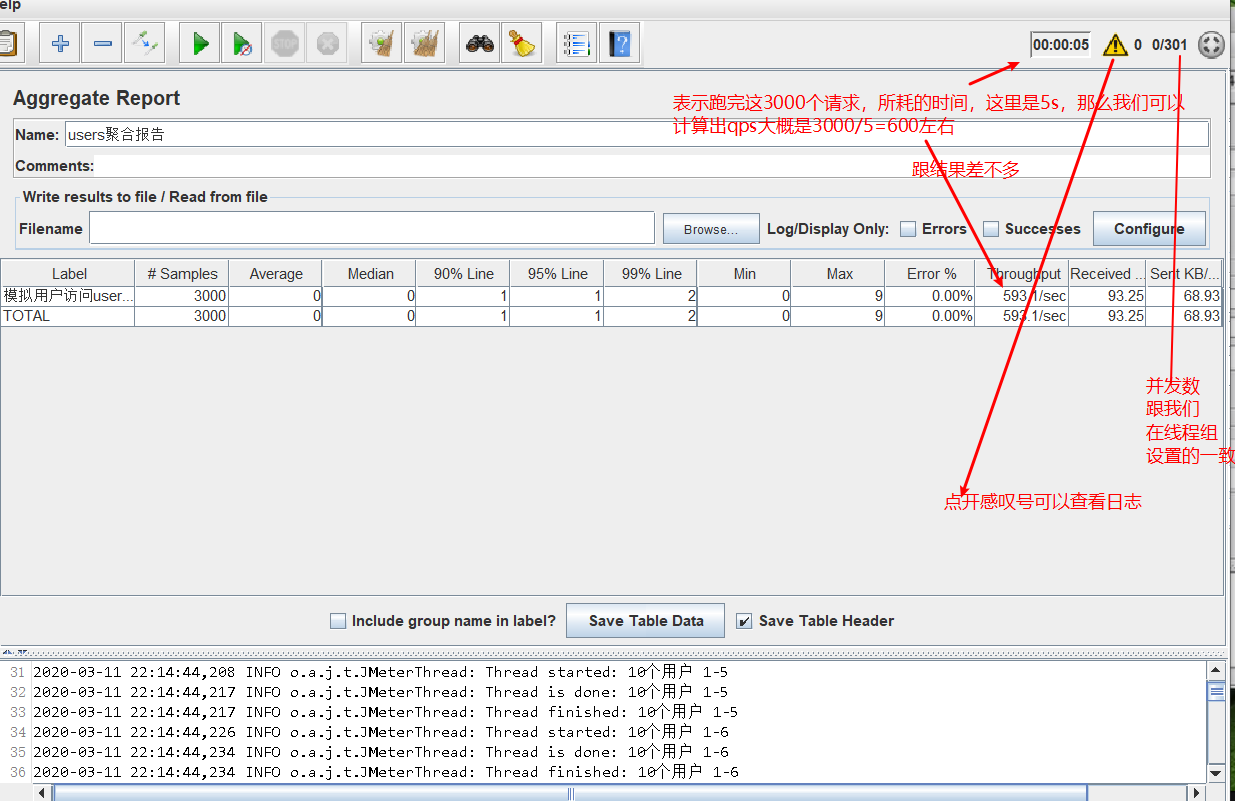
我们发现这个时候每秒可以处理请求是593差不多600。
那么再继续加大并发数,查看qps瓶颈。
线程组设置为6000/5/10。

可以看到qps上涨为1166个,那么说明此时并发数还不是瓶颈。继续加大
线程组设置为15000/5/10。
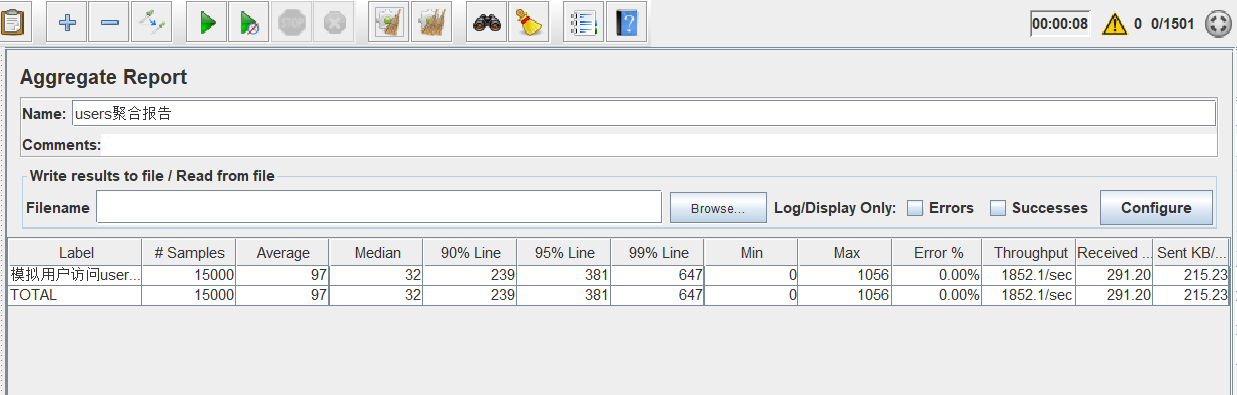
可以看到qps上涨为1852个,那么说明此时并发数还不是瓶颈。继续加大
线程组设置为20000/5/10。
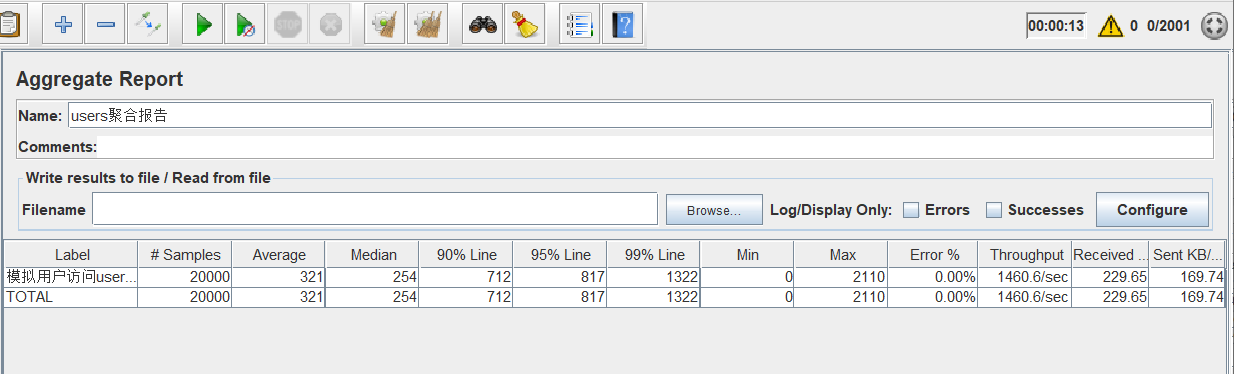
这个时候,我们发现,qps下降了,变成了1460。那么也就意味着当总并发数到达20000个的时候,程序的qps开始下降了,所以说,程序的瓶颈已经出现了,那么我们可以知道线程组设置为1500/5/10。的时候 qps是最高的。
可以通过多次次测试,得到qps最大值。上面是通过增加并发数的方式进行测试,当然了你也可以设置多少s发送这个参数(ramp-up period ),进行压测。
Jmeter压测脚本JMX讲解
我们知道,上面我们设置的测试计划,他最终是保存在一个jmx后缀的文件中的。所以说,后期我们一般是通过直接修改jmx文件的方式,去修改他的并发数等等参数。
打开你会发现他实际上是一个xml文件

自定义变量和CSV可变参数实操
jmeter用户自定义变量
为什么使用:很多变量在全局中都有使用,或者测试数据更改,可以在一处定义,四处使用。比如服务器地址。
例如一个线程组中我们添加了一百多个采样器,那么每个采样器的服务器ip都一样,这个时候我们就可以通过自定义变量的方式,统一使用自定义好的ip变量。这样的好处是,后期如果ip或者端口号需要变动,那么我们只需要修改自定义变量的值即可,不需要单独去修改一百多个采样器的ip和端口号。
1、线程组->add -> Config Element(配置原件)-> User Definde Variable(用户定义的变量)

定义一个自定义变量
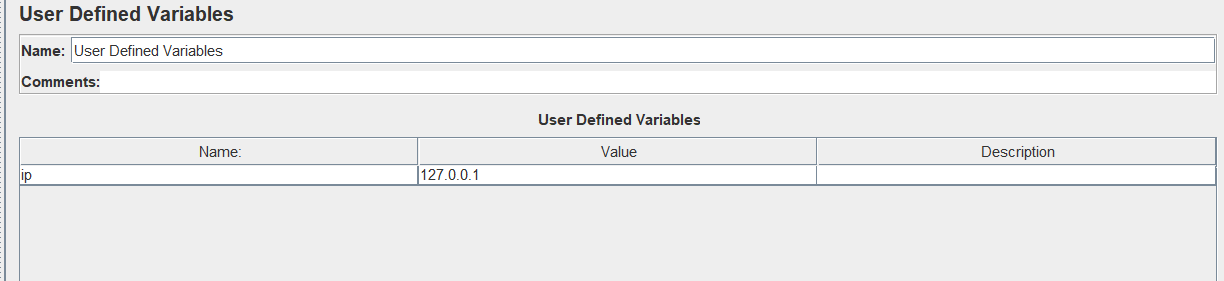
2、引用方式${XXX},在接口中变量中使用

CSV可变参数压测
它的作用就是,模拟请求数据,然后去压测。例如你要压测登录接口,就可以使用这个功能,进行模拟多个用户数据进行传入压测。
实战操作jmeter读取CSV和Txt文本文件里面的参数进行压测
1、线程组->add -> Config Element(配置原件)-> CSV data set config (CSV数据文件设置)
这列可以传入txt文件和csv文件,下面就演示一下txt文件设置可变参数。
1.首先后台定义一个接口,如入参是用户名和密码,模拟详情接口
/**
* 用户自定义变量测试
*/
@RequestMapping(value = "info", method = RequestMethod.GET)
public @ResponseBody Object info(String name, String pwd) {
List<String> userList = new ArrayList<>();
userList.add(name);
userList.add(pwd);
userList.add(name.length()+"");
System.out.println("get request, info api");
return userList;
}
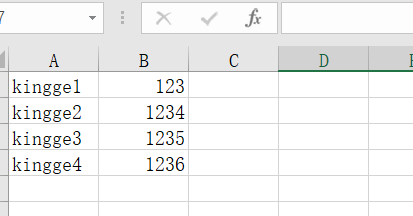
2.创建一个txt文件保存可变参数
内容是如下,使用| 进行分割
|
对应的csv文件是:需要知道,默认的分隔符是,
在线程组下面创建可变参数
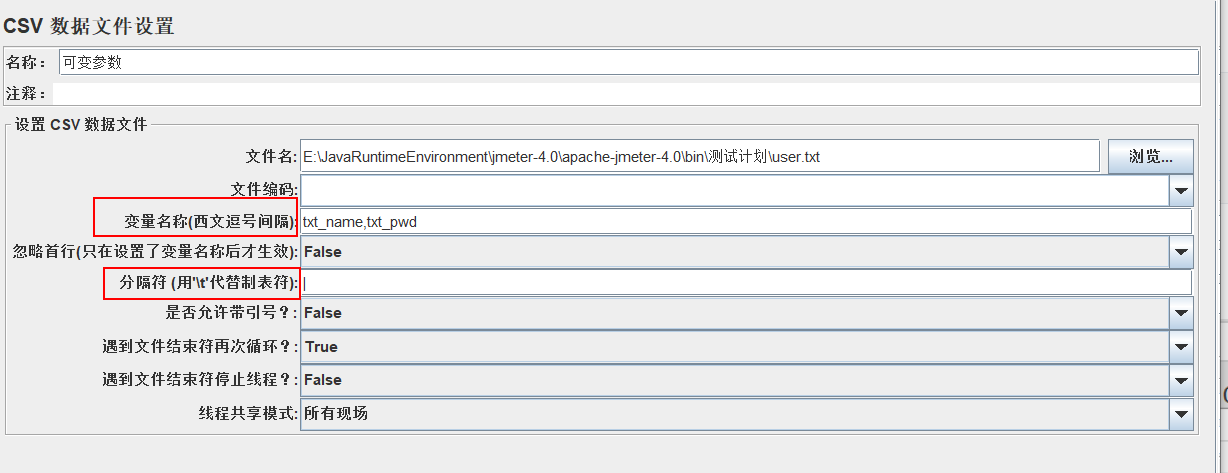
需要注意的是,变量名这里需要配置两个(当然你也可以配置一个),这样才能按照分隔符进行分割后,他们的值对应的变量名才能匹配上。否者采样器就无法使用了。
采样器中引用

通过结果树查看,请求url的参数拼接。
|
Mysql数据库压测实操
这里通过建立JDBC采样器的方式,进行对数据库的直接测试
测试案例1 - 简单查询
新建线程组和JDBC采样器
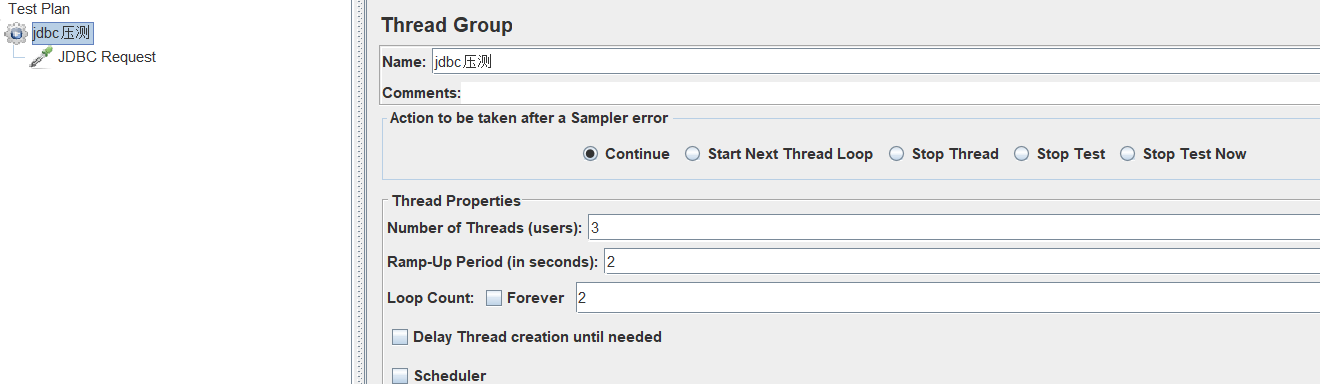
这里的意思是一共执行两轮,一轮3次,一轮3次在两秒内完成。
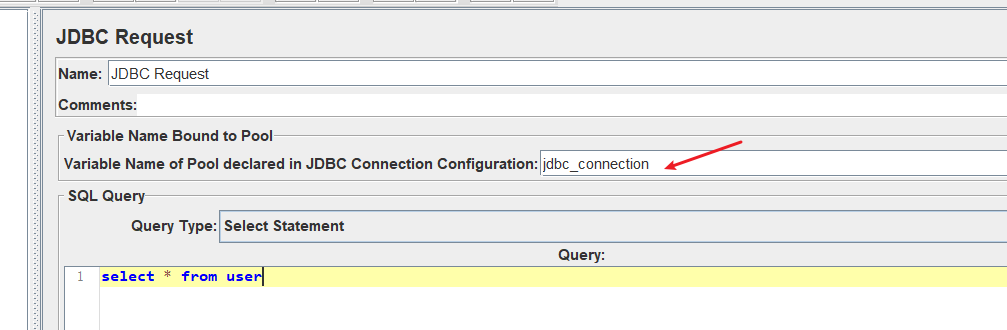
建立jdbc采样器
Thread Group -> add -> sampler -> jdbc request
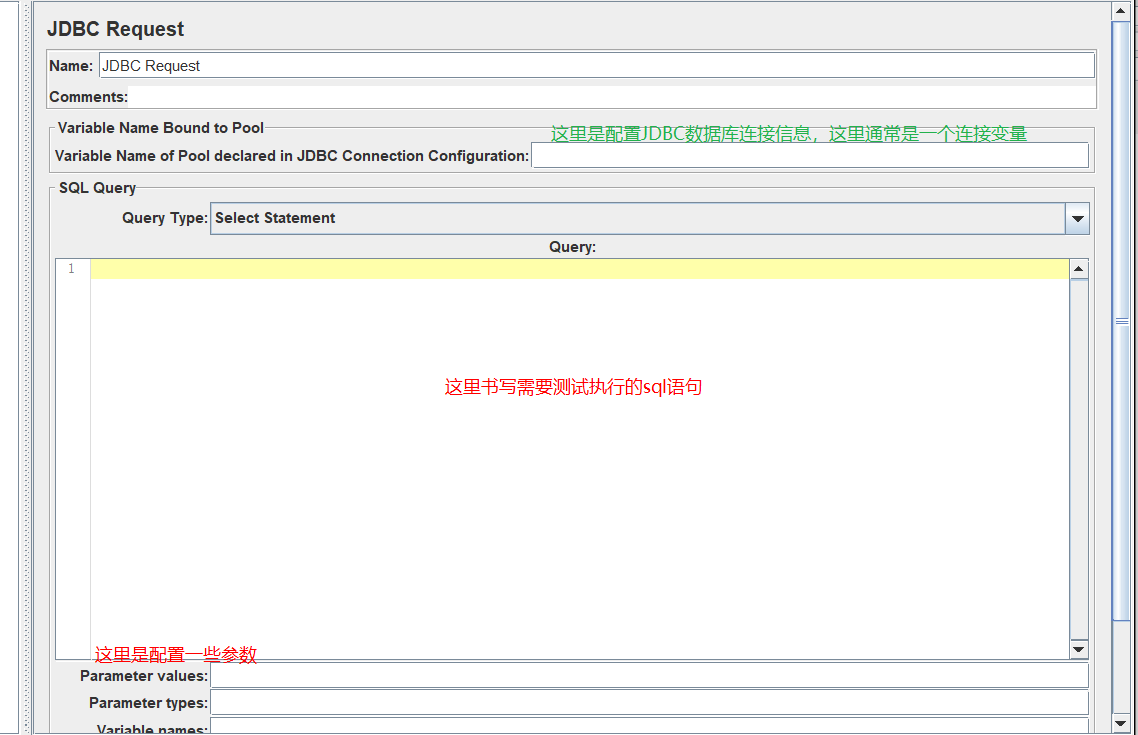
绿色的说明,方框的值,需要先进行下面的《建立JDBC连接配置》后才能给出。
当前界面相关参数的值的含义,查询类型
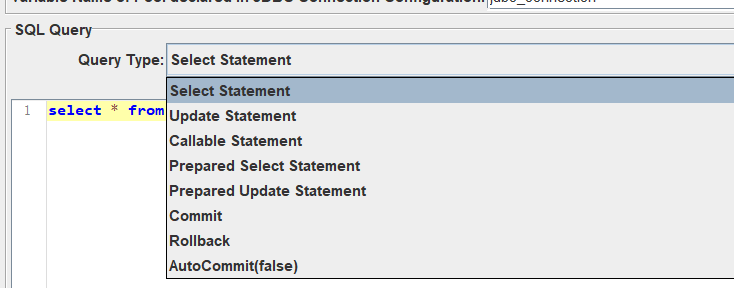
自上而下是:
|
1、variable name of pool declared in JDBC connection configuration(和配置文件同名) 也就是下面的jdbc_connector
3、parameter values 参数值
4、parameter types 参数类型
5、variable names sql执行结果变量名
6、result variable names 所有结果当做一个对象存储
7、query timeouts 查询超时时间
8、 handle results 处理结果集
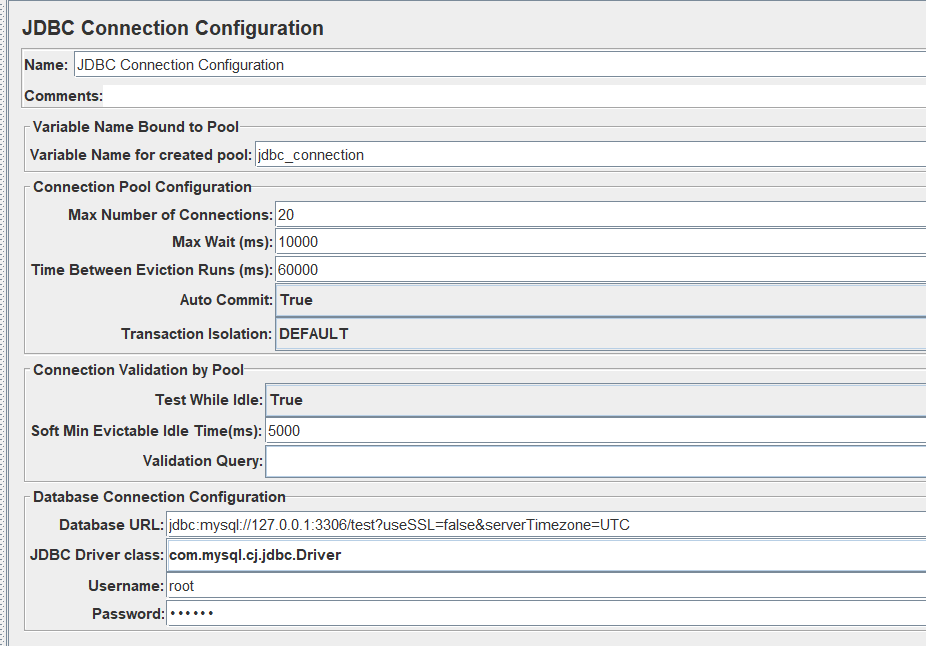
建立JDBC连接配置
JDBC request->add -> config element -> JDBC connection configuration

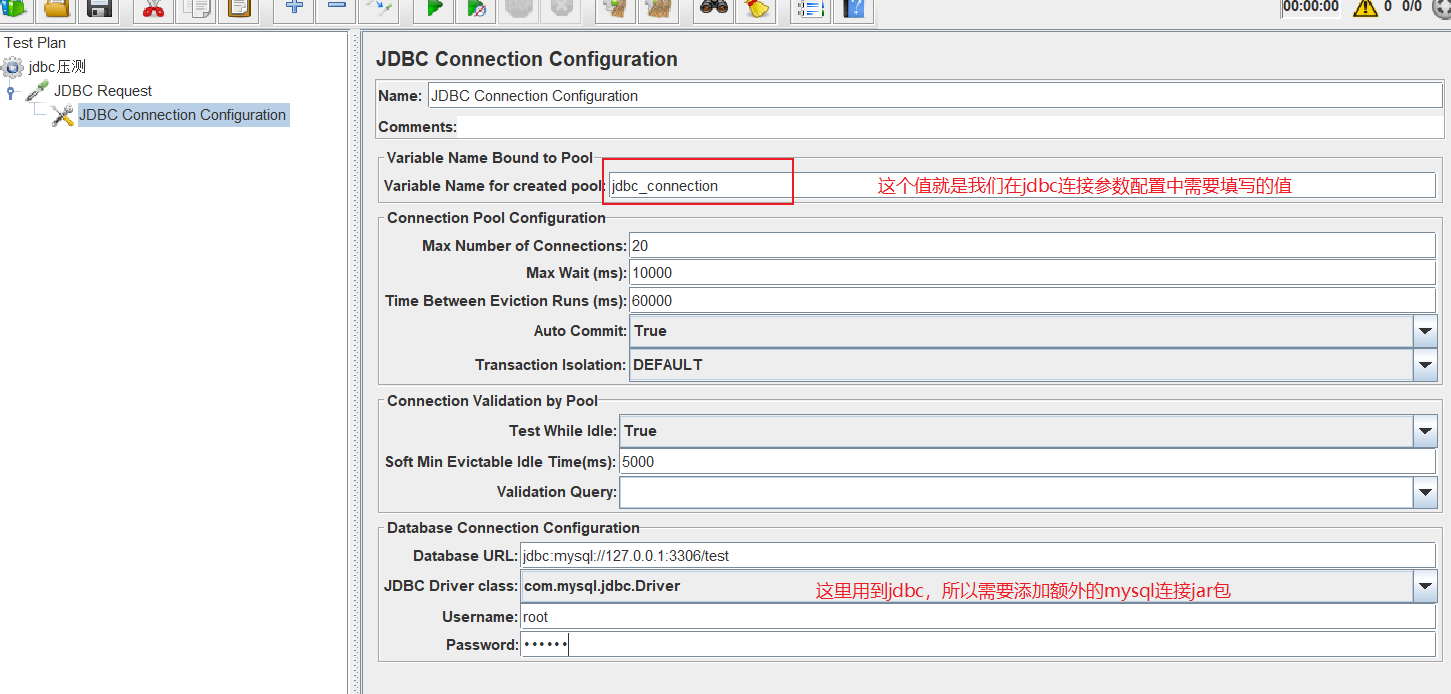
核心配置
Max Number of connections : 最大连接数
MAX wait :最大等待时间
Auto Commit: 是否自动提交事务
DataBase URL : 数据库连接地址 jdbc:mysql://127.0.0.1:3306/blog
JDBC Driver Class : 数据库驱动,选择对应的mysql
username:数据库用户名
password:数据库密码
添加jdbc连接mysqljar包
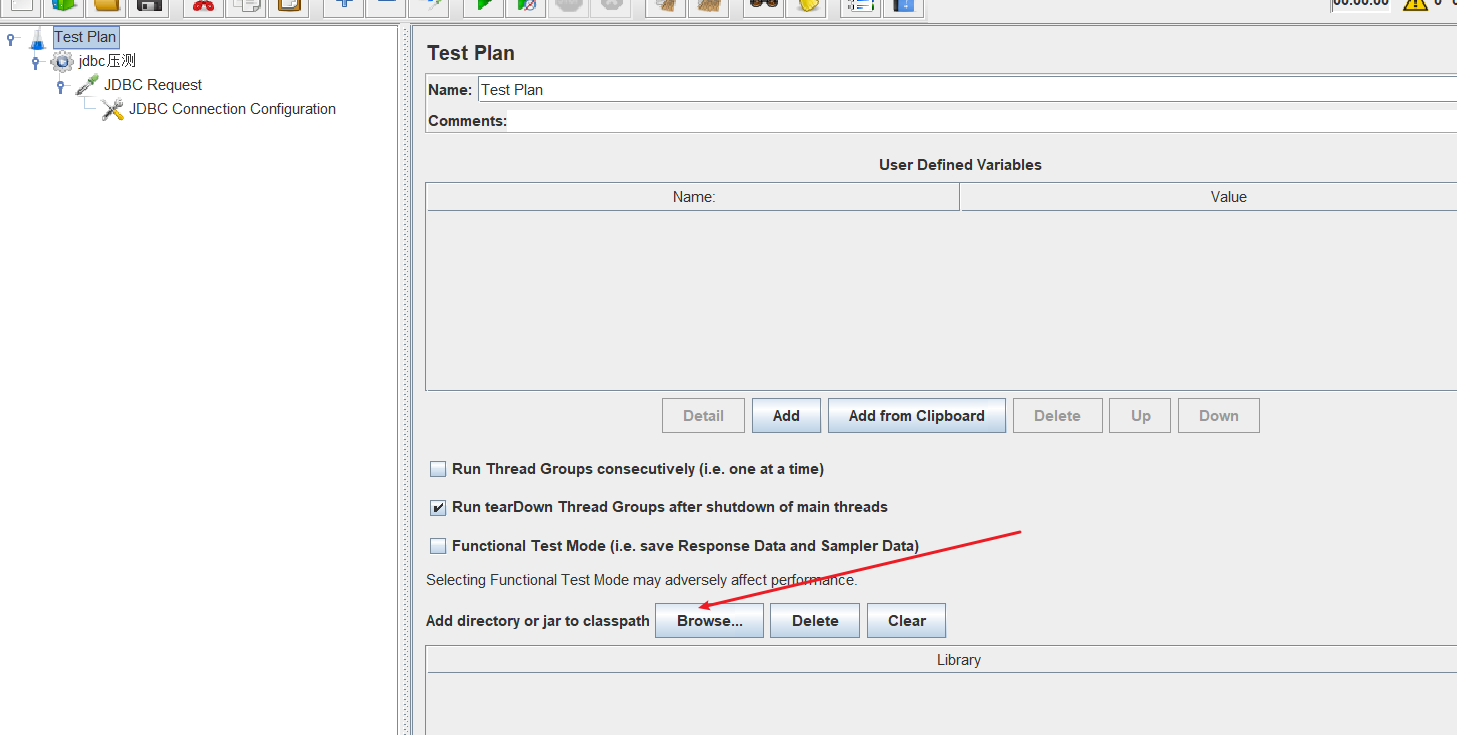
我这里因为使用的是mysql8.0,所以jdbc_url必须是com.mysql.cj.jdbc.Driver,mysql-connector.jar是mysql-connector-java-5.1.30.jar
完整连接测试
添加了聚合报告和查看结果数

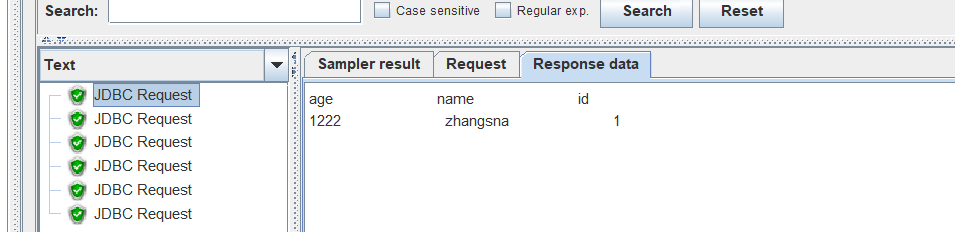
运行结果查看:
查看结果树
聚合报告
带参数的复杂查询
预查询语句
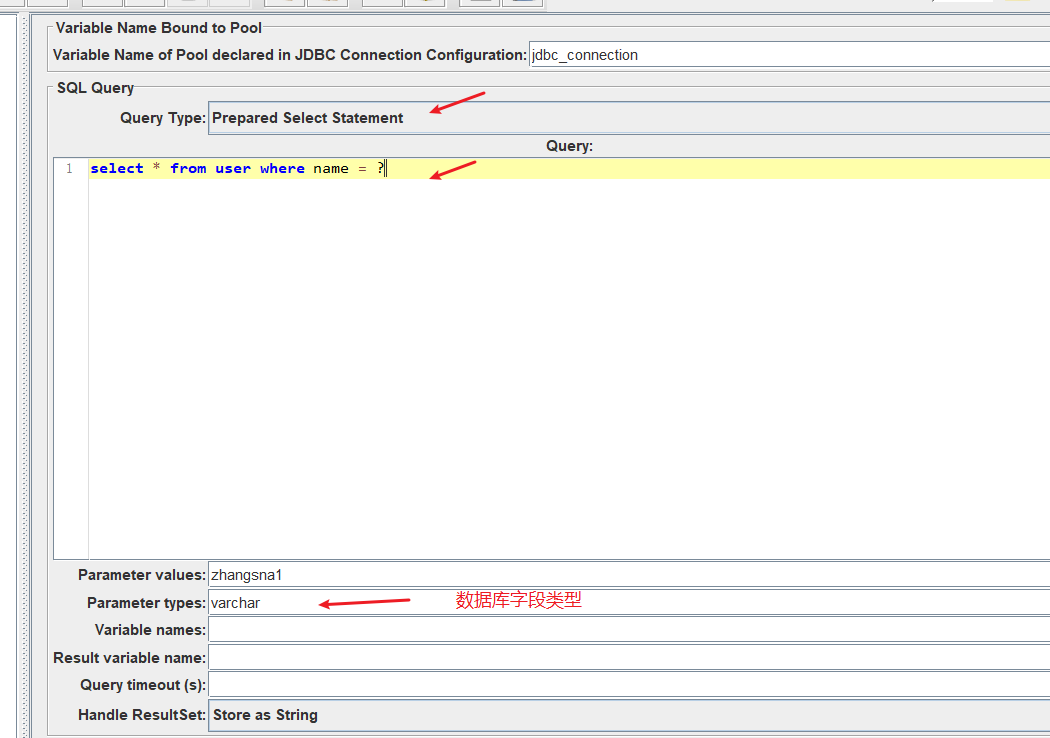
如果多个条件呢? 那就用逗号分隔开
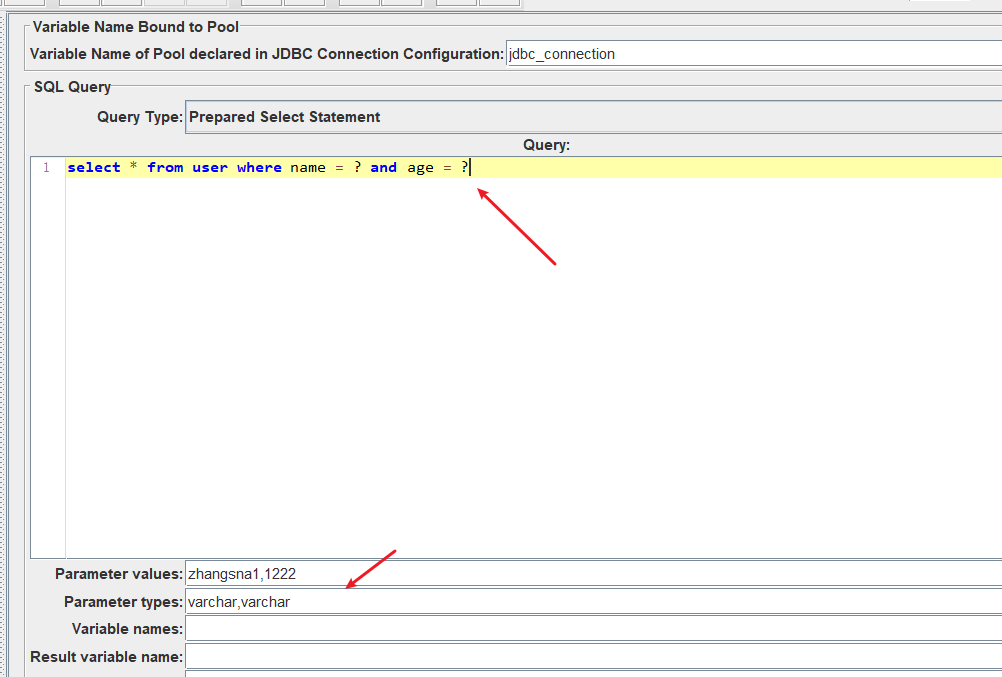
预更新语句
同上
演示查询结果集handle resultset
接下来的案例主要演示下面这三个参数
5、variable names sql执行结果变量名
6、result variable names 所有结果当做一个对象存储
8、 handle resultset 处理结果集
也就是说,我们把结果输出到指定的类型
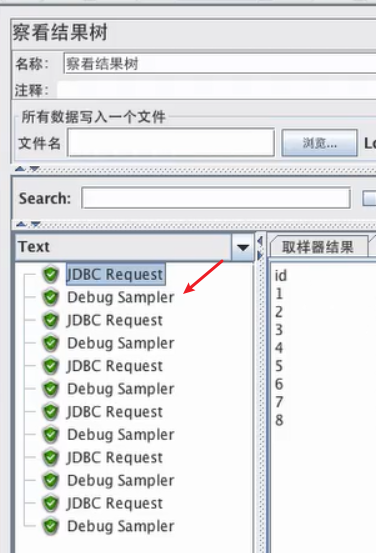
需要结合debug sample采样器进行查看,查询的结果集(在线程组下面新建debug采样器)

开始执行执行程序
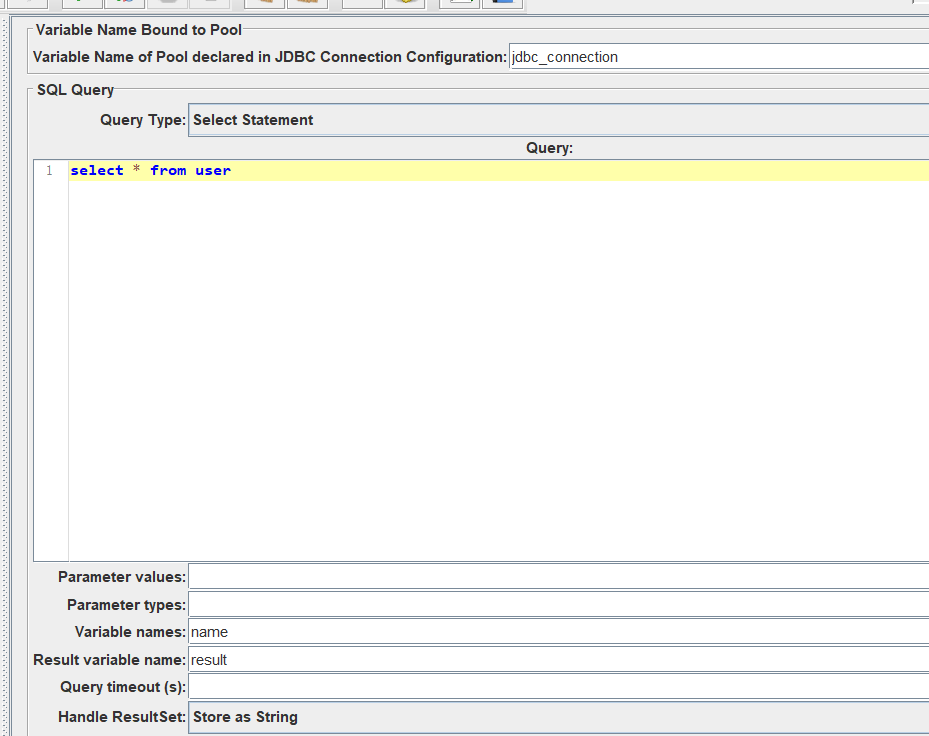
在结果树就可以看到
阿里云Linux服务器压测接口实战
Jmeter非GUI界面 参数讲解 - 一般压测不会使用gui界面进行操作,因为比较耗性能

官方也是不推荐使用,gui窗口进行压测。**那么gui界面主要是用用来生成和调试jmx压力测试文件的,生成后,再使用jmeter命令进行命令行方式的脚本压测**
jmeter 命令行
-h 帮助
-n 非GUI模式
-t 指定要运行的 JMeter 测试脚本文件
-l 记录结果的文件 每次运行之前,(要确保之前没有运行过,即目录下的xxx.jtl不存在,不然报错)
-r Jmter.properties文件中指定的所有远程服务器
-e 在脚本运行结束后生成html报告
-o 用于存放html报告的目录(目录要为空,不然报错)
官方配置文件地址 http://jmeter.apache.org/usermanual/get-started.html
|
所以整个压测流程是:
首先在windows使用gui界面,创建测试计划(jmx文件)
接着上传jmx测试脚本到需要测试服务器(一般跟项目所在服务器不同)(例如项目在147,那么测试肯定不在147上进行,可以在其他服务器,例如在148进行测试脚本的执行)
获取测试报告进行分析
压测后的jtl结果文件
通过上面的测试,我们会得到一个结果文件result.jtl ,那么我们接下来就把他从linux上下载到windows本机上进行查看。
可以通过打开jmeter,新建线程组–>监听器->summary report->浏览文件.
然后选择我们下载下来的result.jtl进行查看

你会发现他的测试报告就跟上面我们创建的聚合报告 是一样的。
html压测报告分析
Dashboard的核心指标
1)Test and Report informations
Source file:jtl文件名
Start Time :压测开始时间
End Time :压测结束时间
Filter for display:过滤器
Lable:sampler采样器名称
2)APDEX(Application performance Index)
apdex:应用程序性能指标,范围在0~1之间,1表示达到所有用户均满意
T(Toleration threshold):可接受阀值
F(Frustration threshold):失败阀值
3)Requests Summary
OK:成功率
KO:失败率
4)Statistics 统计数据
lable:sampler采样器名称
samples:请求总数,并发数*循环次数
KO:失败次数
Error%:失败率
Average:平均响应时间
Min:最小响应时间
Max:最大响应时间
90th pct: 90%的用户响应时间不会超过这个值(关注这个就可以了)
举个例子,假设有10个请求,每个请求可能服务器相应的时间都不一样:2ms,3ms,4,5,2,6,8,3,9,11
那么,我们去掉极端的%10,也就是响应时间是11s,那么剩下的百分之90,最大的响应时间就是9ms,那么也就意味着,90%的用户响应时间不会超过这个9ms这个值
95th pct: 95%的用户响应时间不会超过这个值
99th pct: 99%的用户响应时间不会超过这个值 (存在极端值)
throughtput:Request per Second吞吐量 qps
received:每秒从服务器接收的数据量
send:每秒发送的数据量
Charts的核心指标
1、charts讲解
1)Over Time(随着时间的变化)
Response Times Over Time:响应时间变化趋势(比较关注)
Response Time Percentiles Over Time (successful responses):最大,最小,平均,用户响应时间分布
Active Threads Over Time:并发用户数趋势
Bytes Throughput Over Time:每秒接收和请求字节数变化,蓝色表示发送,黄色表示接受
Latencies Over Time:平均响应延时趋势
Connect Time Over Time :连接耗时趋势
1)Throughput
Hits Per Second (excluding embedded resources):每秒点击次数
Codes Per Second (excluding embedded resources):每秒状态码数量
Transactions Per Second:即TPS,每秒事务数
Response Time Vs Request:响应时间和请求数对比
Latency Vs Request:延迟时间和请求数对比
1)Response Times(接口整体性能)
Response Time Percentiles:响应时间百分比
Response Time Overview:响应时间概述
Time Vs Threads:活跃线程数和响应时间
Response Time Distribution:响应时间分布图
Jmeter压测接口的性能优化
在使用Jmeter压测减少资源使用的一些建议,即压测结果更准确:
1、使用非GUI模式:jmeter -n -t test.jmx -l result.jtl
2、少使用Listener, 如果使用-l参数,它们都可以被删除或禁用(我们还记得之前创建过的查看结果数、聚合报告等等listener,在真实测试时,最好去掉)。
3、在加载测试期间不要使用“查看结果树”或“查看结果”表监听器,只能在脚本阶段使用它们来调试脚本。
4、包含控制器在这里没有帮助,因为它将文件中的所有测试元素添加到测试计划中
5、不要使用功能模式,使用CSV输出而不是XML
6、只保存你需要的数据,尽可能少地使用断言
7、如果测试需要大量数据,可以提前准备好测试数据放到数据文件中,以CSV Read方式读取。
8、用内网压测,减少其他带宽影响压测结果
9、如果压测大流量,尽量用多几个节点以非GUI模式向服务器施压
官方推荐 :http://jakarta.apache.org/jmeter/usermanual/best-practices.html#lean_mean
分布式压测基础知识
普通压测:单台机可以对目标机器产生的压力比较小,受限因素包括CPU,网络,IO等
分布式压测:利用多台机器向目标机器产生压力,模拟几万用户并发访问
Jmeter分布式压测原理
1、总控机器的节点master,其他产生压力的机器叫“肉鸡” server
2、master会把压测脚本发送到 server上面
3、执行的时候,server上只需要把jmeter-server打开就可以了,不用启动jmeter
4、结束后,server会把压测数据回传给master,然后master汇总输出报告
5、配置详情

分布式压测注意事项:
the firewalls on the systems are turned off or correct ports are opened.
系统上的防火墙被关闭或正确的端口被打开。
all the clients are on the same subnet.
所有的客户端都在同一个子网上。
the server is in the same subnet, if 192.x.x.x or 10.x.x.x IP addresses are used. If the server doesn’t use 192.xx or 10.xx IP address, there shouldn’t be any problems.
如果使用192.x.x.x或10.x.x.x IP地址,则服务器位于同一子网中。 如果服务器不使用192.xx或10.xx IP地址,则不应该有任何问题。
Make sure JMeter can access the server.
确保JMeter可以访问服务器。
Make sure you use the same version of JMeter and Java on all the systems. Mixing versions will not work correctly.
确保在所有系统上使用相同版本的JMeter和Java。 混合版本将无法正常工作。
You have setup SSL for RMI or disabled it.
您已为RMI设置SSL或将其禁用。
官网地址 http://jmeter.apache.org/usermanual/jmeter_distributed_testing_step_by_step.html
压测注意事项:一定要用内网IP,不用用公网IP,用ping去检查
注意事项
(1)启动 slave
|
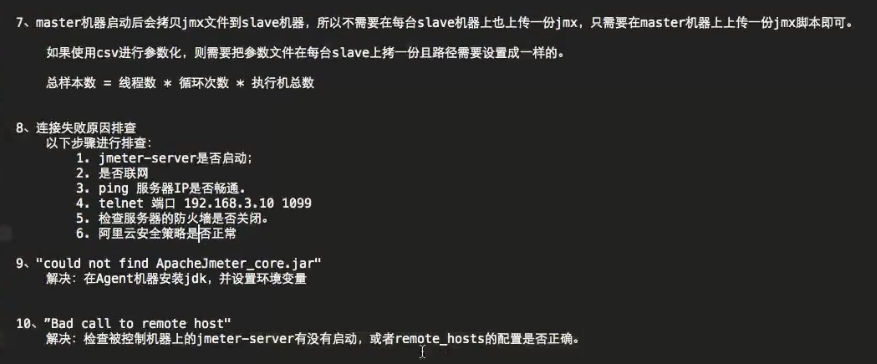
启动slave的过程中可能遇到问题,那么这些问题的解决方案如下:
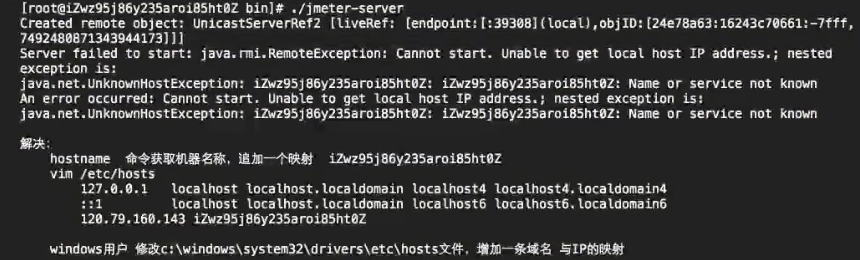

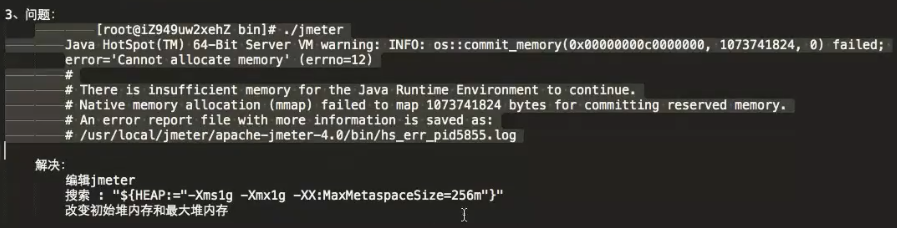
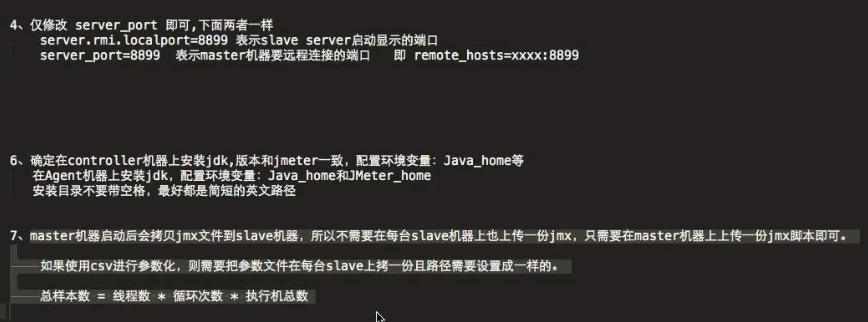
开始分布式压测
1.修改master节点信息:
jemeter.properties 值是slave机器的ip+端口号,如果有多个,用逗号分隔
|
2.启动slave机器,注意要同个网段,ip地址用内网ip
./jmeter-server
Using local port: 8899
Created remote object: UnicastServerRef2 [liveRef: [endpoint:[192.168.0.102:8899](local),objID:[3a585a4d:162724586ab:-7fff, 3963132813614033916]]]
3.启动master开始压测
./jmeter -n -t /Users/jack/Desktop/remote.jmx -r -l /Users/jack/Desktop/jtl/result.jtl -e -o /Users/jack/Desktop/result
Creating summariser <summary>
Created the tree successfully using /Users/jack/Desktop/remote.jmx
Configuring remote engine: 172.20.10.3:8899
Using local port: 8899
Configuring remote engine: 172.20.10.11:8899
Starting remote engines
Starting the test @ Thu Mar 29 23:21:13 CST 2018 (1522336873931)
Remote engines have been started
Waiting for possible Shutdown/StopTestNow/Heapdump message on port 4445
summary = 4 in 00:00:22 = 0.2/s Avg: 5582 Min: 94 Max: 21006 Err: 1 (25.00%)
Tidying up remote @ Thu Mar 29 23:21:36 CST 2018 (1522336896842)
... end of run
相关资料:
https://www.cnblogs.com/Fine-Chan/p/6233823.html
https://blog.csdn.net/liujingqiu/article/details/52635289
https://www.cnblogs.com/puresoul/p/4844539.html

