String
通过日常编码,发现,我们在编程的过程中,使用频率最高的变量或者对象,往往是字符串(可以通过分析jvm内存,可得,string类型的数据一般占用的内存排行在最前列),那么怎么优化string类型的字符串成为了一个重点。
而且优化的目的就是,复用已经存在的字符串,让他的存取类比于java基本类型的存取。

string并不是基本类型。
通过看源码,发现String是一个final不可变的,换言说,如果你给一个String变量重新赋值,那么最终是会重新建立一个string类型数据复制给他,而不会覆盖之前的值。final修饰的成员变量,因此任何看似对String内容进行操作的方法,实际上都是返回了一个新的String对象,这就造就了一个String对象的被创建后,就一直会保持不变(所以要警惕,string的多次修改,因为会创建很多string值,那么常量池可能会占尽)
|
同时我们知道,string的值,是存放在jvm方法区中,具体位置是,方法区的常量池。这样做的好处就是,能够共享已经存在的string数据,避免重复创建。
举个简单例子。
|
答案是true,为什么,因为创建a 变量时,就会在常量池中创建 123字符串,然后把该字符串在常量池的地址,复制给a变量。当发现b的值也是123的时候,那么他会现在常量池中寻找是否存在123字符串,如果存在,那么就直接把123的地址复制给b变量。
|
|
反编译代码:
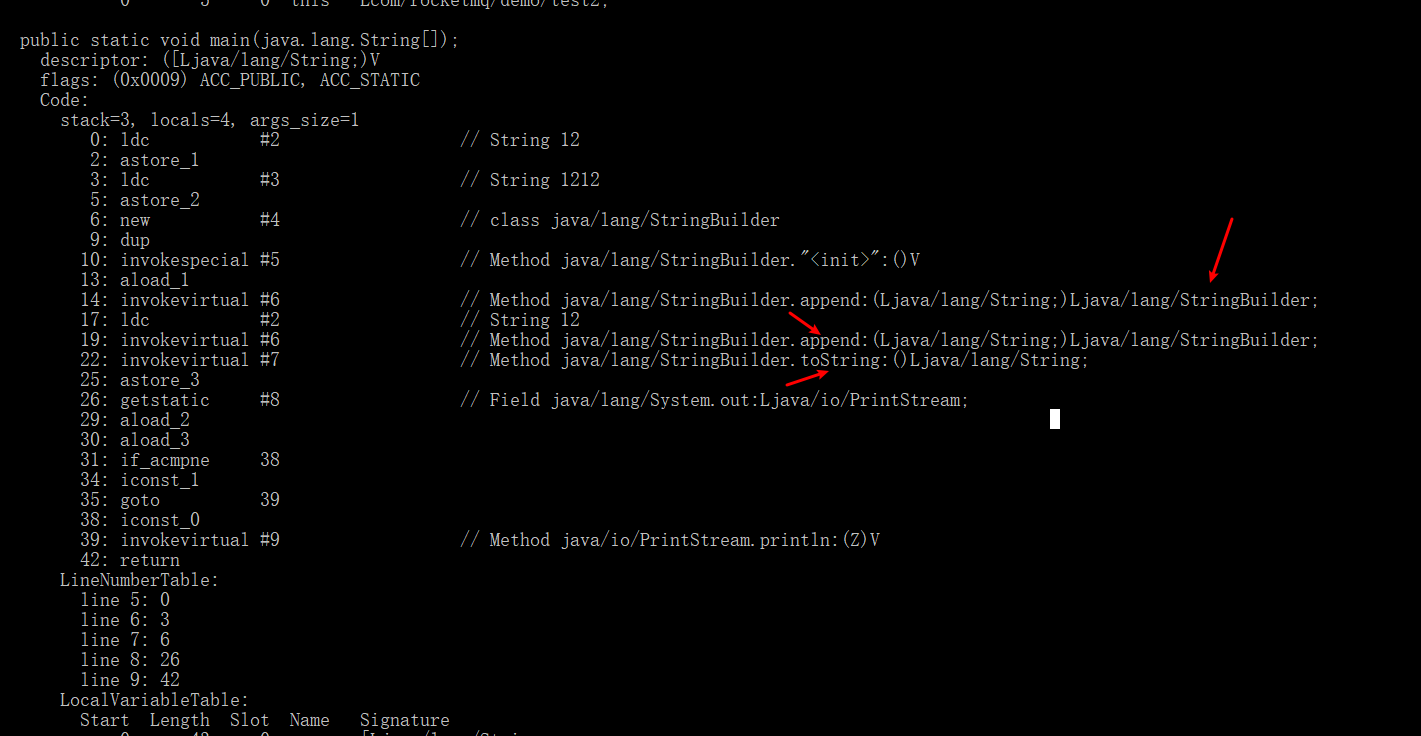
再来看一个例子
|
String类型的常量池比较特殊。它的主要使用方法有两种:
1.直接使用双引号声明出来的String对象会直接存储在常量池中。
2.如果不是用双引号声明的String对象,可以使用String提供的intern方法。intern 方法会从字符串常量池中查询当前字符串是否存在,若不存在就会将当前字符串放入常量池中
查看string重写的equals方法
|
什么是字面值?
字面值就是可以直接看到是多少的数据,在程序运行中其值不能发生改变。
以下这些就是字面值,字面值,都是存放在常量池中
|
Stringbuffer和Stringbuilder
这两者其实是一模一样的,区别在于,stringbuffer是线程安全的,而stringbuilder是线程不安全的。二者都继承了 AbstractStringBuilder,里面包含了基本操作。区别仅在于Stringbuffer的方法都加了 synchronized。
我们在使用stringbuilder或者stringbuffer的时候,需要考虑到是否存在锁优化的问题(详情参见java并发总结文章)
总结
1.string是一个不可变的变量,常量池中一定不存在两个相同的字符串。不可变的意思是,假设创建了这个值就不会再改变,针对于这个字符串的改变,都会重新创建一个新的字符串对象。(例如调用string的,substring,concat等方法,都是返回一个新的string对象)
2.两个字面值字符串相加,在编译期间就可以确定他们的值,他们的加值就存放在字符串常量池中。但是一个字面量加上一个字符串变量,只有在运行期间才会确定值,他们最终是通过stringbuilder的append方法实现相加,最终通过调用toString方法返回一个新的string对象。
关于string.iten的源码:http://cmsblogs.com/?p=5248
好的博客地址:https://www.cnblogs.com/dengchengchao/p/9713859.html 重要
https://blog.csdn.net/JohnDeng520/article/details/94914717
深入理解Java中的String(大坑)https://blog.csdn.net/qq_34490018/article/details/82110578
https://blog.csdn.net/ifwinds/article/details/80849184 重要,iten方法的存在就是为了避免,创建过多的对象。
https://www.cnblogs.com/airnew/p/11628017.html 重要
Exception和Error有什么区别?
异常的出现,是为了解决在编码过程中,某个逻辑可能出现的意料之外的情况,我们通过捕获这种情况,然后做相应的修正逻辑或者后继处理,使得我们的程序更加健壮。
我们知道出现的意料之外的情况,可以能分为两种,出现问题后我们获取问题然后做拯救措施,程序紧着可以运行,另一种就是出现问题,就算我们再拯救也没用,那么就直接让程序挂掉,然后我们事后做分析。那就是,可以恢复和不可恢复,进而言之分为,exception和error。
Exception 和 Error 都是继承了 Throwable 类,在 Java 中只有 Throwable 类型的实例才可以被抛出(throw)或者捕获(catch),它是异常处理机制的基本组成类型。
Exception 和 Error 体现了 Java 平台设计者对不同异常情况的分类。Exception 是程序正常运行中,可以预料的意外情况,可能并且应该被捕获,进行相应处理。
Error 是指在正常情况下,不大可能出现的情况,绝大部分的 Error 都会导致程序(比如 JVM 自身)处于非正常的、不可恢复状态。既然是非正常情况,所以不便于也不需要捕获,常见的比如 OutOfMemoryError 之类,都是 Error 的子类。
Exception 又分为可检查(checked)异常和不检查(unchecked)异常,可检查异常在源代码里必须显式地进行捕获处理,这是编译期检查的一部分。前面我介绍的不可查的 Error,是 Throwable 不是 Exception。
不检查异常就是所谓的运行时异常,类似 NullPointerException、ArrayIndexOutOfBoundsException 之类,通常是可以编码避免的逻辑错误,具体根据需要来判断是否需要捕获,并不会在编译期强制要求。
你了解哪些 Error、Exception 或者 RuntimeException?

NullPointerException,在写if判断逻辑的时候,没有考虑充分,导致某种情况的入参,没有做到对象的初始化,然后用对象去调用某个方法时,出现问题。
ClassCastException 类转化异常。报表导入时,做映射的时候。
继承于RuntimeException的异常都是可检查异常,继承Exception是非检查异常
try-with-resources 自动关闭资源
Try-with-resources是java7中一个新的异常处理机制,它能够很容易地关闭在try-catch语句块中使用的资源。
在以前的代码中,我们一般是通过finally做最后的资源回收工作,
|
在java7中,对于上面的例子可以用try-with-resource 结构这样写:
|
这就是try-with-resource 结构的用法。FileInputStream 类型变量就在try关键字后面的括号中声明。而且一个FileInputStream 类型被实例化并被赋给了这个变量。
当try语句块运行结束时,FileInputStream 会被自动关闭。这是因为FileInputStream 实现了java中的java.lang.AutoCloseable接口。所有实现了这个接口的类都可以在try-with-resources结构中使用。
当try-with-resources结构中抛出一个异常,同时FileInputStreami被关闭时(调用了其close方法)也抛出一个异常,try-with-resources结构中抛出的异常会向外传播,而FileInputStreami被关闭时抛出的异常被抑制了。
知识扩展
先开看第一个吧,下面的代码反映了异常处理中哪些不当之处?
|
这段代码虽然很短,但是已经违反了异常处理的两个基本原则。
第一,尽量不要捕获类似 Exception 这样的通用异常,而是应该捕获特定异常,在这里是 Thread.sleep() 抛出的 InterruptedException。
这是因为在日常的开发和合作中,我们读代码的机会往往超过写代码,软件工程是门协作的艺术,所以我们有义务让自己的代码能够直观地体现出尽量多的信息,而泛泛的 Exception 之类,恰恰隐藏了我们的目的。另外,我们也要保证程序不会捕获到我们不希望捕获的异常。比如,你可能更希望 RuntimeException 被扩散出来,而不是被捕获。
进一步讲,除非深思熟虑了,否则不要捕获 Throwable 或者 Error,这样很难保证我们能够正确程序处理 OutOfMemoryError。
第二,不要生吞(swallow)异常。这是异常处理中要特别注意的事情,因为很可能会导致非常难以诊断的诡异情况。
生吞异常,往往是基于假设这段代码可能不会发生,或者感觉忽略异常是无所谓的,但是千万不要在产品代码做这种假设!
如果我们不把异常抛出来,或者也没有输出到日志(Logger)之类,程序可能在后续代码以不可控的方式结束。没人能够轻易判断究竟是哪里抛出了异常,以及是什么原因产生了异常。
体会一下Throw early, catch late 原则
我们接下来看下面的代码段,体会一下Throw early, catch late 原则。
|
如果 fileName 是 null,那么程序就会抛出 NullPointerException,但是由于没有第一时间暴露出问题,堆栈信息可能非常令人费解,往往需要相对复杂的定位。这个 NPE 只是作为例子,实际产品代码中,可能是各种情况,比如获取配置失败之类的。在发现问题的时候,第一时间抛出,能够更加清晰地反映问题。
我们可以修改一下,让问题“throw early”,对应的异常信息就非常直观了。
|
至于“catch late”,其实是我们经常苦恼的问题,捕获异常后,需要怎么处理呢?最差的处理方式,就是我前面提到的“生吞异常”,本质上其实是掩盖问题。如果实在不知道如何处理,可以选择保留原有异常的 cause 信息,直接再抛出或者构建新的异常抛出去。在更高层面,因为有了清晰的(业务)逻辑,往往会更清楚合适的处理方式是什么。
有的时候,我们会根据需要自定义异常,这个时候除了保证提供足够的信息,还有两点需要考虑:
- 是否需要定义成 Checked Exception,因为这种类型设计的初衷更是为了从异常情况恢复,作为异常设计者,我们往往有充足信息进行分类。
- 在保证诊断信息足够的同时,也要考虑避免包含敏感信息,因为那样可能导致潜在的安全问题。如果我们看 Java 的标准类库,你可能注意到类似 java.net.ConnectException,出错信息是类似“ Connection refused (Connection refused)”,而不包含具体的机器名、IP、端口等,一个重要考量就是信息安全。类似的情况在日志中也有,比如,用户数据一般是不可以输出到日志里面的。
业界有一种争论(甚至可以算是某种程度的共识),Java 语言的 Checked Exception 也许是个设计错误,反对者列举了几点:
- Checked Exception 的假设是我们捕获了异常,然后恢复程序。但是,其实我们大多数情况下,根本就不可能恢复。Checked Exception 的使用,已经大大偏离了最初的设计目的。
- Checked Exception 不兼容 functional 编程,如果你写过 Lambda/Stream 代码,相信深有体会。
我们从性能角度来审视一下 Java 的异常处理机制,这里有两个可能会相对昂贵的地方:
- try-catch 代码段会产生额外的性能开销,或者换个角度说,它往往会影响 JVM 对代码进行优化,所以建议仅捕获有必要的代码段,尽量不要一个大的 try 包住整段的代码;与此同时,利用异常控制代码流程,也不是一个好主意,远比我们通常意义上的条件语句(if/else、switch)要低效。
- Java 每实例化一个 Exception,都会对当时的栈进行快照,这是一个相对比较重的操作。如果发生的非常频繁,这个开销可就不能被忽略了。
所以,对于部分追求极致性能的底层类库,有种方式是尝试创建不进行栈快照的 Exception。这本身也存在争议,因为这样做的假设在于,我创建异常时知道未来是否需要堆栈。问题是,实际上可能吗?小范围或许可能,但是在大规模项目中,这么做可能不是个理智的选择。如果需要堆栈,但又没有收集这些信息,在复杂情况下,尤其是类似微服务这种分布式系统,这会大大增加诊断的难度。
当我们的服务出现反应变慢、吞吐量下降的时候,检查发生最频繁的 Exception 也是一种思路。关于诊断后台变慢的问题,我会在后面的 Java 性能基础模块中系统探讨。
强引用、软引用、弱引用、幻象引用有什么区别?
不同的引用类型,主要体现的是对象不同的可达性(reachable)状态和对垃圾收集的影响。也就是说,他是跟
所谓强引用(“Strong” Reference),就是我们最常见的普通对象引用,只要还有强引用指向一个对象,就能表明对象还“活着”,垃圾收集器不会碰这种对象(我们平常典型编码Object obj = new Object()中的obj就是强引用。通过关键字new 创建的对象所关联的引用就是强引用)。对于一个普通的对象,如果没有其他的引用关系,只要超过了引用的作用域或者显式地将相应(强)引用赋值为 null,就是可以被垃圾收集的了,当然具体回收时机还是要看垃圾收集策略。
软引用(通过这个类实现SoftReference),是一种相对强引用弱化一些的引用,可以让对象豁免一些垃圾收集,只有当 JVM 认为内存不足时,才会去试图回收软引用指向的对象。JVM 会确保在抛出 OutOfMemoryError 之前,清理软引用指向的对象。软引用通常用来实现内存敏感的缓存,如果还有空闲内存,就可以暂时保留缓存,当内存不足时清理掉,这样就保证了使用缓存的同时,不会耗尽内存。虽说难以下咽,但是弃之可惜,所以他是强引用的一种折中方案,当jvm堆内存充足不会回收,但是当堆内存不足的时候,就会被回收。换句话说,就是尽量留下来
弱引用(WeakReference)并不能使对象豁免垃圾收集,仅仅是提供一种访问在弱引用状态下对象的途径。这就可以用来构建一种没有特定约束的关系,比如,维护一种非强制性的映射关系,如果试图获取时对象还在,就使用它,否则重现实例化。它同样是很多缓存实现的选择。
对于幻象引用,有时候也翻译成虚引用,你不能通过它访问对象。幻象引用仅仅是提供了一种确保对象被 finalize 以后,做某些事情的机制,比如,通常用来做所谓的 Post-Mortem 清理机制。
动态代理和反射是基于什么原理?
什么叫代理,就是我代替你去做某件事情,例如代购,通过代理功能,我们可以在调用被代理对象(委托类)的某个方法的前后做一些逻辑补充操作,例如我们要做饭,那么我们在做饭之前先洗米,插上电源—>> 做饭 —>拔下电源。
这个就是我们常说的切面,就是在原来的基础上(不改变委托类),切入我们想要的逻辑。
代理模式是对象的结构模式。代理模式给某一个对象提供一个代理对象,并由代理对象控制对原对象的引用。
代理模式是一种常用的设计模式。代理模式为其对象提供了一种代理以控制对这个对象的访问。代理模式可以将主要业务与次要业务进行松耦合的组装。根据代理类的创建时机和创建方式的不同,可以将其分为静态代理和动态代理两种形式:
在程序运行前就已经存在的编译好的代理类是为静态代理。
在程序运行期间根据需要动态创建代理类及其实例来完成具体的功能是为动态代理。(动态代理的实现方式有两种,JDK动态代理和cglib动态代理)
静态代理
继承
就是通过继承委托类,生成代理类,然后重写委托类的方法,重新实现逻辑,完成代理的逻辑。
代理类是委托类的子类(有点cglib动态代理的味道)
聚合
代理类和委托类,都实现同一个接口,代理类依赖委托类(代理类注入委托类)
接下来看一下静态代理的实现代码:
|
可以看到,代理类和委托类,都实现共同的接口IHelloService。静态代理,实际上就是在代理类中,注入委托类,然后代理类可以实现一些额外的方法,然后真正的调用时。通过代理类去调用委托类。我们可以看待,代码的结构是固定的,在编译前就可以确定代理类有哪些方法。
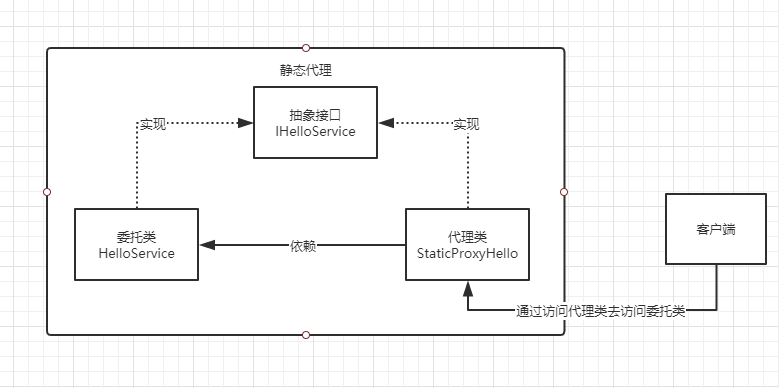
使用静态代理的缺点是:只适用委托方法少的情况下, 试想一下如果委托类有几百上千个方法, 岂不是很难受, 要在代理类中写一堆的代理方法。换句话说,我们有三个开发,每个人在调用委托类的方法之前,都会有自己的迁入逻辑补充,那么也就意味着,需要在StaticProxyHello代理类中,实现各自的方法,那么代理类中的代理方法就会疯狂增多,那么就会导致代理类很难管理。也就是说,我们想要按需在代理类中添加我们想要切入的逻辑,那么这个就是要动态的添加代理方法了。
①代理类和被代理类实现了相同的接口,导致代码的重复,如果接口增加一个方法,那么除了被代理类需要实现这个方法外,代理类也要实现这个方法,增加了代码维护的难度。
②代理对象只服务于一种类型的对象,如果要服务多类型的对象。势必要为每一种对象都进行代理,静态代理在程序规模稍大时就无法胜任了。比如上面的例子,只是对用户的业务功能(IUserService)进行代理,如果是商品(IItemService)的业务功能那就无法代理,需要去编写商品服务的代理类。
实现静态代理有四个步骤:
- 定义业务接口
- 定义委托类并实现业务接口
- 定义代理类并实现业务接口,同时依赖委托类(委托类是代理类的一个成员变量)
这个需求,就需要动态代理。
动态代理
代理类在程序运行时创建的代理方式被成为 动态代理。在了解动态代理之前, 我们先简回顾一下 JVM 的类加载机制中的加载阶段要做的三件事情 ( 附 Java 中的类加载器 )
- 通过一个类的全名或其它途径来获取这个类的二进制字节流。
- 将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构。
- 在内存中生成一个代表这个类的 Class 对象, 作为方法区中对这个类访问的入口。
而我们要说的动态代理,主要就发生在第一个阶段, 这个阶段类的二进制字节流的来源可以有很多, 比如 zip 包、网络、运行时计算生成、其它文件生成 (JSP)、数据库获取。其中运行时计算生成就是我们所说的动态代理技术,在 Proxy 类中, 就是运用了 ProxyGenerator.generateProxyClass 来为特定接口生成形式为 *$Proxy 的代理类的二进制字节流。所谓的动态代理就是想办法根据接口或者目标对象计算出代理类的字节码然后加载进 JVM 中。实际计算的情况会很复杂,我们借助一些诸如 JDK 动态代理实现、CGLIB 第三方库来完成。
JDK 动态代理
在 Java 的动态代理中, 主要涉及 2 个类,java.lang.reflect.Proxy和java.lang.reflect.InvocationHandler 我们需要一个实现 InvocationHandler 接口的中间类, 这个接口只有一个方法 invoke 方法。
|
实际上最关键的就是这个中间类,通过中间类,我们可以拦截委托类所有方法的调用,然后做一些额外的工作。
我们对处理类(中间类生成的代理对象)中的所有方法的调用都会变成对 invoke 方法的调用,这样我们可以在 invoke 方法中添加统一的处理逻辑(也可以根据 method 参数判断是哪个方法)。中间类 (实现了 InvocationHandler 的类) 有一个委托类对象引用, 在 Invoke 方法中调用了委托类对象的相应方法,通过这种聚合的方式持有委托类对象引用,把外部对 invoke 的调用最终都转为对委托类对象的调用。
实际上,中间类与委托类构成了静态代理关系(他们的关系就是在中间类总注入委托类,然后调用,编译时即可确定关系),在这个关系中,中间类是代理类,委托类是委托类。然后代理类与中间类也构成一个静态代理关系,在这个关系中,中间类是委托类,代理类是代理类。也就是说,动态代理关系由两组静态代理关系组成,这就是动态代理的原理。
jdk的reflect实现动态代理
|
在上面的测试动态代理类中, 我们调用 Proxy 类的 newProxyInstance 方法来获取一个代理类实例。这个代理类实现了我们指定的接口并且会把方法调用分发到指定的调用处理器*(也就是invocationhandler的invoke方法)。
首先通过 newProxyInstance 方法获取代理类的实例, 之后就可以通过这个代理类的实例调用代理类的方法,对代理类的方法调用都会调用中间类 (实现了 invocationHandle 的类) 的 invoke 方法,在 invoke 方法中我们调用委托类的对应方法,然后加上自己的处理逻辑。
java 动态代理最大的特点就是动态生成的代理类和委托类实现同一个接口。java 动态代理其实内部是通过反射机制实现的,也就是已知的一个对象,在运行的时候动态调用它的方法,并且调用的时候还可以加一些自己的逻辑在里面。
Proxy.newProxyInstance 源码阅读。
上面说过, Proxy.newProxyInstance 通过反射机制用来动态生成代理类对象, 为接口创建一个代理类,这个代理类实现这个接口。具体源码如下:
|
接着分析一下 getProxyClass0()方法
我们发现他会先从缓存中查找是否存在相应的代理类的class对象,有则直接返回,没有则新增。
|
超详细源码分析:https://www.jianshu.com/p/269afd0a52e6
为什么实现同一个接口是实现jdk动态代理的基础
为什么jdk动态代理就不能通过继承某个类的方式实现呢?
我们可以通过查看jdk动态动态代理方式生成的代理类,我们发现,代理类他最终的结构是:
|
总结
我们发现,实际上,委托类和代理类本质上都是实现了同一个接口,实现同一个接口是实现动态代理的基础。jdk的动态代理,实际上是两组静态代理实现。代理类和中间类是静态代理关系,中间类和委托类是静态代理关系。
而且动态代理跟静态代理的区别,在于,我们不用实现一个静态的代理类(例如静态代理的StaticProxyHello),我们通过一个中间类(invocationhandler是实现类)生成代理类。然后我们可以定制自己在调用委托类方法之前,切入自己的逻辑。 也就是说,代理类是运行的时候才生成的。故叫动态代理
同时我们注意源码的Class<?> cl = getProxyClass0(loader, intfs); 你会发现,它是会先查找缓存中是否存在代理类Class对象,如果存在则不新增。这样的好处就是,不会在jvm的metaspace区占满内存。
itss项目和固定资产项目,使用到了,动态反射,实现了资产的导入。
CGLIB动态代理
JDK 动态代理依赖接口实现,而当我们只有类没有接口的时候就需要使用另一种动态代理技术 CGLIB 动态代理。首先 CGLIB 动态代理是第三方框架实现的,在 maven 工程中我们需要引入 cglib 的包, 如下:
|
CGLIB 代理是针对类来实现代理的,原理是对指定的委托类生成一个子类并重写其中业务方法来实现代理。代理类对象是由 Enhancer 类创建的。CGLIB 创建动态代理类的模式是:
- 查找目标类上的所有非 final 的 public 类型的方法 (final 的不能被重写)
- 将这些方法的定义转成字节码
- 将组成的字节码转换成相应的代理的 Class 对象然后通过反射获得代理类的实例对象
- 实现 MethodInterceptor 接口, 用来处理对代理类上所有方法的请求
|
对于需要被代理的类,它只是动态生成一个子类以覆盖非 final 的方法,同时绑定钩子回调自定义的拦截器。值得说的是,它比 JDK 动态代理还要快。值得注意的是,我们传入目标类作为代理的父类。
不同于 JDK 动态代理,我们不能使用目标对象来创建代理(我们是通过接口来实现代理类)。目标对象只能被 CGLIB 创建。
在例子中,默认的无参构造方法被使用来创建目标对象。
可以看到使用CGLIB实现动态代理,少实现了一个类,那就是IHelloService。因为CGLIB实现的代理类的父类就是委托类。
使用cglib要注意,开启使用缓存标志,否则,就会导致,因为动态生成过多的Class对象,从而挤爆永久代(metaspace)
总结
静态代理比较容易理解, 需要被代理的类和代理类实现自同一个接口, 然后在代理类中调用真正实现类, 并且静态代理的关系在编译期间就已经确定了。
而动态代理的关系是在运行期间确定的。静态代理实现简单,适合于代理类较少且确定的情况,而动态代理则给我们提供了更大的灵活性。
JDK 动态代理所用到的代理类在程序调用到代理类对象时才由 JVM 真正创建,JVM 根据传进来的 业务实现类对象 以及 方法名 ,动态地创建了一个代理类的 class 文件并被字节码引擎执行,然后通过该代理类对象进行方法调用。我们需要做的,只需指定代理类的预处理、调用后操作即可。
静态代理和动态代理都是基于接口实现的, 而对于那些没有提供接口只是提供了实现类的而言, 就只能选择 CGLIB 动态代理了
JDK 动态代理和 CGLIB 动态代理的区别
JDK 动态代理基于 Java 反射机制实现, 必须要实现了接口的业务类才能用这种方法生成代理对象。
CGLIB 动态代理基于 ASM 框架通过生成业务类的子类来实现。
JDK 动态代理的优势是最小化依赖关系,但是需要定义一个公有的接口(IHelloService),减少依赖意味着简化开发和维护并且有 JDK 自身支持。还可以平滑进行 JDK 版本升级,代码实现简单。
基于 CGLIB 框架的优势是无须实现接口,达到代理类无侵入,我们只需操作我们关系的类,不必为其它相关类增加工作量,性能比较高。
描述代理的几种实现方式? 分别说出优缺点?
代理可以分为 “静态代理” 和 “动态代理”,动态代理又分为 “JDK 动态代理” 和 “CGLIB 动态代理” 实现。
静态代理:代理对象和实际对象都继承了同一个接口,在代理对象中指向的是实际对象的实例,这样对外暴露的是代理对象而真正调用的是 Real Object.
- 优点:可以很好的保护实际对象的业务逻辑对外暴露,从而提高安全性。
- 缺点:不同的接口要有不同的代理类实现,会很冗余
JDK 动态代理: 为了解决静态代理中,生成大量的代理类造成的冗余; JDK 动态代理只需要实现 InvocationHandler 接口,重写 invoke 方法便可以完成代理的实现,
jdk 的代理是利用反射生成代理类 Proxyxx.class 代理类字节码,并生成对象 jdk 动态代理之所以只能代理接口是因为代理类本身已经 extends 了 Proxy,而 java 是不允许多重继承的,但是允许实现多个接口
- 优点:解决了静态代理中冗余的代理实现类问题。
- 缺点:JDK 动态代理是基于接口设计实现的,如果没有接口,会抛异常。
CGLIB 代理: 由于 JDK 动态代理限制了只能基于接口设计,而对于没有接口的情况,JDK 方式解决不了; CGLib 采用了非常底层的字节码技术,其原理是通过字节码技术为一个类创建子类,并在子类中采用方法拦截的技术拦截所有父类方法的调用,顺势织入横切逻辑,来完成动态代理的实现。 实现方式实现 MethodInterceptor 接口,重写 intercept 方法,通过 Enhancer 类的回调方法来实现。
但是 CGLib 在创建代理对象时所花费的时间却比 JDK 多得多,所以对于单例的对象,因为无需频繁创建对象,用 CGLib 合适,反之,如果需要创建大量对象,使用 JDK 方式要更为合适一些。 同时,由于 CGLib 由于是采用动态创建子类的方法,对于 final 方法,无法进行代理。
优点:没有接口也能实现动态代理,而且采用字节码增强技术,性能也不错。
缺点:技术实现相对难理解些。
总而言之,JDK的动态代理有一个限制,就是使用动态代理的对象必须实现一个或多个接口。如果想代理没有实现接口的类,就可以使用CGLIB实现。 但是使用CGLIB要非常注意,因为
为什么面试会问?
从考察知识点的角度,这道题涉及的知识点比较庞杂,所以面试官能够扩展或者深挖的内容非常多,比如:
- 考察你对反射机制的了解和掌握程度。
- 动态代理解决了什么问题,在你业务系统中的应用场景是什么?
- JDK 动态代理在设计和实现上与 cglib 等方式有什么不同,进而如何取舍?
java反射
我们知道JDK生成代理类的方式,最终实现是是通过,反射的机制实现的,那么什么是反射呢?
反射目的就是为了程序在运行过程中动态创建某个类。
首先要知道Class类
对象照镜子后可以得到的信息:某个类的数据成员名、方法和构造器、某个类到底实现了哪些接口。对于每个类而言,JRE 都为其保留一个不变的 Class 类型的对象。一个 Class 对象包含了特定某个类的有关信息。
Class 对象只能由系统建立对象(不能自己new),在jvm加载字节码文件到元空间(永久代),就会自动创建Class对象。
一个类在 JVM 中只会有一个Class实例 (类加载机制,双亲委任机制保证了字节码文件的唯一性)
每个类的实例都会记得自己是由哪个 Class 实例所生成 。
所以我们都是通过Class类获取某个对象的,已经定义方法,成员变量,构造函数等等,然后在运行过程中动态执行某个方法。
获取一个对象的Class对象的方式有三种。
1.通过对象的getClass方法获取
Student stu1 = new Student();/
Class class = stu1.getClass();
2. 通过类的class属性获取,该方法最为安全可靠,程序性能更高
Class class = Student.class()
3,通过Class对象的forName静态方法获取
但是可能会抛出ClassNotFoundException异常
Class class = Class.forName("www.kingge.top.Student")
三种方式常用第三种,第一种对象都有了还要反射干什么(使用反射的目的是为了创建对象)。第二种需要导入类的包,依赖太强,不导包就抛编译错误。一般都第三种,一个字符串可以传入也可写在配置文件中等多种方法。
总结
反射的出现,目的就是让程序在运行过程中,动态生成我们所需要的类。
反射的实现,就是通过Class类,Class类是唯一的,因为通过双亲委任机制可以得知。
Java hashCode() 和 equals()的若干问题解答
Comparable和Comparator
这两个接口,都可以用来实现对象的排序。也就是说他们两个的功能实际上就是一样的。所以不要混着使用。也就是说,一个类最后不要同时实现这两个接口。
那么,他们的使用规则一般是:一个类,一般是通过实现Comparable接口实现排序(作为内部排序),但是当我们在不想修改类的代码结构的同时又想改变内部排序,这个时候可以使用Comparator接口实现重写排序逻辑(作为外部排序)。这样在排序的时候,默认的内部排序,就会被外部排序逻辑覆盖。
JMM内存模型
JMM(Java内存模型Java Memory Model,简称JMM)本身是一种抽象的概念 ,并不真实存在,它描述的是一组规则或规范通过规范定制了程序中各个变量(包括实例字段,静态字段和构成数组对象的元素)的访问方式。
JMM关于同步规定:
1.线程解锁前,必须把共享变量的值刷新回主内存
2.线程加锁前,必须读取主内存的最新值到自己的工作内存
3.加锁解锁是同一把锁
由于JVM运行程序的实体是线程,而每个线程创建时JVM都会为其创建一个工作内存(有些地方成为栈空间,实际上就是java虚拟机栈),工作内存是每个线程的私有数据区域(java虚拟机栈),而Java内存模型中规定所有变量都存储在主内存,主内存是共享内存区域,所有线程都可访问,但线程对变量的操作(读取赋值等)必须在工作内存中进行,所以线程要将操作的变量从主内存拷贝到自己的工作空间,然后对变量进行操作,操作完成再将变量写回主内存,不能直接操作主内存中的变量,各个线程中的工作内存储存着主内存中的变量副本拷贝,因此不同的线程无法访问对方的工作内存,此案成间的通讯(传值) 必须通过主内存来完成,其简要访问过程如下图:
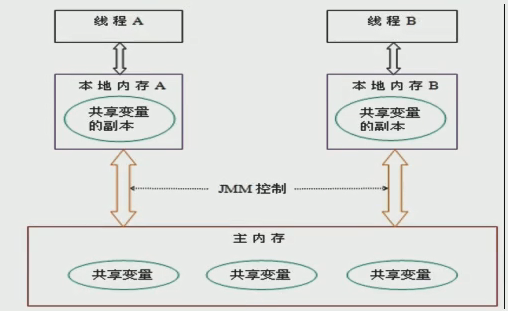
这个就是并发问题出现的根源之一,数据可见性。
也就是说:JMM的存在就是为了保证,原子性,可见性,有序性。也即是,保证多线程访问资源的安全性
Volatile
首先声明,他不是一种锁。 它会确保我们对于某个变量的读取和写入,都一定会同步到主内存里,而不是从 Cache 里面读取(也就是我们通俗的说禁用缓存)。
volatile是java虚拟机提供的的轻量级的同步机制,它能够保证可见性和禁止指令重排序。但是不能够保证原子性(那就意味着,会产生线程不安全问题)
什么叫可见性
一个线程对于共享资源的修改,对于另一个线程是可见的。也就是说,我修改后的值,你是可以看到的。也就意味着,假设另一个线程改完了,那么会通知到另一个线程。
什么叫原子性
也就是一个线程操作某个逻辑的时候,它能够保证在执行的过程中,不会发生线程切换,要么都完成,要么都失败,而且我们能够所说的原子性是针对于CPU指令而言的(高级语言里一条语句往往需要多条 CPU 指令完成)。例如我们在执行,自增操作的时候,count+=1;你以为这是一个原子操作,就是执行一条指令而已,其实不是,因为他至少会分成三个cpu指令去执行。
- 指令 1:首先,需要把变量 count 从内存加载到 CPU 的寄存器;
- 指令 2:之后,在寄存器中执行 +1 操作;
- 指令 3:最后,将结果写入内存(缓存机制导致可能写入的是 CPU 缓存而不是内存)。
操作系统做任务切换,可以发生在任何一条CPU 指令执行完,是的,是 CPU 指令,而不是高级语言里的一条语句。对于上面的三条指令来说,我们假设 count=0,如果线程 A 在指令 1 执行完后做线程切换,线程 A 和线程 B 按照下图的序列执行,那么我们会发现两个线程都执行了 count+=1 的操作,但是得到的结果不是我们期望的 2,而是 1。
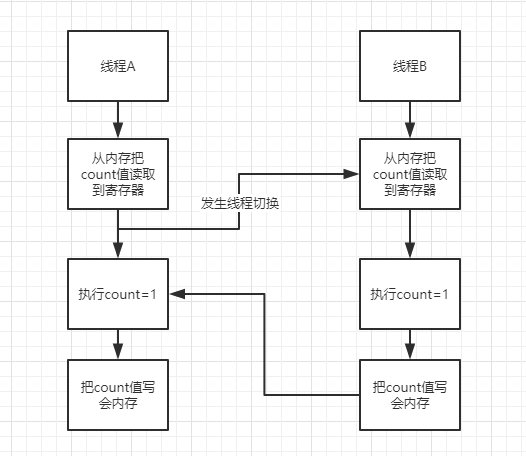
指令重排序
参见《java并发章节》
那么volatile是怎么保证可见性(数据一致性)呢?
首先查看下面例子:
|
我们知道上诉代码,一共创建了两个线程,一个是main线程,一个是a线程。
那么为什么在a线程内部停了三秒呢?目的就是,让a线程跟main线程,获取的共享资源的number都是一样的(也就是0),拷贝到自己的java虚拟机栈的number都是0。这样就能够保证,main线程,执行成功while循环,然后main线程不会结束。这样才能够验证volatile的可见性。
上诉代码,的执行结果,我们其实也能够看的出来,输出如下:
|
main线程,永久挂在那里,a线程执行完毕。 也就意味着,a线程虽然修改了number 的值,同时把主内存的number修改为60,但是对于main线程而言是不可见的,没有通知main线程,main线程认为还是0。否则,main线程应该结束while循环。
那么我们说volatile可以解决可见性,那么是真是假呢?
我们把 public int number = 0; 修改为public volatile int number = 0;,再次运行代码。
程序输出:
|
我们惊喜的发现,main线程竟然退出了!!!,那也就意味着,a线程修改完number后,写入到主内存,然后成功通知了挂起来的main线程。
所以,到这里,我们就成功的验证了volatile的可见性机制。
验证volatile不支持原子性
验证例子:
|
你会发现,输出的值,都是随机的,并不是我们预期的20000,所以volatile并不能保证原子性。
解决方式
解决方案:使用synchronized内部锁或者Lock显示锁,但是加锁又太重,杀鸡用牛刀,我们可以考虑使用AtomicInteger来实现number++的问题。
volatile怎么禁止指令重排序?
什么叫指令重排序
计算机在执行程序时,为了提高性能,编译器和处理器常常会做指令重排,一把分为以下3种:

单线程环境里面能确保程序最终执行结果和代码顺序执行的结果一致。
多线程环境中线程交替执行,由于编译器优化重排的存在,两个线程使用的变量能否保持一致性是无法确定的,结果无法预测。
但是处理器在进行重新排序是必须要考虑指令之间的数据依赖性。
指令重排例子1
|
指令重排序例子2
|
这里有两个线程,分别调用initValue、updateValue这两个方法。
按照代码的顺序读,我们知道,当线程1调用完成initValue后,接着调用updateValue,那么代码3判断是成功的,然后a的最终值是6。
我们知道initValue方法的flag和a变量是没有依赖关系的,所以可能发生了指令重排,代码1和代码2的位置调换
public void initValue() {
flag = true;//1
a = 1;//2
}
那么假设线程1执行完成代码1后,进行了线程切换,线程2获得了执行机会,线程2去执行updateValue,那么if判断通过,这个时候,a的值是0,那么执行a+5,那么a最终结果是5
很明显跟上面的结果是6不相等。所以就会产生线程不安全问题。
解决方案,就是给flag,添加volatile修饰符,这样就能够通过给flag变量添加内存屏障的方式,禁止,指令重排。
你在哪些地方用到过volatile
1.首先我们知道 Atomic包下的类,大量使用到了volatile,例如AtomicInteger,AtomicReference等等。
2.单例模式DCL代码
|
以上是最终的实现代码,可以解决多线程下单例请求问题。
但是你可能有个问题,为什么需要双重判断机制?问题一
假设getInstance方法修改为:
public static SingletonDemo getInstance(){
synchronized (SingletonDemo.class){
if(instance==null){
instance=new SingletonDemo();
}
}
return instance;
}
你觉得,有什么问题?那就是可能会引发多余的请求加锁操作,假设instance实例已经初始化了,但是每一次线程访问getInstance方法的时候,都会请求锁,这样就会耗费时间。所以我们需要在最外一层再包裹一个if判断。如果已经初始化,那么就直接返回。
那为什么最里层也要判断一下呢?问题二
假设剔除最里层的if判断,最终代码如下:
|
那么这样会有什么问题呢?
假设有 三个线程同时执行到了,代码二这个位置,那么开始执行代码3,只有一个线程能获取锁,然后实例化instance,然后返回instance,当前线程执行结束。这个时候,其他两个线程获得执行机会,也会执行到代码3,获取锁,然后又再次实例化instance。这个问题就出来,instance就不再是单例了。
总结
DCL(双端检锁) 机制不一定线程安全,原因是有指令重排的存在,加入volatile可以禁止指令重排。
假设有两个线程 A、B 同时调用 getInstance() 方法,他们会同时发现 instance == null ,于是同时对 SingletonDemo.class 加锁,此时 JVM 保证只有一个线程能够加锁成功(假设是线程 A),另外一个线程则会处于等待状态(假设是线程 B);线程 A 会创建一个 SingletonDemo实例,之后释放锁,锁释放后,线程 B 被唤醒,线程 B 再次尝试加锁,此时是可以加锁成功的,加锁成功后,线程 B 检查 instance == null 时会发现,已经创建过 SingletonDemo实例了,所以线程 B 不会再创建一个 SingletonDemo实例。
这看上去一切都很完美,无懈可击,但实际上这个 getInstance() 方法并不完美。问题出在哪里呢?出在 new 操作上,我们以为的 new 操作应该是:
- 分配一块内存 M;
- 在内存 M 上初始化 SingletonDemo 对象;
- 然后 M 的地址赋值给 instance 变量。
因为第2、第3步骤没有什么关系(没有相互依赖),那么是可以调换顺序的
但是实际上优化后的执行路径却是这样的:
- 分配一块内存 M;
- 将 M 的地址赋值给 instance 变量;
- 最后在内存 M 上初始化 SingletonDemo对象。
优化后会导致什么问题呢?我们假设线程 A 先执行 getInstance() 方法,当执行完指令 2 时恰好发生了线程切换,切换到了线程 B 上;如果此时线程 B 也执行 getInstance() 方法,那么线程 B 在执行第一个判断时会发现 instance != null ,所以直接返回 instance,而此时的 instance 是没有初始化过的,如果我们这个时候访问 instance 的成员变量就可能触发空指针异常。

线程A进入第二个判空条件,进行初始化时,发生了时间片切换,即使没有释放锁,线程B刚要进入第一个判空条件时,发现条件不成立,直接返回instance引用,不用去获取锁。如果对instance进行volatile语义声明,就可以禁止指令重排序,避免该情况发生。
对于CPU缓存和内存的疑问,CPU缓存不存在于内存中的,它是一块比内存更小、读写速度更快的芯片,至于什么时候把数据从缓存写到内存,没有固定的时间,同样地,对于有volatile语义声明的变量,线程A执行完后会强制将值刷新到内存中,线程B进行相关操作时会强制重新把内存中的内容写入到自己的缓存,这就涉及到了volatile的写入屏障问题,当然也就是所谓happen-before问题。
好的总结文档:https://dzone.com/articles/java-volatile-keyword-0
MESI cpu缓存一致性协议!!!重要!!!!保证了可见性
MESI协议是一种基于无效的缓存一致性协议,他是基于硬件级别的优化
什么是基于无效呢?
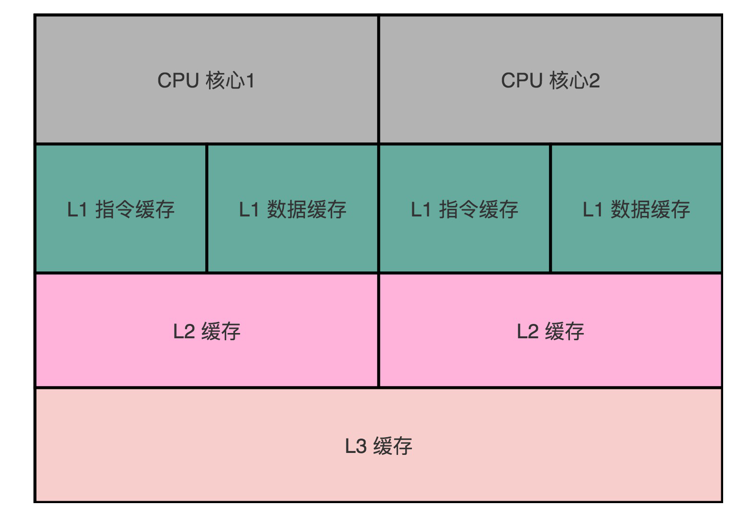
首先讲一下CPU和缓存的关系。计算机在数据处理或信号控制的时候,常与内存进行数据访问,但是内存和CPU的速度差别很大,所以会造成CPU资源浪费问题,为了解决两者的速度不匹配,所以在两者之间加了L1、L2、L3等缓存。在多核计算机中有多个CPU,每个CPU都有自己的缓存,所以就会造成缓存的数据不一致问题。
在早期解决缓存不一致是对总线使用LOCK(I/O总线)#锁,使得CPU访问某个变量的时候,其他CPU无法访问。但是这种效率很低。
MESI的主要思想:当CPU写数据时,如果该变量是共享数据,给其他CPU发送信号,使得其他的CPU中的该变量的缓存行无效。
执行写操作的时候有两种策略,一种是write-back caches,另一种是write-through caches。
MESI支持write-back。
|
|
Write through就是直接写回主存
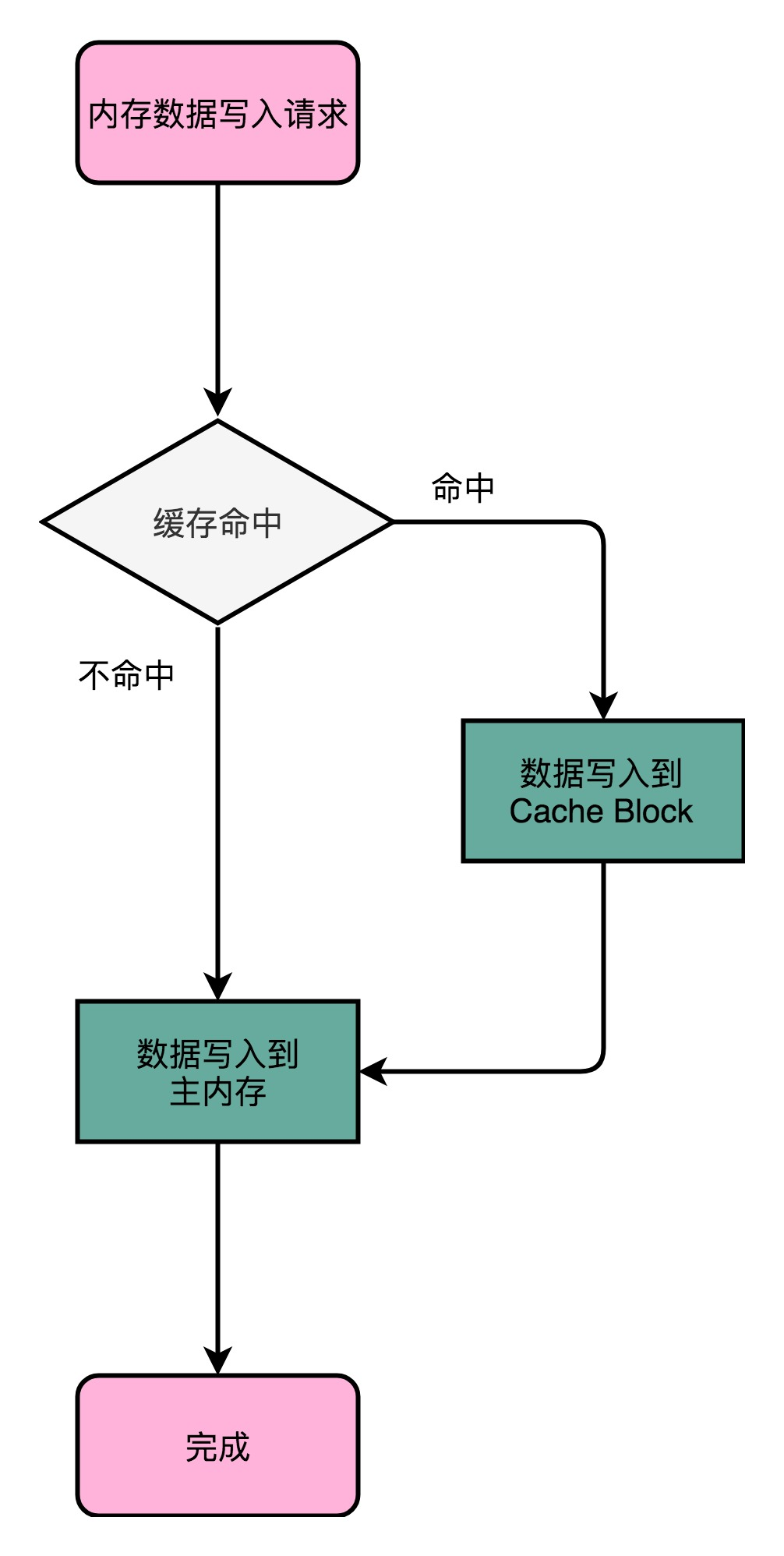
最简单的一种写入策略,叫作写直达(Write-Through)。在这个策略里,每一次数据都要写入到主内存里面。在写直达的策略里面,写入前,我们会先去判断数据是否已经在 Cache 里面了。如果数据已经在 Cache 里面了,我们先把数据写入更新到 Cache 里面,再写入到主内存里面;如果数据不在 Cache 里,我们就只更新主内存。
写直达的这个策略很直观,但是问题也很明显,那就是这个策略很慢。无论数据是不是在 Cache 里面,我们都需要把数据写到主内存里面。这个方式就有点儿像我们上面用 volatile 关键字,始终都要把数据同步到主内存里面。
Write back就是先标记不写回,等到使用的时候再写回主存。
这个时候,我们就想了,既然我们去读数据也是默认从 Cache 里面加载,能否不用把所有的写入都同步到主内存里呢?只写入 CPU Cache 里面是不是可以?
当然是可以的。在 CPU Cache 的写入策略里,还有一种策略就叫作写回(Write-Back)。这个策略里,我们不再是每次都把数据写入到主内存,而是只写到 CPU Cache 里。只有当 CPU Cache 里面的数据要被“替换”的时候,我们才把数据写入到主内存里面去。
写回策略的过程是这样的:如果发现我们要写入的数据,就在 CPU Cache 里面,那么我们就只是更新 CPU Cache 里面的数据。同时,我们会标记 CPU Cache 里的这个 Block 是脏(Dirty)的。所谓脏的,就是指这个时候,我们的 CPU Cache 里面的这个 Block 的数据,和主内存是不一致的。
如果我们发现,我们要写入的数据所对应的 Cache Block 里,放的是别的内存地址的数据,那么我们就要看一看,那个 Cache Block 里面的数据有没有被标记成脏的。如果是脏的话,我们要先把这个 Cache Block 里面的数据,写入到主内存里面。然后,再把当前要写入的数据,写入到 Cache 里,同时把 Cache Block 标记成脏的。如果 Block 里面的数据没有被标记成脏的,那么我们直接把数据写入到 Cache 里面,然后再把 Cache Block 标记成脏的就好了。
在用了写回这个策略之后,我们在加载内存数据到 Cache 里面的时候,也要多出一步同步脏 Cache 的动作。如果加载内存里面的数据到 Cache 的时候,发现 Cache Block 里面有脏标记,我们也要先把 Cache Block 里的数据写回到主内存,才能加载数据覆盖掉 Cache。
可以看到,在写回这个策略里,如果我们大量的操作,都能够命中缓存。那么大部分时间里,我们都不需要读写主内存,自然性能会比写直达的效果好很多。
然而,无论是写回还是写直达,其实都还没有解决我们在上面 volatile 程序示例中遇到的问题,也就是多个线程,或者是多个 CPU 核的缓存一致性的问题(就是如果两个线程都想写回内存,那么怎么解决这个问题)。这也就是我们在写入修改缓存后,需要解决的第二个问题。
要解决这个问题,我们需要引入一个新的方法,叫作 MESI 协议。这是一个维护缓存一致性协议。这个协议不仅可以用在 CPU Cache 之间,也可以广泛用于各种需要使用缓存,同时缓存之间需要同步的场景下。
什么 叫缓存一致性问题
以下是多核cpu的cache缓存结构,一般而言多核 CPU 里的每一个 CPU 核,都有独立的属于自己的 L1 Cache 和 L2 Cache。多个 CPU 之间,只是共用 L3 Cache 和主内存。
那什么是缓存一致性呢?我们拿一个有两个核心的 CPU,来看一下。你可以看这里这张图,我们结合图来说。
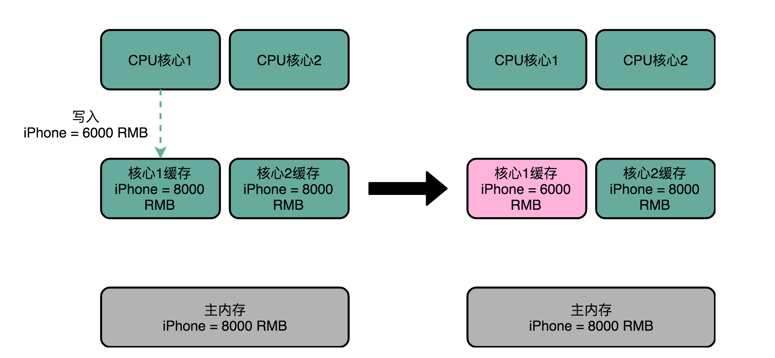
比方说,iPhone 降价了,我们要把 iPhone 最新的价格更新到内存里。为了性能问题,它采用了上一讲我们说的写回策略,先把数据写入到 L2 Cache 里面,然后把 Cache Block 标记成脏的。这个时候,数据其实并没有被同步到 L3 Cache 或者主内存里。1 号核心希望在这个 Cache Block 要被交换出去的时候,数据才写入到主内存里。
如果我们的 CPU 只有 1 号核心这一个 CPU 核,那这其实是没有问题的。不过,我们旁边还有一个 2 号核心呢!这个时候,2 号核心尝试从内存里面去读取 iPhone 的价格,结果读到的是一个错误的价格。这是因为,iPhone 的价格刚刚被 1 号核心更新过。但是这个更新的信息,只出现在 1 号核心的 L2 Cache 里,而没有出现在 2 号核心的 L2 Cache 或者主内存里面。这个问题,就是所谓的缓存一致性问题,1 号核心和 2 号核心的缓存,在这个时候是不一致的。
为了解决这个缓存不一致的问题,我们就需要有一种机制,来同步两个不同核心里面的缓存数据。那这样的机制需要满足什么条件呢?我觉得能够做到下面两点就是合理的。
第一点叫写传播(Write Propagation)。写传播是说,在一个 CPU 核心里,我们的 Cache 数据更新,必须能够传播到其他的对应节点的 Cache Line 里。
第二点叫事务的串行化(Transaction Serialization),事务串行化是说,我们在一个 CPU 核心里面的读取和写入,在其他的节点看起来,顺序是一样的。
第一点写传播很容易理解。既然我们数据写完了,自然要同步到其他 CPU 核的 Cache 里。但是第二点事务的串行化,可能没那么好理解,我这里仔细解释一下。
我们还拿刚才修改 iPhone 的价格来解释。这一次,我们找一个有 4 个核心的 CPU。1 号核心呢,先把 iPhone 的价格改成了 5000 块。差不多在同一个时间,2 号核心把 iPhone 的价格改成了 6000 块。这里两个修改,都会传播到 3 号核心和 4 号核心。
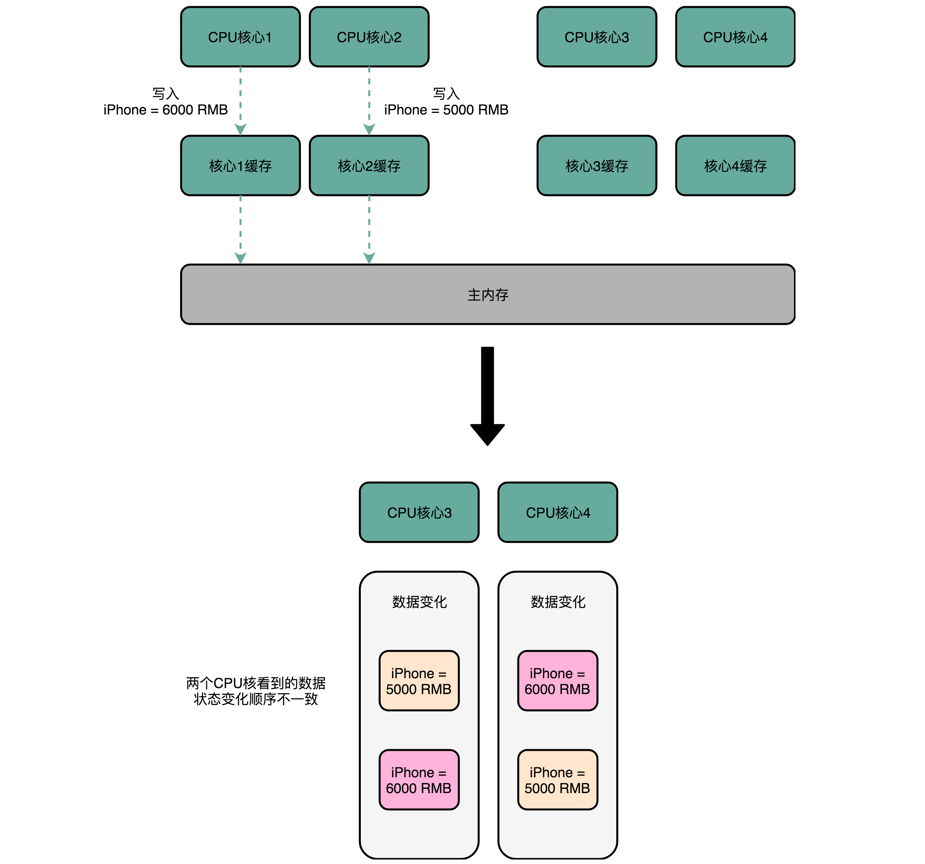
我们发现,这样还是会导致,数据的不一致性。
事实上,我们需要的是,从 1 号到 4 号核心,都能看到相同顺序的数据变化。比如说,都是先变成了 5000 块,再变成了 6000 块。这样,我们才能称之为实现了事务的串行化。
而在 CPU Cache 里做到事务串行化,需要做到两点,第一点是一个 CPU 核心对于数据的操作,需要同步通信给到其他 CPU 核心。第二点是,如果两个 CPU 核心里有同一个数据的 Cache,那么对于这个 Cache 数据的更新,需要有一个“锁”的概念。只有拿到了对应 Cache Block 的“锁”之后,才能进行对应的数据更新。接下来,我们就看看实现了这两个机制的 MESI 协议。
总线嗅探机制和 MESI 协议
要解决缓存一致性问题,首先要解决的是多个 CPU 核心之间的数据传播问题。最常见的一种解决方案呢,叫作总线嗅探(Bus Snooping)。这个名字听起来,你多半会很陌生,但是其实特很好理解。
这个策略,本质上就是把所有的读写请求都通过总线(Bus)广播给所有的 CPU 核心,然后让各个核心去“嗅探”这些请求,再根据本地的情况进行响应。
总线本身就是一个特别适合广播进行数据传输的机制,所以总线嗅探这个办法也是我们日常使用的 Intel CPU 进行缓存一致性处理的解决方案。
基于总线嗅探机制,其实还可以分成很多种不同的缓存一致性协议。不过其中最常用的,就是今天我们要讲的 MESI 协议。和很多现代的 CPU 技术一样,MESI 协议也是在 Pentium 时代,被引入到 Intel CPU 中的。
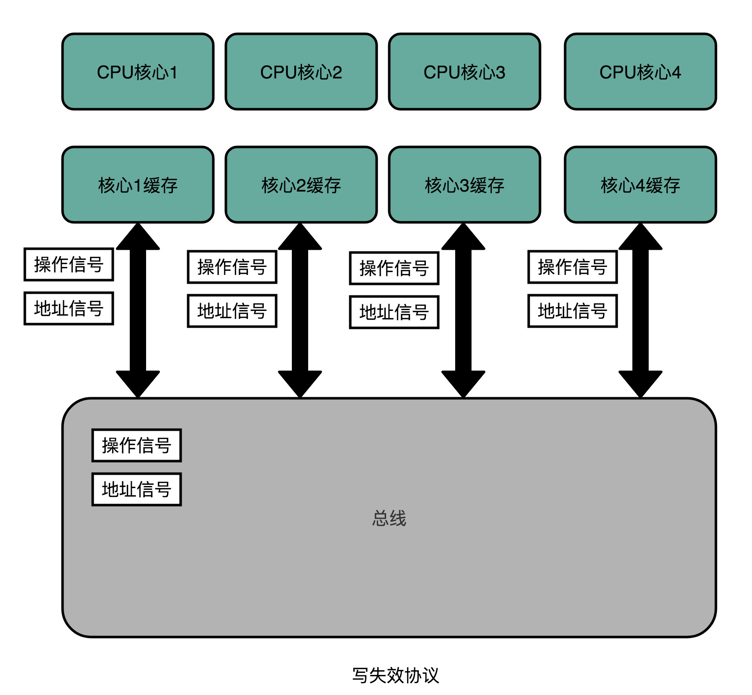
MESI 协议,是一种叫作写失效(Write Invalidate)的协议。在写失效协议里,只有一个 CPU 核心负责写入数据,其他的核心,只是同步读取到这个写入。在这个 CPU 核心写入 Cache 之后,它会去广播一个“失效”请求告诉所有其他的 CPU 核心。其他的 CPU 核心,只是去判断自己是否也有一个“失效”版本的 Cache Block,然后把这个也标记成失效的就好了。
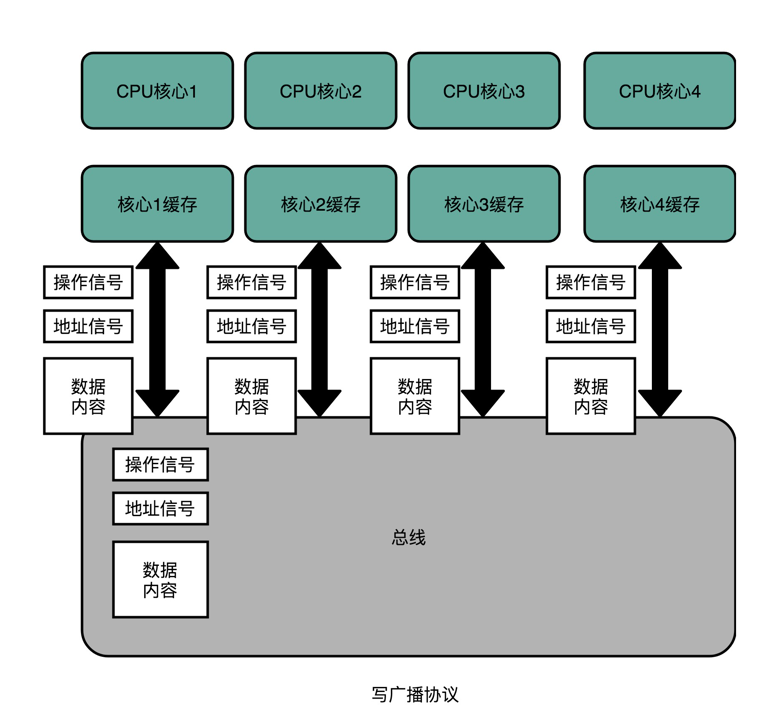
相对于写失效协议,还有一种叫作写广播(Write Broadcast)的协议。在那个协议里,一个写入请求广播到所有的 CPU 核心,同时更新各个核心里的 Cache。
写广播在实现上自然很简单,但是写广播需要占用更多的总线带宽。写失效只需要告诉其他的 CPU 核心,哪一个内存地址的缓存失效了,但是写广播还需要把对应的数据传输给其他 CPU 核心。
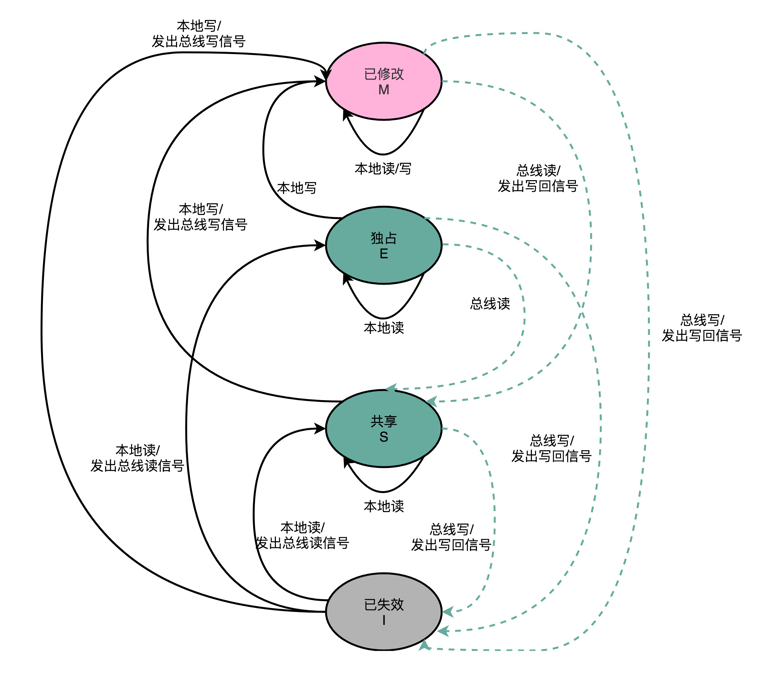
MESI 协议的由来呢,来自于我们对 Cache Line 的四个不同的标记,分别是:
- M:代表已修改(Modified)
- E:代表独占(Exclusive)
- S:代表共享(Shared)
- I:代表已失效(Invalidated)
我们先来看看“已修改”和“已失效”,这两个状态比较容易理解。所谓的“已修改”,就是我们上一讲所说的“脏”的 Cache Block。Cache Block 里面的内容我们已经更新过了,但是还没有写回到主内存里面。而所谓的“已失效“,自然是这个 Cache Block 里面的数据已经失效了,我们不可以相信这个 Cache Block 里面的数据。
然后,我们再来看“独占”和“共享”这两个状态。这就是 MESI 协议的精华所在了。无论是独占状态还是共享状态,缓存里面的数据都是“干净”的。这个“干净”,自然对应的是前面所说的“脏”的,也就是说,这个时候,Cache Block 里面的数据和主内存里面的数据是一致的。
那么“独占”和“共享”这两个状态的差别在哪里呢?这个差别就在于,在独占状态下,对应的 Cache Line 只加载到了当前 CPU 核所拥有的 Cache 里。其他的 CPU 核,并没有加载对应的数据到自己的 Cache 里。这个时候,如果要向独占的 Cache Block 写入数据,我们可以自由地写入数据,而不需要告知其他 CPU 核。
在独占状态下的数据,如果收到了一个来自于总线的读取对应缓存的请求,它就会变成共享状态。这个共享状态是因为,这个时候,另外一个 CPU 核心,也把对应的 Cache Block,从内存里面加载到了自己的 Cache 里来。
而在共享状态下,因为同样的数据在多个 CPU 核心的 Cache 里都有。所以,当我们想要更新 Cache 里面的数据的时候,不能直接修改,而是要先向所有的其他 CPU 核心广播一个请求,要求先把其他 CPU 核心里面的 Cache,都变成无效的状态,然后再更新当前 Cache 里面的数据。这个广播操作,一般叫作 RFO(Request For Ownership),也就是获取当前对应 Cache Block 数据的所有权。
有没有觉得这个操作有点儿像我们在多线程里面用到的读写锁。在共享状态下,大家都可以并行去读对应的数据。但是如果要写,我们就需要通过一个锁,获取当前写入位置的所有权。
整个 MESI 的状态,可以用一个有限状态机来表示它的状态流转。需要注意的是,对于不同状态触发的事件操作,可能来自于当前 CPU 核心,也可能来自总线里其他 CPU 核心广播出来的信号。我把对应的状态机流转图放在了下面,你可以对照着Wikipedia 里面 MESI 的内容,仔细研读一下。
好的文档:https://www.cnblogs.com/yanlong300/p/8986041.html
https://www.jianshu.com/p/0e036fa7af2a
https://www.cnblogs.com/ynyhl/p/12119690.html 不错
面试中如果问到你对volatile的理解?
那么首先你应该从内存模型,原子性,有序性,可见性的理解,然后才是volatile关键字的理解和他解决的问题。
,
synchronized的对象头核心知识
synchronized(obj)到底锁的是什么 ? - 对象头
|
synchronized到底锁的是整个业务代码块还是obj?
我们知道synchronized锁住的是obj对象,达到互斥的效果,那么在那里记录是那个线程锁住的呢?。而且synchronized是会锁升级的,那么在哪里记录这些锁的信息?哪里记录线程对obj对象上锁成功呢?
举个例子,我们知道ReentrantLock的lock方法,是通过对state的cas操作标识是否上锁成功,state如果能从0设置成1,那么说明上锁成功,如果多次重入,那么state标识重入次数。
我们发现单从这段代码synchronized (obj),他并没有像lock 对象那样,有个成员属性state来做一些锁的标志和判断。而且synchronized 只是一个关键字,那么只有一种解释,那就是,加锁的信息,肯定是在obj对象里面保存着!!
换句话说,我们的问题是:如果某个线程对obj对象加锁成功,那么他是怎么标记加锁成功的,到底修改了obj对象什么信息,来表示加锁成功?
这里先说结论:加锁实际上是改变了对象的对象头!!
java对象的布局 - 计算对象大小
我们要了解对象头,那么首先首当其冲就要先了解一下对象的构成。首先我们可以确定,对象的属性肯定是构成对象的一部分。
|
除了对象属性之外,还有对象头和数据对齐两个模块。
也就是说对象是由:对象属性、对象头、数据对齐三个组件构成。
其中对象头是肯定存在的,但是对象属性和数据对齐却不一定存在。一个对象可以没有成员属性,这个我们是知道的,那么数据对齐是什么意思呢?我们首先要明确,java定义对象的大小时,规定,对象的字节大小必须是8的倍数。
那么数据对齐就是为了凑够8的倍数而来的。举个例子:
|
那么上面student对象单从成员属性而言,一共是占了5个字节(这里先暂时不考虑对象头),那么很明显5不是8的倍数。所以需要补上3个字节,一共是8个字节,那么就是8的倍数。那么这里所说的补上3个字节,就是数据对齐模块的大小和作用。
换言之,假设对象成员属性的大小本身就是8的倍数,那么数据对齐也就不存在了。
所以说,对象的布局中,至于对象头是固定存在的,其他两个是不一定存在。
也就是说,一个对象的大小,等于这三个组成的大小之和。
怎么证明对象是由这三个部分组成?
接下来我们通过一个工具类来输出对象的信息,从而证明。
|
//计算对象大小
|
输出:
Running 64-bit HotSpot VM.//此时表示是64位虚拟机上,因为32位虚拟机下面的输出会有不同
Using compressed oop with 0-bit shift.、、
Using compressed klass with 3-bit shift.//开启指针压缩
Objects are 8 bytes aligned.
Field sizes by type: 4, 1, 1, 2, 2, 4, 4, 8, 8 [bytes]
Array element sizes: 4, 1, 1, 2, 2, 4, 4, 8, 8 [bytes]
com.kingge.obj.Obj object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 05 c0 00 20 (00000101 11000000 00000000 00100000) (536920069)
12 4 int Obj.value 0
16 1 boolean Obj.flag false
17 7 (loss due to the next object alignment)
Instance size: 24 bytes
Space losses: 0 bytes internal + 7 bytes external = 7 bytes total
可以看到一共是24个字节,其中对象头是12个字节,两个成员变量一共是5个字节,那么因为加起来17个字节,并不是8的倍数,那么需要数据对齐,于是加上7个字节的数据对齐。
从而证明了,我们那上面所说的结论是正确的。
假设对象修改为:
|
输出:
com.kingge.obj.Obj object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 05 c0 00 20 (00000101 11000000 00000000 00100000) (536920069)
12 4 int Obj.value 0
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
你会发现,数据对齐,没有了?那是因为,刚好属性+对象头一共是16个字节,是8的倍数。
总结一下
对象是由:对象头(大小固定,64位虚拟机下一共占12字节),成员属性(大小根据数据类型决定),数据对齐(不一定存在)。
那么对象的大小就是由着三个部分组成。
对象头的构成
在上面的分析中,我们得到64位虚拟机下,对象头的大小是12字节,一共是96位。
我们通过查看一下官方文档,获得对象头构成:
http://openjdk.java.net/groups/hotspot/docs/HotSpotGlossary.html
|
也就是说:对象头包含了这些信息,堆对象的布局、类型、GC状态、同步状态和标识哈希码的基本信息。我么终于发现了,在文章最开始提出的问题的答案,那就是在那里记录了加锁的信息?就是这里的同步状态,而且我们发现,对象头还保存了对象hashcode的值。
我们知道了对象头包含的信息,但是并没有说明对象头由哪些部分组成?
上面的翻译已经说了 Consists of two words。也就是对象头由两个部分组成:klass pointer和mark word
|
那么markword他的结构是怎么样的呢?我们通过看源码的形式查看的他的结构
openjdk\hotspot\src\share\vm\oops\markOop.hpp
|
可以得到,markword的构成是:unused:25 hash:31 –>| unused:1 age:4 biased_lock:1 lock:2
特殊提醒,我们在JVM中讲到,为什么当对象年龄达到15的时候,才会进入老年代。那么15这个数字是怎么得来的,就是这里的age:4,他占四位,四位能够表达的最大数是15,这就是-XX:MaxTenuringThreshold选项最大值为15的原因
也就是25+31+1+4+1+2 == 64bit,也就是说在64位对象头中,markword占64位,那么也就意味着,对象类型指针kclass pointer占32bit(96-64)
特殊提醒!!!!,有些时候我们发现kclass pointer的大小是:64位,也就是需要8个字节,并不是上面所说的需要32位。这两种说法都是对的,因为jvm默认开启了指针压缩,会把kclass pointer压缩成4个字节。如果没有卡其指针压缩,那么就是8个字节。
那么怎么知道jvm 是否开启了指针压缩呢?System.out.println( VM.current().details() ); 通过这个命令就可以输出,jvm当前信息。
检验kclass pointer未压缩前大小是否是8个字节
测试例子:
|
输出:
|
可以看到输出:# Using compressed klass with 3-bit shift.//表示默认开启指针压缩
此时,对象头大小是12字节,其中markword占8个字节,对象指针kclass pointer 占4个字节。
下面我们去掉指针压缩,再次运行。
使用jvm参数去掉指针压缩: -XX:-UseCompressedOops 。
输出:
|
我们发现,此时,对象头大小是16字节,其中markword固定占8个字节,那么很明显剩下的8个字节就是对象指针kclass pointer 的大小。
得证!!!未开启压缩的情况下,对象指针在64位虚拟机下,占8个字节。
markword构成
我们知道markword在64位虚拟机下,是占8个字节。
首先我们要知道,对象一共有几个状态?
- 初始状态 - 刚new出来
- 成为偏向锁
- 成为轻量级锁
- 成为重量级锁
- GC标记-表示可垃圾回收
再来看一下 markword结构:
unused:25 hash:31 –>| unused:1 age:4 biased_lock:1 lock:2
从上面可以看到,锁标记(lock)占了2位,那么两位的二级制,只有四种可能,00,01,10,11.那么他怎么表示上面这五种状态呢?
通过biased_lock偏向锁的1个标志位,来表示,对象的五种状态,右下图可见。
偏向锁和无锁状态表示为同一个状态(lock都是01),然后根据图中偏向锁的标识再去标识是无锁还是偏向锁状态;
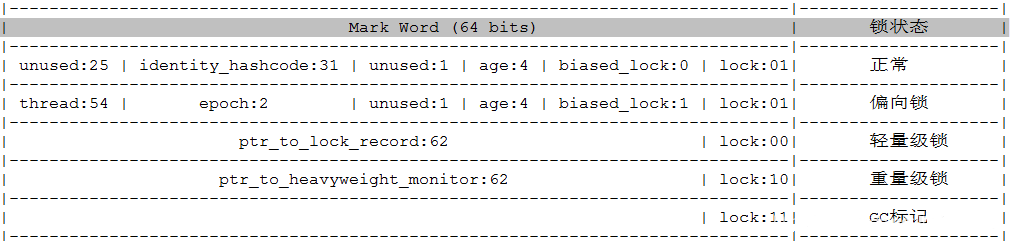
下面我们拉分析一下在初始状态下,对象的对象头的markword信息。
com.kingge.obj.Obj object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 05 c0 00 20 (00000101 11000000 00000000 00100000) (536920069)
12 4 int Obj.value 0
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
从上面的图再根据下面输出的对象结构信息,我们可以得出,markword 一共是64位,八个字节。剩下的4个字节就是kclass pointer(也就是Obj.class的指针)
markword也就是这64位:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 05 c0 00 20 (00000101 11000000 00000000 00100000)
那么其中这8个字节,就是存储的markword的信息。
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
剩下的未标黑色的8位保存的就是:unused:1 age:4 biased_lock:1 lock:2
这八位等于00000001,那么正好跟,初始化状态的对象的状态是一样的。前六位都是0,lock等于01表示正常(因为上面的代码中obj对象是刚new出来的。unuseed等于0,那么gc年龄肯定是0,也就是age的四位都是0,biaed_lock也是0,lock等于01)

那为什么在上面输出的31位的hashcode都是0?
原因是没有调用对象的hashcode方法生成hashcode。
测试代码修改为:
|
输出:
|
你会发现,输出的对象结构信息中,hashcode的值,已经存在。且为:37bba400。
跟上面的value字段输出一致。
模拟偏向锁和轻量级锁对象头
测试代码:
|
输出:
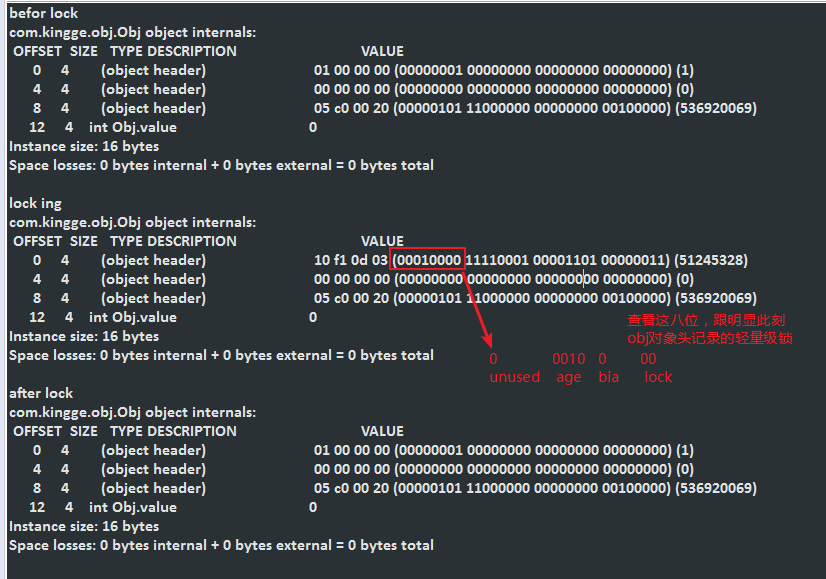
如果把上面的 // Thread.sleep(5000); 注释放开或者设置-XX:BiasedLockingStartupDelay=0,那么此刻输出的是偏向锁的信息,前八位是:0 0000 1 01
为什么不是偏向锁
为什么呢?从上面代码看,只有一个main线程在获取锁啊,应该是偏向锁才对啊?
经过翻hotspot源码发现:
路径: http://hg.openjdk.java.net/jdk/jdk/file/6659a8f57d78/src/hotspot/share/runtime/globals.hpp
|
想想为什么偏向锁会延迟?
我们来看官方解释:
|
英文大概翻译为: 当jvm启动记载资源的时候,初始化的对象加偏向锁会耗费资源,减少大量偏向锁撤销的成本(jvm的偏向锁的优化)
这就解释了加上睡眠5000ms,偏向锁就会出现的原因;
为了方便我们测试我们可以直接通过修改jvm的参数来禁止偏向锁延迟(不用在代码睡眠了):
|
注意:这块严谨来说,在jdk 1.6之后,关于使用偏向锁和轻量级锁,jvm是有优化的,在没有禁止偏向锁延迟的情况下,使用的是轻量级锁;禁止偏向锁延迟的话,使用的是偏向锁;
总而言之:因为jvm 在启动的时候需要加载资源,这些对象加上偏向锁没有任何意义啊,减少了大量偏向锁撤销的成本;所以默认就把偏向锁延迟了4000ms;
如果还不能确定是否延迟,那么我们可以通过查看jvm默认启动参数来查看:
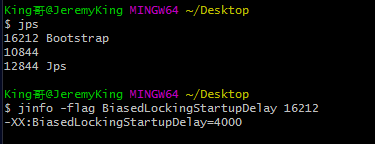
|
比较偏向锁和轻量级锁性能
测试轻量级锁:
|
测试偏向锁,只需要运行的时候指定:-XX:BiasedLockingStartupDelay=0,表示不需要延迟设置偏向锁。
为什么呢?我们知道偏向锁是支持重入的,意思就是,假设下次获取锁的线程还是之前的线程,那么不需要在申请锁,只需要增加重入次数即可。这个假设是只有一个线程 需要获取锁的情况下。
但是如果存在多个线程获取锁,那么锁会升级,升级为轻量级锁,因为轻量级锁的获取及释放依赖多次CAS原子指令,而偏向锁只需要在置换ThreadID的时候依赖一次CAS原子指令即可。
重量级锁
测试代码:
|
输出:
|
分析锁的前八位:
|
上面的分析应该很容易看得懂,那么我们注意,打问号的地方。按道理main线程执行完sync,也就意味着thread线程在这之前也已经释放了锁(不然sync方法也无法得到锁执行),objLock此刻是没有线程去锁住才对,那么应该是是无锁状态,那为什么还是输出的是重量级锁的信息呢?
是因为重量级锁释放会有延迟,可以在sync()方法中加入睡眠。
|
//此时再看输出,你会发现。
|
偏向锁的epoch作用
这里的 epoch 值是一个什么概念呢?
- 我们先从偏向锁的撤销讲起。当请求加锁的线程和锁对象标记字段保持的线程地址不匹配时(而且 epoch 值相等,如若不等,那么当前线程可以将该锁重偏向至自己),Java 虚拟机需要撤销该偏向锁。这个撤销过程非常麻烦,它要求持有偏向锁的线程到达安全点,再将偏向锁替换成轻量级锁;
- 如果某一类锁对象的总撤销数超过了一个阈值(对应 jvm参数 -XX:BiasedLockingBulkRebiasThreshold,默认为 20),那么 Java 虚拟机会宣布这个类的偏向锁失效;(这里说的就是批量重偏向)
JVM源码:
|
- 具体的做法便是在每个类中维护一个 epoch 值,你可以理解为第几代偏向锁。当设置偏向锁时,Java 虚拟机需要将该 epoch 值复制到锁对象的标记字段中;
- 在宣布某个类的偏向锁失效时,Java 虚拟机实则将该类的 epoch 值加 1,表示之前那一代的偏向锁已经失效。而新设置的偏向锁则需要复制新的 epoch 值;
- 为了保证当前持有偏向锁并且已加锁的线程不至于因此丢锁,Java 虚拟机需要遍历所有线程的 Java 栈,找出该类已加锁的实例,并且将它们标记字段中的 epoch 值加 1。该操作需要所有线程处于安全点状态;
- 如果总撤销数超过另一个阈值(对应 jvm 参数 -XX:BiasedLockingBulkRevokeThreshold,默认值为 40),那么 Java 虚拟机会认为这个类已经不再适合偏向锁。此时,Java 虚拟机会撤销该类实例的偏向锁,并且在之后的加锁过程中直接为该类实例设置轻量级锁(这里说的就是偏向批量撤销)
JVM源码:
|
锁升级过程
所谓锁的升级、降级,就是 JVM 优化 synchronized 运行的机制,当 JVM 检测到不同的竞争状况时,会自动切换到适合的锁实现,这种切换就是锁的升级、降级:
- 当没有竞争出现时,默认会使用偏向锁。JVM 会利用 CAS 操作(compare and swap),在对象头上的 Mark Word 部分设置线程 ID,以表示这个对象偏向于当前线程,所以并不涉及真正的互斥锁。这样做的假设是基于在很多应用场景中,大部分对象生命周期中最多会被一个线程锁定,使用偏向锁可以降低无竞争开销。
- 如果有另外的线程试图锁定某个已经被偏向过的对象,JVM 就需要撤销(revoke)偏向锁,并切换到轻量级锁实现。轻量级锁依赖 CAS 操作 Mark Word 来试图获取锁,如果重试成功,就使用轻量级锁;否则,进一步升级为重量级锁
膨胀过程的实现比较复杂,大概实现过程如下:
1、整个膨胀过程在自旋下完成;
2、mark->has_monitor()方法判断当前是否为重量级锁,即Mark Word的锁标识位为 10,如果当前状态为重量级锁,执行步骤(3),否则执行步骤(4);
3、mark->monitor()方法获取指向ObjectMonitor的指针,并返回,说明膨胀过程已经完成;
4、如果当前锁处于膨胀中,说明该锁正在被其它线程执行膨胀操作,则当前线程就进行自旋等待锁膨胀完成,这里需要注意一点,虽然是自旋操作,但不会一直占用cpu资源,每隔一段时间会通过os::NakedYield方法放弃cpu资源,或通过park方法挂起;如果其他线程完成锁的膨胀操作,则退出自旋并返回;
5、如果当前是轻量级锁状态,即锁标识位为 00,膨胀过程如下:
- 通过omAlloc方法,获取一个可用的ObjectMonitor monitor,并重置monitor数据;
- 通过CAS尝试将Mark Word设置为markOopDesc:INFLATING,标识当前锁正在膨胀中,如果CAS失败,说明同一时刻其它线程已经将Mark Word设置为markOopDesc:INFLATING,当前线程进行自旋等待膨胀完成;
- 如果CAS成功,设置monitor的各个字段:_header、_owner和_object等,并返回;
6、如果是无锁,重置监视器值;
好的相关文档
https://www.cnblogs.com/JonaLin/p/11571482.html#autoid-2-0-0 非常推荐!!!!!
https://www.cnblogs.com/yrjns/p/12152975.html
题外话:Java中boolean类型占几个字节,你知道吗?
https://blog.csdn.net/amoscn/article/details/97377833
cas是什么 - 无锁并发安全实现 - 轻量级锁
概念
他就是比较并交换的缩写 - compareAndSet。他的作用就是通过比较期望值,来判断本次操作能否成功。
也就是说比较当前工作内存的值和主内存中的值,如果相等,那么执行相应的逻辑操作(临界区操作),如果不相等,那么一直比较到相同为止。
那么他究竟是什么呢?
我们来回忆一下AtomicInteger的compareAndSet方法。

第一个参数和第二个参数是相辅相成的,只有在第一个参数比较成功后,才能够成功赋值第二个参数的值。
那么第一个参数是跟谁比较呢?答案是,跟主内存中目前的值比较。
重要提示:首先我们要明确一点,那就是,线程对数据的操作,都是先把数据从主内存(电脑内存),读取出来,然后load自己的线程栈中,再进行自己的运算逻辑,然后线程结束后,再把新值写回主内存。(那么可想而知,多线程的情况下,必然会发生线程不安全问题,因为每个线程把自己的处理结果写回主内存的时机不同,导致结果出现各种变化)
接下来演示使用cas的例子:
|
输出是:
|
为什么第一次compareAndSet能成功,第二次就不行了呢?这是因为,初始的AtomicInteger的值是5,那么在主内存中就是5。第一次执行cas操作,所要表达的逻辑是,我要把atomicInteger修改为2019,但是我是要从5修改为2019。也就是说,主内存中的atomicInteger的值必须是5,我才能紧接着把atomicInteger修改为2019。
很明显在第一次cas操作之前,主内存中的atomicInteger一直是5, 所以比较成功。交换值,5修改为2019,成功写入主内存中的atomicInteger。
但是第二次cas操作,表达的是我要从5修改为2014,但是通过比较主内存中的atomicInteger,发现atomicInteger的值是2019,那么比较失败,值交换也相继失败。所以主内存中atomicInteger的值保持不变,还是2019。
也就是说,CAS的本质就是,先比较后交换。
我们接着查看一下compareAndSet的源码:
/**
* Atomically sets the value to the given updated value
* if the current value {@code ==} the expected value.
*
* @param expect the expected value
* @param update the new value
* @return {@code true} if successful. False return indicates that
* the actual value was not equal to the expected value.
*/
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}
this:就是当前的atomicInteger对象- AtomicInteger atomicInteger = new AtomicInteger(5);
valueOffset:我们知道atomicInteger的值是保存在value成员变量中,而且他是通过volatile修饰。而且这个值是在创建AtomicInteger之前(在调用构造器之前)通过静态代码块,进行赋值。目的就是求得,value成员变量在内存中的地址。
- static {
}try { valueOffset = unsafe.objectFieldOffset (AtomicInteger.class.getDeclaredField("value")); } catch (Exception ex) { throw new Error(ex); }
- static {
expect:我们的预期值,也即是5,也即是要更新为2019的条件值。那么value在主内存中现在的值是多少呢?怎么获取呢?
- 通过前两个参数获取,通过this和valueOffset,就可以定位到,value属性在内存中的地址,从而获取它的值。
update:要把内存中的值,更新update的值。
抽象出来的CAS的逻辑
CAS(V, E, N)
- V:要更新的变量,目前内存中的变量的值。
- E:预期值,条件值。要把v更新为n的条件值
- N:新值
如果V值等于E值,则将V值设为N值;如果V值不等于E值,说明其他线程做了更新,那么当前线程什么也不做。(放弃操作或重新读取数据)
疑问
compareAndSet方法,咋一看,是没有添加任何线程同步的处理,例如没有synchronized或者Lock,那么他是线程安全的么?
答案:是线程安全的,因为使用cas原理(一种硬件原语),cas就能够保证线程安全。
AtomicInteger的CAS底层原理
为什么cas能够保证线程安全?
首先回顾一下我们做过的一个实例:实现两个线程对一个数自增,例如各自对number(共享数据)增加一百万。我们知道如果不对自增方法添加synchronized(或者使用Lock),那么就会导致,最终得数是变化不断的,是不会出现预期的两百万的得值,而是一个游离变化不断得值,因为这个就是线程安全的问题。
通过学习我们知道有多种方案,解决线程安全问题:
通过给方法添加synchronized关键字
可以使用Lock来实现多线程同步问题。
也可以使用AtomicInteger来解决多线程同步问题。
前面两种,我们都已经测试过,但是AtomicInteger为什么能够保证线程安全?同时他是通过什么机制来保证线程安全?通过上面的学习我们知道 AtomicInteger 是通过CAS来保证线程安全,但是是怎么保证的?
那么我们可以通过AtomicInteger来推导出CAS的底层原理。
看实现代码:通过添加synchronized
|
答案,肯定是正确的,因为使用了synchronized内部锁,进行了线程安全的控制。
我们知道可以使用,AtomicInteger来实现相同的功能
|
我们发现add1方法,根本就没有添加synchronized关键字修饰,但是他为什么能够保证数值就是2000000呢?
通过查看上面的代码,我们发现是通过atomicInteger.incrementAndGet()解决了,number++在多线程访问下竟态线程安全问题。那么具体是怎么实现呢,往下看
通过查看incrementAndGet方法
/**
* Atomically increments by one the current value.
*
* @return the updated value
*/
public final int incrementAndGet() {
return unsafe.getAndAddInt(this, valueOffset, 1) + 1;
}
发现它内部实现是通过调用UnSafe类的方法。那么很明显UnSafe就是多线程同步的关键
通过上面的分析我们知道,unsafe.getAndAddInt(this, valueOffset, 1),this参数就是atomicInteger实例,valueOffset就是atomicInteger实例的成员变量value在内存中的偏移量(也就是内存地址 ),通过前两个参数,就可以获取当前value在主内存的值。,第三个参数就是自增1。
我们接着查看unsafe.getAndAddInt源码
|
1.首先看这个方法getAndAddInt,刚开始执行一次do操作,调用getIntVolatile方法
- 目的是获取当前的atomicInteger共享资源,对应的value值,在主内存中现在的值(因为可能有其他线程已经修改了它的值,所以要获取最新的值)。然后赋值给v变量。
2.然后进行while判断,这个就是核心的cas的原理关键,比较和交换。
compareAndSwapInt方法,一共有四个参数。第一个参数,就是atomicInteger共享资源(就是我们 AtomicInteger atomicInteger = new AtomicInteger(0)这里new出来的实例本身),保存自己首次从主内存中,捞取的value数据(因为我们知道,任何线程对数据的操作,都是先从主内存加载到自己的栈内存中,进行操作,也就是cas的expect值)
第二个参数:就是atomicInteger共享资源的value属性在内存的地址。
- 这样通过第一和第二参数,我们就可以获取cas的expect值。
第三个参数:就是目前value在主内存中的值。
第四个参数:就是update值,更新最新的值,v + delta。线程操作成功。
通过前面三个参数,我们就可以实现cas中的compare阶段,比较期望值跟主内存中value值,是否一致,如果一致,那么就直接更新值,实现cas的set阶段,更新成功,然后返回v变量的值(没有进行v + delta前的值)
如果比对失败,那么compareAndSwapInt返回false,那么while (!compareAndSwapInt(o, offset, v, v + delta));判断成功,然后接着进行do操作,无线循环,直到while判断成功。
我们在捋一下思路
假设线程A和线程B两个线程同时执行getAndAddInt操作(分别在不同的CPU上):
1.AtomicInteger里面的value原始值为3,即主内存中AtomicInteger的value为3,根据JMM模型,线程A和线程B各自持有一份值为3的value的副本分别到各自的工作内存.
2.线程A通过getIntVolatile(var1,var2) 拿到value值3,这时线程A被挂起.
3.线程B也通过getIntVolatile(var1,var2) 拿到value值3,此时刚好线程B没有被挂起并执行compareAndSwapInt方法比较内存中的值也是3 成功修改主内存的值为4 线程B打完收工 一切OK.
4.这是线程A恢复,执行compareAndSwapInt方法比较,发现自己手里的数值(3)和内存中的数字4不一致,说明该值已经被其他线程抢先一步修改了,那A线程修改失败,只能重新来一遍了.(while循环判断失败,重新进入do逻辑获取主内存的value值)
5.线程A重新获取value值,因为变量value是volatile修饰,所以其他线程对他的修改,线程A总是能够看到,线程A继续执行compareAndSwapInt方法进行比较替换,直到成功.
我们知道上述方法都是通过Unsafe类进行调用的,那么UnSafe是是什么?
是CAS的核心类 由于Java 方法无法直接访问底层 ,需要通过本地(native)方法来访问,UnSafe相当于一个后面,基于该类可以直接操作特额定的内存数据.UnSafe类在于sun.misc包中,其内部方法操作可以向C的指针一样直接操作内存,因为Java中CAS操作的助兴依赖于UNSafe类的方法.
注意UnSafe类中所有的方法都是native修饰的,也就是说UnSafe类中的方法都是直接调用操作底层资源执行响应的任务
变量ValueOffset,便是该变量在内存中的偏移地址,因为UnSafe就是根据内存偏移地址获取数据的。
那么cas到底是怎么保证了并发问题?
CAS的全称为Compare-And-Swap ,它是一条CPU并发原语。
它的功能是判断内存某个位置的值是否为预期值,如果是则更新为新的值,这个过程是原子的.
CAS并发原语提现在Java语言中就是sun.misc.UnSaffe类中的各个方法.调用UnSafe类中的CAS方法,JVM会帮我实现CAS汇编指令.这是一种完全依赖于硬件 功能,通过它实现了原子操作。
再次强调,由于CAS是一种系统原语。原语属于操作系统用于范畴,是由若干条指令组成,用于完成某个功能的一个过程,并且原语的执行必须是连续的,在执行过程中不允许中断,也即是说CAS是一条原子指令,不会造成所谓的数据不一致的问题.

也就是说,cas为什么能够保证并发安全,靠的就是底层的汇编命令,指令的原子性。
为什么使用cas不使用synchronized?
我们通过上面的源码知道,cas是不会加锁的,他是通过一个无线循环,来进行比对值,然后设置值的思路。这样就可以让多个线程在同一个时刻同时进入逻辑。
然而synchronized或者lock,只能在同一个时刻,只有一个线程获取锁后,才能进入逻辑。
所以并发上,cas更佳。但是synchronized至少能够保证,我做完一然后接着下一个,很稳定。cas虽然是可以大家一起做,但是不一定能成功。
但是cas只能够保证一个资源的并发安全,多个资源他无法保证。synchronized是可以保证多个资源的并发安全。
AtomicReference 实现对象的资源保护
我们知道java.util.concurrent.atomic包下提供了,多种通过cas实现并发安全的各种类。
那么我们之前已经使用了AtomicInteger,通过它可以保证某个int类型数据的并发安全。
但是如果共享资源是多个属性,或者说是一个对象的话,那么怎么办?那么就可以使用 AtomicReference
测试代码:
|
输出:
|
需要注意的是:这里需要注意下,这里的比对两个对象,比对的方式不是equals而是==,意味着比对的是内存的中地址,这个我们可以通过unsafe.compareAndSwapObject()方法查看,他是一个native方法。
CAS缺点
1.循环时间长开销很大,可能某个线程一直操作不成功,那么一直循环,对cpu造成压力大。
public final int getAndAddInt(Object o, long offset, int delta) {
int v;
do {
v = getIntVolatile(o, offset);
} while (!compareAndSwapInt(o, offset, v, v + delta));
return v;
}
2.只能保证一个共享变量的原子性。
你看代码,你会发现,他是无法保证多个共享资源的并发安全。但是synchronized是可以的,可以对一段代码进行并发安全控制。
3.引出来ABA问题

什么是ABA问题
cas算法实现的一个重要前提就是需要取出内存中某个时刻的数据并在当下时刻比较替换,那么在这个时间差内,会导致数据的变化。
比如说,一个线程从a从内存位置o中取出A,这个时候另一个线程b,也从内存中取出A,并且线程b进行了一些操作将主内存的A变成了B,然后线程b又将主内存中位置o的数据从B修改为了A。这个时候,线程a进行cas操作,发现主内存中仍然是A,然后线程a操作成功。
尽管线程a的cas操作成功,但是并不代表这个过程是没有问题的,也就是说cas值关注头尾,只要对应的上就操作成功。所以说ABA问题,是存在的,但是这个也不算是问题,因为有可能你的业务就是只关注头尾是否相同,中间不论发生什么,我都不在意。
怎么解决ABA问题
很明显,解决的思路就是,通过时间戳或者记录版本号的方式,只要修改一次版本号就记录一次,自增1。
实现方式就是通过,AtomicStampedReference,类。
|
输出:
|
atomic包下的工具类,都是基于CAS实现线程安全
ArrayList线程不安全解决
|
30个线程,共同操作list,那么就会出现下面的问题:Exception in thread "10" Exception in thread "26" java.util.ConcurrentModificationException
多个线程,进行add数据的时候,可能会报这个错误

这种情况就是因为add方法,可以让多个线程同时执行,那么某个线程正在写入list数组的某个下标时,其他写成也可能在下入同一个下标,那么这个时候就会触发并发修改异常。
那么怎么解决呢?
备选方案,使用Vector,vector提供了synchronized修饰的方法,需要加锁,并发能力下降。
我们可以使用 Collections.synchronizedList(list),通过传递一个list,然后他会返回一个线程安全的list给你,实际上返回的线程安全list内部实现,就是通过在方法内部加上synchronized的方式实现线程安全,他跟vector是一样的。
以上两个方案,如果公司都不建议使用,那么可以使用下面的类。
我们推荐使用 CopyOnWriteArrayList 类。查看他的add方法
/**
* Appends the specified element to the end of this list.
*
* @param e element to be appended to this list
* @return {@code true} (as specified by {@link Collection#add})
*/
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
发现他实际上就是通过ReentrantLock进行加锁和解锁,很简单,所以他能够解决并发问题。
我们在深入的看一下CopyOnWriteArrayList的源码:
/** The lock protecting all mutators */
final transient ReentrantLock lock = new ReentrantLock();
/** The array, accessed only via getArray/setArray. */
private transient volatile Object[] array;
可以看到他的成员属性有这两个,一个加锁的实例对象,一个保存list数据的 volatile类型的数组。
同理hashset和hashmap也是线程不安全的
那么他们的解决方案,其实跟ArrayList是一样的。
hashset线程不安全解决的方案是,可以使用Collections生成线程安全的set,那么也是可以使用CopyOnWriteArraySet(你会发现,他底层依赖的就是CopyOnWriteArrayList实现)。

hashmap的解决方案是:可以使用hashtable,或者Collections集合类生成 线程安全的map,那么也是可以使用ConcurrentHashMap
特别提示:hashset的底层实现是hashmap,但是hashset的add方法参数只有一个,hashmap的入参是一个k-v键值对,怎么回事?
原来hashset的k就是add方法的入参,但是我们只关注k,所以value的值,是一个恒定使用final修饰的new Object()对象。
HashMap源码解析
请查看<面试突击第三季.md>里面有完整分析
公平锁/非公平锁/可重入锁/递归锁/自旋锁谈谈你的理解?请手写一个自旋锁
公平锁和非公平锁
公平锁
是指多个线程按照申请锁的顺序来获取锁类似排队打饭 先来后到。
非公平锁
是指在多线程获取锁的顺序并不是按照申请锁的顺序,有可能后申请的线程比先申请的线程优先获取到锁,在高并发的情况下,有可能造成优先级反转或者饥饿现象。
并发包ReentrantLock的创建可以指定构造函数的boolean类型来得到公平锁或者非公平锁,默认是非公平锁。
|
synchronized和默认创建的lock都是非公平锁。
可重入锁(又名递归锁)

也就是说,同步方法内部,再去访问另一个同步方法,可以不用再请求锁,只需要记录重入次数即可,释放锁后减少重入次数即可 。(好处是这样就不会死锁)
ReentrantLock/synchronized就是一个典型的可重入锁。
可重入锁最大的作用就是避免死锁
例子一:使用synchronized实现可重入锁。
|
输出:
|
很明显sendSms是一个同步方法,在sendSms(外层函数)内部调用的sendEmail(内层函数)也是一个同步方法。那么假设线程获取锁后能够进入sendSms方法,那么在调用sendSms方法的时候,就不需要再申请锁了,所以锁时可以重复使用的,即是,可重入锁。
sendSms和sendEmail都是请求同一个锁资源(this),那么假设没有重入锁。程序运行,t1线程获取锁资源成功,那么执行 phone.sendSms(),接着调用sendEmail()方法,那么因为sendSms()还占据着this锁,很明显在调用sendEmail时会阻塞,sendEmail方法会等待sendSms方法释放资源,但是sendSms方法要等sendEmail方法执行完才释放资源,相互等待,产生死锁。
举个例子,你能用锁进入你家,那么进入你家的厕所,肯定是可以的,也就不要再开锁了。
需要注意的是:sendSms和sendSms本质上请求的都是同一把锁(Phone.class),所以是可以重入的。
例子二:使用Lock演示可重入锁
|
输出:
|
自旋锁 似锁非锁
我们之前,学过Unsafe和cas,就已经接触过自旋锁。

也就是说:自旋锁实现的本质,就是通过while循环加上cas方法实现。
其实自旋锁,也可以说,不是锁,这样说的很绕。我们先回顾一下,我们之前学习的,内部锁(synchronized)和显示锁(lock),当多个线程访问共享资源时,只有一个线程能够获取锁,然后进入临界区,操作逻辑。那么这个时候其他锁,是在锁池等待,是阻塞的。也就是说,其他线程,根本没有进入临界区的机会。
但是自旋锁,不一样,他是允许所有,线程都进入临界区,操作共享资源数据,没有线程是阻塞的。他实际上就是乐观锁的意思,就是先尝试修改数据,如果不行再请求锁。
他是通过cas硬件原语的,机制,来实现,原子性。通过比较预期值和实际值是否一致,来决定是否做更新操作。如果一致,那么更新值,while循环结束,返回true,线程结束。
如果不一致,那么while循环,持续判断,直到判断成功。
实现一个自旋锁
那么我们知道,自旋锁的本质就是,while加上cas。
|
输出:
|
可以看到,虽然A、B同时加锁,但是最终只有A线程获取了锁,那么也就意味着,线程B在while循环里面自旋。直到线程A执行完,业务逻辑后,解锁。线程Bwhile循环结束,获取锁,然后执行业务逻辑,最后解锁。
独占锁(写锁)/共享锁(读锁)/互斥锁

那么既然有了ReentrantLock,为什么还需要读写锁(ReentrantReadWriteLock)呢?为了更细致化的使用锁,实现读写分离。
我们知道ReentrantLock是不管什么操作逻辑,只要进入临界区访问共享资源,那么就会加锁,也就意味着,假设,我只是想读共享资源而已,那么还要去申请锁?这个就有点不符合道理了。这样会造成什么问题呢?多线程情况下读取资源,还需要等锁,那这个并发量就下降了,而且也没有必要加锁。
也就是说
为了并发量,可以允许多个线程同时进行读取共享资源,但是,如果有一个线程想去写共享资源, 那么就不应该有其他线程对资源进行读或写。
代码例子:
|
输出:
|
你会发现,写操作,都是原子性,没有中断(正在写入和写入完成是一对出现)。中间不会存在其他线程的读取或者写入。
读取的时候,是可以多个线程进行读取,你会发现,读取完成和读取结束并不是一对出现,这个是允许的,因为不需要原子性。
所以满足读写锁的要求。
CountDownLatch/CyclicBarrier/Semaphore
CountDownLatch
CountDownLatch是基于AQS的阻塞工具,阻塞一个或者多个线程,直到所有的线程都执行完成。
CountDownLatch解决了什么问题
当一个任务运算量比较大的时候,需要拆分为各种子任务,必须要所有子任务完成后才能汇总为总任务。
使用并发模拟的时候可以使用CountDownLatch.也可以设置超时等待时间。同时CountDownLatch也提供了可以设置超时等待的await方法。
让一些线程阻塞直到另外一些完成后才被唤醒。类似于wait和notify。
CountDownLatch主要有两个方法,当一个或多个线程调用await方法时,调用线程会被阻塞.其他线程调用countDown方法计数器减1(调用countDown方法时线程不会阻塞),当计数器的值变为0,因调用await方法被阻塞的线程会被唤醒,继续执行
举个例子:
假设,教室中有七个人,其中六个人是同学,一个是班长,班长要等这六个人都出教室了,然后再关门,那么这种等待其他子线程完成后主线程才操作的就很适合使用CountDownLatch。
|
源码分析
例子
|
我们知道CountDownLatch是 基于共享锁的形式,建立阻塞队列。也就是 Node.SHARE,意味着,多个线程可以同时阻塞在countDownLatch.await(),等到计数器减到0时,多个线程会同时进行执行await后面的代码。
他跟 ReentrantLock不同,lock采用的是独占锁的方式,Node.EXCLUSIVE,在某个时刻,只能够允许一个线程在执行。
所以共享锁的方式,更加的验证了,CountDownLatch的应用场景,在计数器未减少到0时,线程可以同时进行自己各自的业务代码,等计数器减少到0后,那么被await的线程唤醒,然后执行。
以下使用CDL简称CountDownLatch
查看CDL构造函数
public CountDownLatch(int count) {
if (count < 0) throw new IllegalArgumentException("count < 0");
this.sync = new Sync(count);
}
Sync(int count) {//Sync是CDL内部类,Sync继承了AQS
setState(count);
}
这里可以看到,aqs的state属性,在CDL这里的含义是,计数器的数量。而不再是之前我们所说的是否获取锁的标志位/重入次数。被赋予了新的含义
1.查看await()方法
java.util.concurrent.CountDownLatch.await()
public void await() throws InterruptedException {//顾名思义,他是请求共享锁,并且可以响应中断
sync.acquireSharedInterruptibly(1);
}
public final void AbstractQueuedSynchronizer.acquireSharedInterruptibly(int arg)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
if (tryAcquireShared(arg) < 0)//首次进来,state一般是不等于0的,因为计数器还为减少到0,所以tryAcquireShared返回-1
doAcquireSharedInterruptibly(arg);
}
protected int tryAcquireShared(int acquires) {//如果计数器减少到0,那么返回1,否则返回-1
return (getState() == 0) ? 1 : -1;
}
接着执行 doAcquireSharedInterruptibly 方法
java.util.concurrent.locks.AbstractQueuedSynchronizer.doAcquireSharedInterruptibly(int)
/**
* Acquires in shared interruptible mode.
* @param arg the acquire argument
*/
private void doAcquireSharedInterruptibly(int arg)
throws InterruptedException {
final Node node = addWaiter(Node.SHARED);//这个就是将当前线程节点,放到aqs阻塞队列中。返回当前线程节点
boolean failed = true;
try {
for (;;) {
final Node p = node.predecessor();
if (p == head) {
int r = tryAcquireShared(arg);//判断计数器state是否==0,如果是返回1,表示阻塞的线程可以开始唤醒执行
if (r >= 0) {
setHeadAndPropagate(node, r);//注意这里,这里会遍历整个aqs阻塞队列,然后逐个释放
p.next = null; // help GC
failed = false;
return;
}
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())//我们知道线程最终都会阻塞在这里
throw new InterruptedException();//这里可以直接响应中断,直接抛出异常
}
} finally {
if (failed)
cancelAcquire(node);
}
}
也就是说,实际上,await()方法的最终目的就是:将所有调用await方法的线程,都放到aqs阻塞队列中,开始在阻塞。什么时候唤醒呢?等到计数器state==0,也就是countdown到0。
我们发现他跟ReentrantLock整个加锁的流程是类似的,主要的区别在于,lock是独占锁,state表示的是锁标记。CDL在计数器到零后,会unpark所有在aqs阻塞队列的线程,而lock只会唤醒aqs阻塞队列首节点(所以说是独占锁)
2.查看CDL的countDown()
java.util.concurrent.CountDownLatch.countDown()
public void countDown() {
sync.releaseShared(1);
}
public final boolean AbstractQueuedSynchronizer.releaseShared(int arg) {
if (tryReleaseShared(arg)) {
doReleaseShared();
return true;
}
return false;
}
首先调用tryReleaseShared()方法,state减-1
java.util.concurrent.CountDownLatch.Sync.tryReleaseShared(int)
|
如果返回true,说明state已经变为了0。那么需要唤醒阻塞的线程。
接着调用doReleaseShared方法,释放共享锁
|
3.唤醒线程后
接着调用doAcquireSharedInterruptibly的parkAndCheckInterrupt,然后,继续执行for循环,然后执行 setHeadAndPropagate(node, r)方法。
|
private void setHeadAndPropagate(Node node, int propagate) {
Node h = head; // Record old head for check below
setHead(node);//将当前线程设置为头结点,这样的好处是,释放一个就将当前线程设置为头结点,然后再doReleaseShared方法中,总会触发 if (h == head),这样才能够跳出doReleaseShared()的for循环。唤醒所有阻塞队列线程结束。
if (propagate > 0 || h == null || h.waitStatus < 0 ||
(h = head) == null || h.waitStatus < 0) {
Node s = node.next;
if (s == null || s.isShared())
doReleaseShared();//接着唤醒,当前节点的下一个节点,以此类推。直到唤醒完所有的阻塞队列的节点。
}
}
总结
CDL使用共享锁(不需要竞争)的方式阻塞所有的线程,所有线程阻塞到阻塞队列中,直到countdown到0。就会去唤醒阻塞队列中所有线程(共享锁,不需要竞争)。
使用场景
例如zookeeper的server的启动挂起,唤醒关闭server就是利用CountDownLatch实现的。
CyclicBarrier
这个跟CountDownLatch是相反的,他是做加法,当增加到某一个值后,那么就会唤醒阻塞的线程。
|
Semaphore - 可以用作限流
它的本质实际上就是基于信号量(PV操作)的机制实现。
信号量的主要用户两个目的,一个是用于多个共享资源的相互排斥使用,另一个用于并发资源数的控制。
也就是说,我们可以限制资源的数量(令牌),那么多个请求进来后,去争抢固定数量的令牌,如果令牌争抢完,后面还没有得到令牌的线程就会阻塞,直到后令牌释放,然后才会去争抢(争抢的过程中,也可以插队,也就是说Semaphore也是有公平锁和非公平锁的区分)
以下案例,模拟六辆车抢占三个车位。
|
很明显,Semaphore是可以替代,synchronized和lock的,只需要把信号量修改为1即可。因为内部锁和显示锁的本质就是抢占一个资源。
而且我们发现,Semapore实际上是CountDownLatch和CyclicBarrier的结合体。CountDownLatch是减少到某个数然后唤醒某个线程,CyclicBarrier是新增到某个数,然后唤醒某个线程。
但是Semapore是有增有减,可以提供给多个线程功能抢占资源,线程使用完资源后,马上释放,然后另一个线程可以马上的抢占资源。
源码分析
你会发现,Semaphore获取资源的源代码跟COuntDownlatch基本上是一样的,也是通过共享锁的形式,进行资源的争抢(只不过他有公平和非公平两种实现方式,共享公平锁和共享非公平锁的区别跟ReentrantLock一样,公平锁多了hasQueuedPredecessors方法的判断)
ConcurrentHashMap源码分析
|
以下ConcurrentHashMap简称chm。
我们阅读源码的原则是,第一时刻考虑如果是多线程访问时,这段代码会不会有问题。第二,不要通读所有代码,而是根据if条件或者其他条件,选择性的读取某段代码。
查看put操作
我们知道,map是通过数组+链表/红黑树的数据结构保存数据,其中数组是保存key经过hash后得到下标。
在chm中,数组使用 transient volatile Node
|
initTable数组初始化工作 - sizeCtl属性
首先我们要明确一点,多线程情况下,initTable()方法的调用是存在线程安全的,所以我们需要注意chm对于initTable()是如何保证线程安全的。
|
这里使用了一个chm的一个非常重要的成员变量 private transient volatile int sizeCtl
通过U.compareAndSwapInt(this, SIZECTL, sc, -1) cas操作,保证了高并发下只有一个线程能够进行初始化数组,比较sizeCtl是否跟预期值一致(等于0),如果是,那么把sizeCtl设置为-1,进入初始化数组逻辑。
否则cas失败,表示数组已经初始化,那么退出whil循环(此时table已经不为null),返回数组。
sizeCtl的三个作用
通过上面的源码我们发现,是否已经初始化的数组是通过sizeCtl和cas来进行判断和操作的。而且sizeCtl一共有两个作用:sizeCtl == -1 ,表示当前已经有线程抢到了初始化chm数组的权限、sizeCtl > 0,sizeCtl=sc=n*0.75,表示下一次数组扩容大小。
sizectl的第三个作用,当sizeCtl是负数,但不是-1,就表示当前有几个线程在进行扩容操作,例如sizeCtl=-2,表示有两个线程在执行扩容操作( 关于第三个作用,在下面的addCount()方法的第二段if,里面会有用到 )
tabat和casTabAt,获取key对应的数组下标
同时这两个方法也是需要保证线程安全的。我们来看源代码。他们是怎么保证线程安全的
|
addCount(1L, binCount) 最终执行
我们知道不管,put最终都会执行到addCount(1L, binCount),顾名思义 ,就是计数的意思,新增put一条数据,那么size就会增1。
那么怎么保证高并发下,addCount方法线程安全呢?通过cas、加锁?虽然这两种方法都可以保证线程安全,但是会有性能影响。那么我们来看一下他是怎么进行线程安全控制的
他是怎么维护chm的size呢?
那么我们来看一下他的源码:
|
结论:
chm的size,数据个数,是通过chm的baseCount和counterCells这两个成员属性来进行控制的或者说得到的。
首先我们回顾一下,hashmap或者arrayList,都是通过一个成员属性size来进行元素个数的维护,那么为什么chm不通过这样的方式来维护元素个数呢?
实际上,chm是通过这样的策略进行元素个数的维护:
如果在线程数不是很多的情况下,那么对baseCount进行cas操作,自增1,实现元素数量的增加维护。
但是假设是高并发情况下或者说对于baseCount的cas操作失败,那么就会增加一个counterCells数组来进行高并发下分流操作,避免无效的cas操作。
总而言之,在对chm元素数量自增1的时候,会尝试进行一次对baseCount进行cas的自增操作,假设失败,马上使用counterCells数组进行数组元素的维护。
下面详细分析
首先我们假设chm只通过baseCount,来进行元素个数的维护,那么在put一条数据的时候,我们知道baseCount需要自增1,那么为了线程安全,baseCount的自增需要通过加锁或者cas的方式进行,一般使用cas。
那么如果使用只使用baseCount来维护chm元素个数,那么进行cas自增1的时候就会面临一个问题,假设高并发情况下,多个线程同时执行put操作,cas只能够运行一个线程修改成功,那么其他线程就会做没有意义的cas操作,线程多的情况下,cpu压力会上升。
那么怎么改变这种情况呢?那就是引入分段的概念,就是可以让多个线程执行同时执行cas自增操作,类似于部署多个节点,支持高并发。那么就引出了counterCells数组,每个数组位置,都保存一个value值,表示chm元素个数,这样求得整个chm元素个数的时候,只需要遍历counterCells数组然后累加再加上baseCount就等于chm元素个数(详情查看chm的size()方法)
那么引入后上面的高并发cas的问题,怎么解决了呢?
假设counterCells数组初始化为2,那么假设有三个线程,put操作完,三个线程需要调用addCount增加元素个数。那么就会给这三个线程,随机分配一个关于counterCells数组的下标,让他们各自去数组下标的位置,进行自增1操作。那么这样就起到了分流的作用,这样就减少了无效cas的个数。
也就是说,CounterCell数组,保存了chm的元素个数。
为了加深上面的理论,我们查看一下chm的size() 方法:
|
fullAddCount()初始化counterCells数组
|
首先我们要知道,counterCells数组某个下标也会存在线程安全问题,因为,可能有多个线程通过随机数&m的计算得到了,相同的数组下标。为了避免自增的线程安全,所需要也是需要进行加锁控制。
这里是通过chm的成员属性cellsBusy,进行数组下标锁的控制,默认是0,通过cas判断,当前数组下标是否存在操作的线程,如果不存在则把cellsBusy设置为1(U.compareAndSwapInt(this, CELLSBUSY, 0, 1)),然后执行里面的业务操作 .
resizeStamp() 扩容操作
扩容操作的代码如下
|
此时通过resizeStamp(16)得到的值是32795,二进制是:
|
需要注意的是chm的扩容是可以多个线程并行扩容的,所以才需要通过sc的低十六位来记录参与扩容操作的线程个数!!!!!!!!!!!!!!
transfer() 扩容操作
我们知道扩容操作,要做的事情就两件:
- 增加chm数组的长度
- 转移原数组的节点到新数组 - 数据转移(这一步支持多个线程同时操作,提升效率)
因为方法比较长,所以在这里我们需要进行分段分析。为了方便分析,我们这里假设chm原数组长度是32。
|
通过上面的代码,我们知道可以设置多个线程进行并发的参与扩容操作,那么这么确定每个线程自己负责哪一段的数组下标呢?
接着往下看代码
可以看到这里是通过一个无限循环进行分割,每个线程负责的下标区间。
|
我们知道上面的代码只是确定了线程负责数组区间,但是真正进行数据迁移到新数组的代码还在下面。
首先我们需要明确一点,迁移数据是从数组的后面往前迁移的,` if (–i >= bound || finishing)` 由这段代码可以看出,i–的方式从后往前一个一个的迁移
迁移数据代码
迁移数据的代码块就是在for循环里面的,synchronize代码段。线程在他负责的数组下标区间进行,从后往前的数组下标数据的逐个迁移。最终每个数组的下标的数据,都会拆分成两个链表,高位链表和低位链表( Node
形成高低位链表迁移的好处就是,可以批量迁移节点到新数组。如果不怎么做,那么就需要把旧数组下标的链表逐个rehash,然后再逐个放到新数组,这样的效率太慢。
那么为什么低位链表可以直接平移,高位链表移到新数组对应的下标,要用原来的下标+原来数组长度呢?
我们来证明一下:
假设原来数组长度是 n == 16,通过put(“k”,”k”),那么key要通过 hash&(n-1) 算法得到他所属的数组下标,那么key==k的hash值假设等于9.
那么hash&(n-1) 等于
|
假设n 扩容到 32,那么需要rehash原先在旧数组的值,然后通过hash&(n-1) 算法得到他所属的新数组的下标
那么hash&(n-1) 等于
|
所以我们发现低位链表可以直接平移到新数组(因为key的hash的高位都是0,所以计算获取数组下标时,取决于低位)
同理证明高位链表,为什么需要n+i。假设key的hash是20,他的二进制是:0001 0100
那么hash&(n-1) 等于
|
假设数组扩容到32
那么hash&(n-1) 等于
|
证明完毕
总结
换句话说,addCount方法的第一个if代码块核心就是,进行chm元素个数的自增1。如果在单线程情况下,直接通过对baseCount的cas操作,进行数量的自增1.
但是如果存在多个线程进行增加元素个数的操作时,不再使用对baseCount进行cas的方式进行数量增加,进而转化为使用一个counterCells数组的方式,进行分而治之的方式,通过对数组每个下标的cas操作,达到高效率高性能的元素数量自增。
执行到b2 区域 代码块
如果执行到这部分代码那就表示,当前put操作的key对应的数组下标的位置,已经存在节点。(也就是冲突)
|
首先来看一下Node节点的数据结构
hash就是当前节点的key的hash值,key和val就是put操作是传入的key和value,原样保存,next就是冲突时,需要构建的单链表指向下一个占据相同数组下标的节点。
什么时候转化为红黑树
如果链表长度大于8和node数组长度大于64的时候,如果再往当前链表添加数据,那么就会将当前链表转化为红黑树。
如果扩容后,当前数组节点的链表树小于8,他又会把红黑树转化为单链表
总结
一下就是chm的核心要点

https://blog.csdn.net/yyzzhc999/article/details/96724885
阻塞队列 - BlockingQueue
阻塞队列,顾名思义,首先它是一个队列,而一个阻塞队列在数据结构中所起的作用大致如图所示:
线程1往阻塞队列中添加元素二线程2从队列中移除元素
当阻塞队列是空时,从队列中获取元素的操作将会被阻塞.
当阻塞队列是满时,往队列中添加元素的操作将会被阻塞.
同样
试图往已满的阻塞队列中添加新元素的线程同样也会被阻塞,直到其他线程从队列中移除一个或者多个元素或者全清空队列后使队列重新变得空闲起来并后续新增。
为什么用?有什么好处?
在多线程领域:所谓阻塞,在某些情况下会挂起线程(即线程阻塞),一旦条件满足,被挂起的线程优惠被自动唤醒。
为什么需要使用BlockingQueue,好处是我们不需要关心什么时候需要阻塞线程,什么时候需要唤醒线程,因为BlockingQueue都一手给你包办好了。
在concurrent包 发布以前,在多线程环境下,我们每个程序员都必须自己去控制这些细节(通过wait和notify),尤其还要兼顾效率和线程安全,而这会给我们的程序带来不小的复杂度。
BlockingQueue的结构

ArrayBlockingQueue: 由数组结构组成的有界阻塞队列.
LinkedBlockingDeque: 由链表结构组成的有界(但大小默认值Integer>MAX_VALUE)阻塞队列.
PriorityBlockingQueue:支持优先级排序的无界阻塞队列.
- DelayQueue: 使用优先级队列实现的延迟无界阻塞队列.
SynchronousQueue:不存储元素的阻塞队列,也即是单个元素的队列.
SynchronousQueue没有容量
与其他BlcokingQueue不同,SynchronousQueue是一个不存储元素的BlcokingQueue
每个put操作必须要等待一个take操作,否则不能继续添加元素,反之亦然.
生产就马上用
- /*** 阻塞队列SynchronousQueue演示**/public class SynchronousQueueDemo {public static void main(String[] args) {BlockingQueue<String> blockingQueue = new SynchronousQueue<>();new Thread(() -> {try {System.out.println(Thread.currentThread().getName() + "\t put 1");blockingQueue.put("1");//阻塞,等待takeSystem.out.println(Thread.currentThread().getName() + "\t put 2");blockingQueue.put("2");//阻塞,等待takeSystem.out.println(Thread.currentThread().getName() + "\t put 3");blockingQueue.put("3");//阻塞,等待take} catch (InterruptedException e) {e.printStackTrace();}}, "AAA").start();new Thread(() -> {try {try {TimeUnit.SECONDS.sleep(5);} catch (InterruptedException e) {e.printStackTrace();}System.out.println(Thread.currentThread().getName() + "\t" + blockingQueue.take());//取出阻塞队列中队列头元素 1。 然后这个时候才能够put(2)try {TimeUnit.SECONDS.sleep(5);} catch (InterruptedException e) {e.printStackTrace();}System.out.println(Thread.currentThread().getName() + "\t" + blockingQueue.take());//取出阻塞队列中队列头元素 2。 然后这个时候才能够put(3)try {TimeUnit.SECONDS.sleep(5);} catch (InterruptedException e) {e.printStackTrace();}System.out.println(Thread.currentThread().getName() + "\t" + blockingQueue.take());} catch (InterruptedException e) {e.printStackTrace();}}, "BBB").start();}}
输出:
AAA put 1
BBB 1
AAA put 2
BBB 2
AAA put 3
BBB 3可以看到,他是生产一个,然后生产线程阻塞,等待消费者,take消费。然后再接着生产。。。。
- LinkedTransferQueue:由链表结构组成的无界阻塞队列.
- LinkedBlockingDeque:由了解结构组成的双向阻塞队列.
BlockingQueue的核心方法


实际上,这四组api是适用于不同的应用场景的。
校验第一组api,使用的时候,会抛出异常。
|
校验第二组api
offer,插入元素,假设插入元素后,数组长度超过了设定的有界值,那么返回false(相比第一组api的add,offer不会抛出异常)
poll,移除元素,同理,要移除的元素不存在则返回null
使用案例
生产者消费者模式
生产一个消费一个
wait和notify版本
|
输出:
|
阻塞队列版
|
输出:
|
总结
通过查看take源码,我们就可以知道,为什么take能够实现阻塞。实际上就是利用了ReentrantLock的condition的await机制,进行阻塞,然后把当前执行take 操作的线程加入到notEmpty的condition等待队列中,然后等待其他线程加入元素后,那么就会执行notEmpty.signal()方法唤醒在等待队列的take线程,加入到aqs阻塞队列,然后等待获取锁,然后接着执行take操作。
也就是说,阻塞队列,是基于ReentrantLock来实现的。
获取线程的第三种方式 - Callable
创建线程的2种方式,一种是直接继承Thread,另外一种就是实现Runnable接口。
这2种方式都有一个缺陷就是:在执行完任务之后无法获取执行结果。
如果需要获取执行结果,就必须通过共享变量或者使用线程通信的方式来达到效果,这样使用起来就比较麻烦。
Callable和Future介绍
Callable接口代表一段可以调用并返回结果的代码。Future接口表示异步任务,是还没有完成的任务给出的未来结果。所以说Callable用于产生结果,Future用于获取结果。
Callable接口使用泛型去定义它的返回类型。Executors类提供了一些有用的方法在线程池中执行Callable内的任务。由于Callable任务是并行的(并行就是整体看上去是并行的,其实在某个时间点只有一个线程在执行),我们必须等待它返回的结果。
java.util.concurrent.Future对象为我们解决了这个问题。在线程池提交Callable任务后返回了一个Future对象,使用它可以知道Callable任务的状态和得到Callable返回的执行结果。Future提供了get()方法让我们可以等待Callable结束并获取它的执行结果。
这里说的是通过实现Callable接口,来创建线程
|
相比实现Runnable的run方法,Callable的call方法,是具备返回值的,而且能够抛出异常。
那么怎么使用呢?跟Runnable一样,传入Thread构造函数中,然后创建实例?
我们查看Thread的构造函数,发现并没有入参是Callable的构造器。
那么我们这个时候就想,有没有什么接口实现了Runnable接口.

很明显这里找到了,这个接口或者实现类。通过查看,我们可以得知FutureTask类,既提供了Callable为入参的构造器。
最终示例代码
|
测试futureTask.get()方法的阻塞性
|
所以说,建议把futuretask.get方法放到最后,不然,一直阻塞,影响其他线程执行。
获取线程的第四种方式:线程池- 底层由ThreadPoolExecutor实现
线程池做的工作主要是控制运行的线程的数量,处理过程中将任务加入队列,然后在线程创建后启动这些任务,如果线程数量超过了最大数量,超出的数量的线程排队等候,等其他线程执行完毕,再从队列中取出任务来执行。
他的主要特点为:线程复用,控制最大并发数,管理线程。
第一:降低资源消耗,通过重复利用自己创建的线程降低线程创建和销毁造成的消耗。
第二:提高响应速度,当任务到达时,任务可以不需要等到线程创建就能立即执行。
第三:提高线程的可管理性,线程是稀缺资源,如果无限的创建,不仅会消耗资源(JVM的内存管理),还会降低系统的稳定性,使用线程池可以进行统一分配,调优和监控。
线程池架构实现
Java中的线程池是通过Executor框架实现的。该框架中用到了Executor,Executors,ExecutorService,ThreadPoolExecutor这几个类.

其中Executors是工具类,类似于。Arrays、Collections。
编码实现 - 五种方式创建线程池
Executors.newScheduledThreadPool()
Executors.newWorkStealingPool(int)
java8新增,使用目前机器上可以的处理器作为他的并行级别,不常用。
Executors.newFixedThreadPool(int)
主要特点如下:
1.创建一个定长线程池,可控制线程的最大并发数,超出的线程会在队列中等待。
2.newFixedThreadPool创建的线程池corePoolSize和MaxmumPoolSize是 相等的,它使用的的LinkedBlockingQueue。

例子:
|
输出:
|
可以看到,不管有多少个请求,最多有五个线程进行交替处理这十个请求。
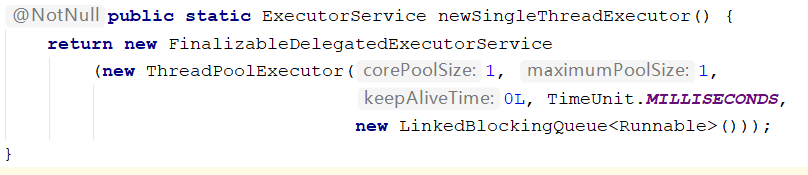
Executors.newSingleThreadExecutor()
一个任务一个线程执行的任务场景,线程池中只有一个线程来处理业务。
他就类似于,Executors.newFixedThreadPool(1),不管有多少个请求,线程池内只有一个线程在执行这些请求 。
主要特点如下:
1.创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务都按照指定顺序执行.
2.newSingleThreadExecutor将corePoolSize和MaxmumPoolSize都设置为1,它使用的的LinkedBlockingQueue
Executors.newCachedThreadPool()
这个是一池N线程,也就是,不知道线程池中有多少个线程,当请求过来时,他会自动的创建相应的线程,线程池中的线程不是固定数量,有时候可能创建5个,也有可能创建1个,就看每个线程的执行能力,自动创建。
适用:执行很多短期异步的小程序或者负载较轻的服务器。

主要特点如下:
1.创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则创建新线程.
2.newCachedThreadPool将corePoolSize设置为0,MaxmumPoolSize设置为Integer.MAX_VALUE,它使用的是SynchronousQUeue,也就是说来了任务就创建线程运行,如果线程空闲超过60秒,就销毁线程
总结
可以看到,后面三个线程池的创建,底层代码,都是通过ThreadPoolExecutor进行创建的。
线程池几个重要参数介绍 - 重要
刚才我们看了fixedThreadPool、singleThreadPool、cachedThreadPool发现他们最终的实现都是ThreadPoolExecutor,只有五个参数啊?哪来的七个参数呢?
我们再接着查看ThreadPoolExecutor构造器,发下他内部调用的this就是传递了七个参数。
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
再接着看this
|
corePoolSize:线程池中的常驻核心线程数
1.在创建了线程池后,当有请求任务来之后,就会安排池中的线程去执行请求任务,近视理解为今日当值线程
2.当线程池中的线程数目达到corePoolSize后,就会把到达的任务放入到缓存队列当中。
通俗来讲,就是,不管你用不用得到,线程池创建后,里面就有corePoolSize个线程在等着你使用。类似于银行的办事窗口,不管有没有办业务,窗口还是这么多个等着你。
maximumPoolSize:线程池能够容纳同时执行的最大线程数,此值大于等于1
也就是说,线程池中,最多最多有maximumPoolSize个线程,已经是峰值了,不能再增加了。也就是说当corePoolSize不够用了,那么可能增加到maximumPoolSize个线程。这里说的是,可能会增加,但是什么时候增加呢?
答案是:当corePoolSize个线程已经被使用,而且,任务队列(workQueue)中等待执行的任务也已经占满了队列,那么这个时候,如果还有任务请求进来,那么这个时候就会扩展线程到maximumPoolSize个,然后先执行之前在任务队列中阻塞的任务,把后来的任务放到任务队列中继续等待。
但是可能会有个问题,这个时候,又有新的任务进来了,此刻线程已经扩展到maximumPoolSize个,任务队列也已经占满。那么为了避免其他情况的发生,这个时候就需要拒绝后来的任务。这个时候,第七个参数的重要性就来了。handler拒绝策略
keepAliveTime:多余的空闲线程存活时间。
当空间时间达到keepAliveTime值时,发现没有任务执行了,那么多余的线程会被销毁直到只剩下corePoolSize个线程为止。
默认情况下:
只有当线程池中的线程数大于corePoolSize时keepAliveTime才会起作用,直到线程中的线程数不大于corepoolSIze,
这个很好理解,因为创建线程太多(最多maximumPoolSize个)会消耗内存资源,所以我们肯定要有个销毁机制,但是我们又不能全部销毁线程池中的所有线程(创建线程也需要开销),所以我们一般是销毁到corePoolSize个就停止。
unit:
keepAliveTime的单位
workQueue:任务队列,被提交但尚未被执行的任务.
这个也很好理解,就是线程不够用了(达到corePoolSize个),那么后面进来的请求,就等待阻塞。这里一般是通过阻塞队列进行实现。
threadFactory:表示生成线程池中工作线程的线程工厂,用户创建新线程,一般用默认即可
handler:拒绝策略,表示当线程队列满了并且工作线程大于等于线程池的最大 数(maxnumPoolSize)时如何来拒绝.
总结
换句话说,corePoolSize是线程池的初始值,如果任务上涨,那么maximumPoolSize和workQueue就是保底策略,当任务还是持续上涨,那么handler拒绝策略是最终解决方案。
反之如果任务从高峰开始下降,那么keepAliveTime和unit就是收尾工作的保证。
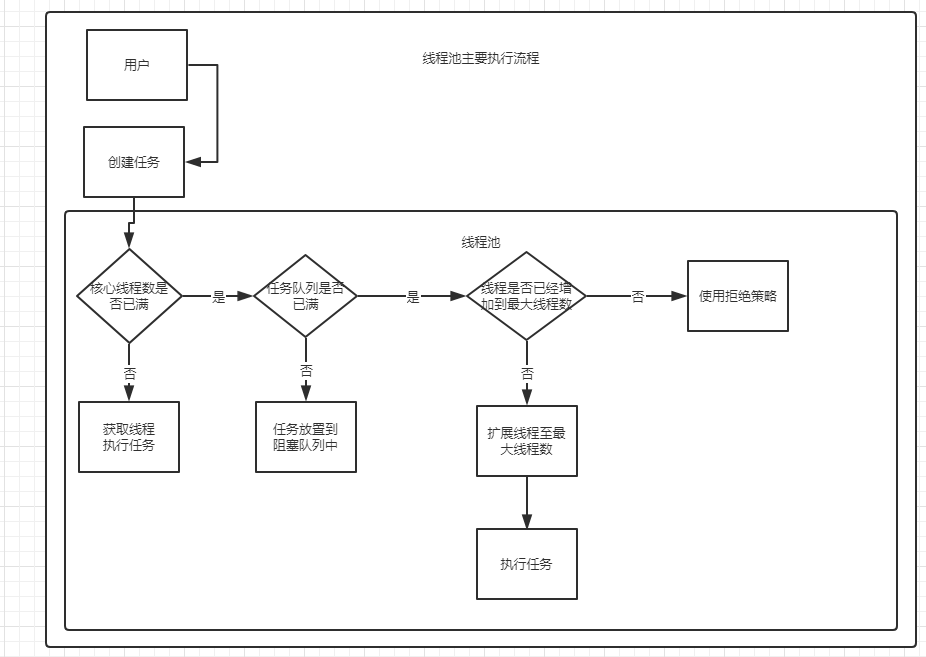
线程池的底层工作原理 - 重要!!!!!!!!!

这张图就是对应了整个线程池七个参数的的使用和执行流程。

线程池用过吗?生产上你是如何设置合理参数
线程池的拒绝策略请你谈谈
拒绝策略什么时候生效?
等待队列也已经排满了,再也塞不下新的任务了,同时,线程池的max也到达了,无法继续为新任务服务,这时我们需要拒绝策略机制合理的处理这个问题。
JDK内置的拒绝策略
- AbortPolicy(默认):直接抛出RejectedException异常阻止系统正常运行
- CallerRunPolicy:”调用者运行”一种调节机制,该策略既不会抛弃任务,也不会抛出异常,而是将某些任务回退到调用者
- DiscardOldestPolicy:抛弃队列中等待最久的任务,然后把当前任务加入队列中尝试再次提交。
- DiscardPolicy:直接丢弃任务,不予任何处理也不抛出异常.如果允许任务丢失,这是最好的一种方案。
以上内置策略均实现了RejectExecutionHandler接口。
你在工作中单一的/固定数的/可变你的三种创建线程池的方法,你用哪个多?超级大坑
正确答案是:一个都不用,我们生产上只能使用自定义的。
参考阿里巴巴java开发手册
【强制】线程资源必须通过线程池提供,不允许在应用中自行显式创建线程。 说明:使用线程池的好处是减少在创建和销毁线程上所消耗的时间以及系统资源的开销,解决资源不足的问题。如果不使用线程池,有可能造成系统创建大量同类线程而导致消耗完内存或者“过度切换”的问题。
【强制】线程池不允许使用Executors去创建,而是通过ThreadPoolExecutor的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。说明:Executors返回的线程池对象的弊端如下:
1)FixedThreadPool和SingleThreadPool:允许的请求队列长度为Integer.MAX_VALUE,可能会堆积大量的请求,从而导致OOM。
2)CachedThreadPool和ScheduledThreadPool:允许的创建线程数量为Integer.MAX_VALUE,可能会创建大量的线程,从而导致OOM。
自定义过线程池使用 - 并使用拒绝策略
|
看上面代码,我们知道,线程池最多容纳8个任务(最大值5+阻塞队列3 = 8,5个任务在执行,3个任务在阻塞队列等待),那么执行的任务达到9个时候,很明显就会触发拒绝策略。
运行上面代码输出:
|
很明显报了异常RejectedExecutionException。这个就是默认的AbortPolicy策略发出的。
使用CallerRunPolicy策略
ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(
2, 5,
1, TimeUnit.SECONDS,
new LinkedBlockingQueue<>(3), Executors.defaultThreadFactory(), new ThreadPoolExecutor.CallerRunPolicy());
输出:
|
你会发现他成功执行了8个任务(这个是符合我们对于线程池的设置),但是我们发现,他并没有报异常,但是输出了这么一行日志使用线程 main 处理业务。
我们再回过头来看一下CallerRunPolicy拒绝策略的定义:
该策略既不会抛弃任务,也不会抛出异常,而是将某些任务回退到调用者。那么谁是线程调用者?很明显上诉代码中,main线程就是任务的调用者。所以这里让main新成进行了处理
DiscardOldestPolicy拒绝策略
抛弃队列中等待最久的任务,然后把当前任务加入队列中尝试再次提交。
|
我们发现,他每次只执行8个任务(服务设置),其余两个任务被抛弃,不会抛出异常。
输出:
|
DiscardPolicy拒绝策略
直接丢弃任务,不予任何处理也不抛出异常.如果允许任务丢失,这是最好的一种方案。
|
他的运行结果:
|
他跟DiscardOldestPolicy策略类似,只不过DiscardOldestPolicy是从阻塞队列中抛弃长时间的任务,而,DiscardPolicy是从一开始就抛弃多余任务,压根就没进阻塞队列。
合理配置线程池你是如何考虑的?
首先查看CPU核数
CPU密集型
System.out.println(Runtime.getRuntime().availableProcessors());查看CPU核数

IO密集型

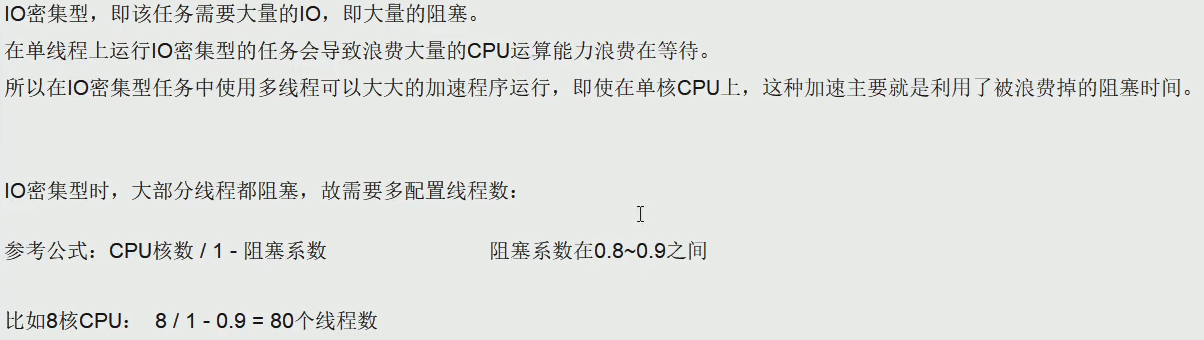
如果线上机器突然宕机,线程池的阻塞队列中的请求怎么办?
阻塞队列中的请求,都是存放在内存中的,那么如果机器宕机,那么队列中的请求必然会丢失。那么怎么解决呢?
第一反应,应该就是,本地化,保存到本地硬盘(例如数据库等等)
解决方案:
如果你要提交一个任务到线程池之前,先把任务的信息,保存到数据库中,并更新他的状态(未提交,已提交,已完成),提交成功后,他的状态修改为已提交。
假设机器宕机,那么当机器重启后,系统启动,后台线程可以去扫描数据库中的数据,然后把未提交和已提交的任务拿出来,再次重新提交到线程池中,继续执行
死锁编码及定位分析

产生死锁的主要原因:系统资源不足、进程运行推进的顺序不合适、资源分配不当。
代码实现死锁:
|
运行程序:

你会发现程序卡死在这里
解决死锁 - 重要!!!!
1.jps命令定位进程编号
获取死锁程序的进程编号- 使用 jps -l
|
可以知道是9268
2.jstack找到死锁查看
使用命令 : jstack 9268
查看输出日志可以得到:

|
可以看到 threadBBB 锁着0x00000000d5c9b818,等待0x00000000d5c9b7e0。然而threadAAA锁着0x00000000d5c9b7e0,等待0x00000000d5c9b818。就是死锁。
缓存的重要性
缓存就是利用了局部性原理实现了数据的高效读取。局部性原理包括时间局部性(temporal locality)和空间局部性(spatial locality)这两种策略。
在实际的计算机日常的开发和应用中,我们对于数据的访问总是会存在一定的局部性。有时候,这个局部性是时间局部性,就是我们最近访问过的数据还会被反复访问。有时候,这个局部性是空间局部性,就是我们最近访问过数据附近的数据很快会被访问到。
而局部性的存在,使得我们可以在应用开发中使用缓存这个有利的武器。比如,通过将热点数据加载并保留在速度更快的存储设备里面,我们可以用更低的成本来支撑服务器。
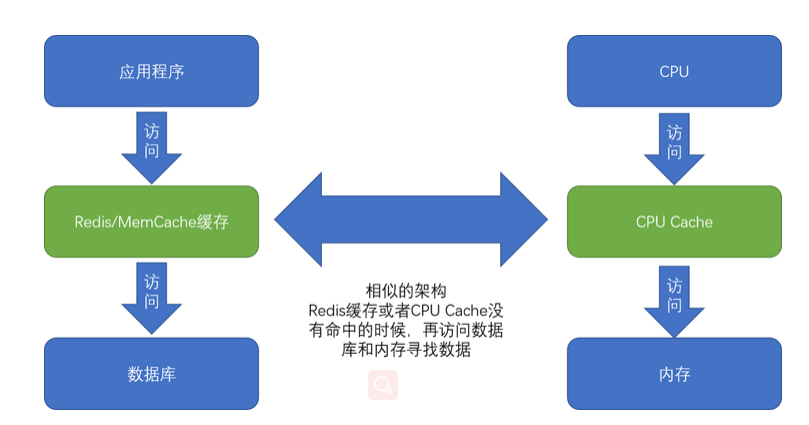
序列化和反序列化原理分析
设么叫序列化:把存储在内存中的数据,保存到本地硬盘或者传输
trensiant:修饰某个属性,目的就是阻止这个属性进行序列化
那么为什么会存在writeObject和readObject?这两个方法就是序列化和反序列化调用的方法。
可以通过这个方法制订序列化和反序列化规则,例如某个字段虽然被trensiant修饰,但是我们可以在writeObejct方法中对这个字段打破trensiant的作用,也就是,可以序列化。让trensiant失效
java原生序列化,需要实现接口,Serializable。同时建议制订一个serialVersionUID,目的就是给序列化的对象加个版本号,也就是说我当前序列化这个对象的版本是serialVersionUID,那么你反序列化的时候,也要是这个serialVersionUID,一模一样,如果你修改了这个值serialVersionUID,再去反序列化那么就会报异常。,这样保证了数据的安全性。
如果不指定serialVersionUID,默认会生成一个,但是建议制订。避免后面来的开发人员,发现,咦,你这个要序列化的类竟然没有制订serialVersionUID,那么他随手给你加上了,导致,下次反序列化的时候,发现版本号不一致(默认生成的serialVersionUID跟后来人加上的serialVersionUID,不相等),反序列化失败,对象数据就拿不到了。
现在常用的序列化格式有,json,xml,hessian等等
xml的好处是:阅读性强,可以保存更多的东西,例如类名,等等。缺点是,序列化后很大,占据的空间多
json,就是比较轻量级,类似{name:”King哥”,age:12} 这样的格式,好处就是轻量级,传输所需要的带宽少,缺点就是不能够携带更多的信息。
所以具体选择哪种序列化手段,得看你具体业务场景,和你对带宽的要求

