使用 jstat 摸清线上系统的JVM运行状况
平时我们对运行中的系统,如果要检查他的JVM的整体运行情况,比较实用的工具之一,就是jstat
他可以轻易的让你看到当前运行中的系统,他的JVM内的Eden、Survivor、老年代的内存使用情况,还有Young GC和Full gC的执行次数以及耗时。
通过这些指标,我们可以轻松的分析出当前系统的运行情况,判断当前系统的内存使用压力以及GC压力,还有就是内存分配是否合理。下面我们就一点点来看看这个jstat工具的使用。
jstat -gc PID
首先第一个命令,就是在你们的生产机器linux上,找出你们的Java进程的PID,这个大家自行百度一下即可,用jps命令就可以看到。
接着就针对我们的Java进程执行:jstat -gc PID。这就可以看到这个Java进程(其实本质就是一个JVM)的内存和GC情况了。
运行这个命令之后会看到如下列,给大家解释一下:(单位都是kb)
|
举个例子:
jvm参数设置
|
堆内存设置为了200MB,把年轻代设置为了100MB,然后Eden区是80MB,每块Survivor区是10MB,老年代也是100MB。大对象的阈值是3M
java代码
|
为什么刚开始先休眠30s?目的是为了在真正进入业务逻辑之前,我们先找到这个进程的PID,以便我们执行jstat命令。
接着看loadData()方法内的代码,其实非常简单,他会循环50次,模拟每秒50个请求
然后每次请求会分配一个100KB的数组,模拟每次请求会从数据存储中加载出来100KB的数据。接着会休眠1秒钟,模拟这一切都是发生在1秒内的。
开始执行程序
此时程序会先进入一个30秒的休眠状态,此时尽快执行jps命令,查看一下我们启动程序的进程ID,如下图所示:
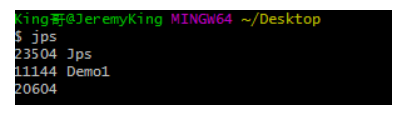
此时会发现我们运行的Demo1这个程序的JVM进程ID是11144。
然后尽快执行下述jstat命令:jstat -gc 11144 1000 1000
他的意思就是针对11144这个进程统计JVM运行状态,同时每隔1秒钟打印一次统计信息,连续打印1000次。
然后我们就让jstat开始统计运行,每隔一秒他都会打印一行新的统计信息,过了几十秒后可以看到如下图所示的统计信息:

接着我们一点点来分析这个图。首先我们先看如下图所示的一段信息:

这个EU大家应该还记得,就是之前我们所说的Eden区被使用的容量,可以发现他刚开始是3MB左右的内存使用量
可以得到新生代增长速率
接着从我们程序开始运行,会发现每秒钟都会有对象增长,从3MB左右到7MB左右,接着是12MB,17MB,22MB,每秒都会新增5MB左右的对象。
这个跟我们写的代码是完全吻合的,我们就是每秒钟会增加5mB左右的对象。
然后当Eden区使用量达到70多MB的时候,再要分配5MB的对象就失败了,此时就会触发一次Young GC,然后大家继续看下面的图:
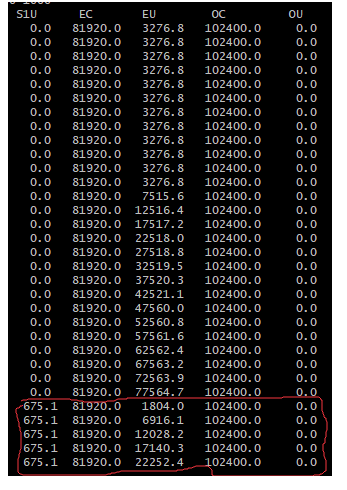
注意看上面红圈里的内容,大家会发现,Eden区的使用量从70多MB降低为了1MB多,这就是因为一次Young GC直接回收掉了大部分对象。
Young GC的触发频率
通过新生代的增长速率我们,也是可以推算出,ygc的频率是:80M/5M = 16s 左右。
所以我们现在就知道了,针对这个代码示例,可以清晰的从jstat中看出来,对象增速大致为每秒5MB左右,大致在十几秒左右会触发一次Young GC
Young GC的耗时
这个就是Young GC的触发频率,以及每次Young GC的耗时,大家看下图:
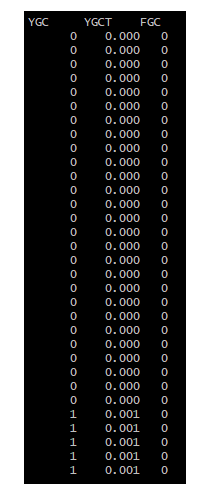
上图清晰告诉你了,一次Young GC回收70多MB对象,大概就1毫秒,所以大家想想,Young GC其实是很快的,即使回收800MB的对象,也就10毫秒那样。
所以你想如果是线上系统,他Eden区800MB的话,每秒新增对象50MB,十多秒一次Young GC,也就10毫秒左右,系统卡顿10毫秒,几乎没什么大影响的。
所以我们继续推论,在这个示例中,80MB的Eden区,每秒新增对象5MB,大概十多秒触发一次Young GC,每次Young GC耗时在1毫秒左右。
每次Young GC后有多少对象是存活下来的
简单看上上图,S1U就是Survivor中被使用的内存,之前一直是0,在一次Young GC过后变成了675KB,所以一次Young GC后也就存活675KB的对象而已,轻松放入10MB的Survivor中。
而且大家注意上上图中的OU,那是老年代被使用的内存量,在Young GC前后都是0
这说明这个系统运行良好,Young GC都不会导致对象进入老年代,这就几乎不需要什么优化了。因为几乎可以默认老年代对象增速为0,Full GC发生频率趋向于0,对系统无影响。
其他的jstat命令
除了上面的jstat -gc命令是最常用的以外,他还有一些命令可以看到更多详细的信息,如下所示:
- jstat -gccapacity PID:堆内存分析
- jstat -gcnew PID:年轻代GC分析,这里的TT和MTT可以看到对象在年轻代存活的年龄和存活的最大年龄
- jstat -gcnewcapacity PID:年轻代内存分析
- jstat -gcold PID:老年代GC分析
- jstat -gcoldcapacity PID:老年代内存分析
- jstat -gcmetacapacity PID:元数据区内存分析
新生代对象增长的速率
|
这行命令,他的意思就是每隔1秒钟更新出来最新的一行jstat统计信息,一共执行10次jstat统计
通过这个命令,你可以非常灵活的对线上机器通过固定频率输出统计信息,观察每隔一段时间的jvm中的Eden区对象占用变化。
比如给大家举个例子,执行这个命令之后,第一秒先显示出来Eden区使用了200MB内存,第二秒显示出来的那行统计信息里,发信Eden区使用了205MB内存,第三秒显示出来的那行统计信息里,发现Eden区使用了209MB内存,以此类推。
此时你可以轻易的推断出来,这个系统大概每秒钟会新增5MB左右的对象。
也就是说,新生代对象增长速率,只需要关注eden区的增长速率即可。
而且这里大家可以根据自己系统的情况灵活多变的使用,比如你们系统负载很低,不一定每秒都有请求,那么可以把上面的1秒钟调整为1分钟,甚至10分钟,去看你们系统每隔1分钟或者10分钟大概增长多少对象。
还有就是一般系统都有高峰和日常两种状态,比如系统高峰期用的人很多,此时你就应该在系统高峰期去用上述命令看看高峰期的对象增长速率。然后你再得在非高峰的日常时间段内看看对象的增长速率。
按照上述思路,基本上你可以对线上系统的高峰和日常两个时间段内的对象增长速率有很清晰的了解。
详情参见上面例子
Young GC的触发频率和每次耗时
接着下一步我们就想知道大概多久会触发一次Young GC,以及每次Young GC的耗时了。
其实多久触发一次Young GC就很容易推测出来了,因为系统高峰和日常时候的对象增长速率你都知道了,那么非常简单就可以推测出来高峰期多久发生一次Young GC,日常期多久发生一次Young GC。
比如你Eden区有800MB内存,那么发现高峰期每秒新增5MB对象,大概高峰期就是3分钟左右会触发一次Young GC。日常期每秒新增0.5MB对象,那么日常期大概需要半个小时才会触发一次Young GC。
那么每次Young GC的平均耗时呢?
简单,之前给大家说过,jstat会告诉你迄今为止系统已经发生了多少次Young GC(ygc参数)以及这些Young GC的总耗时(ygct参数)。
比如系统运行24小时后共发生了260次Young GC,总耗时为20s。那么平均下来每次Young GC大概就耗时几十毫秒的时间。
你大概就知道每次Young GC的时候会导致系统停顿几十毫秒。
详情参见上面的例子
每次Young GC后有多少对象是存活和进入老年代
接着我们想要知道,每次Young GC后有多少对象会存活下来,以及有多少对象会进入老年代。
其实每次Young GC过后有多少对象会存活下来,这个没法直接看出来,但是有办法可以大致推测出来。
之前我们已经推算出来高峰期的时候多久发生一次Young GC,比如3分钟会有一次Young GC
那么此时我们可以执行下述jstat命令:jstat -gc PID 180000 10。这就相当于是让他每隔三分钟执行一次统计,连续执行10次。
此时大家可以观察一下,每隔三分钟之后发生了一次Young GC,此时Eden、Survivor、老年代的对象变化。
正常来说,Eden区肯定会在几乎放满之后重新变得里面对象很少,比如800MB的空间就使用了几十MB。Survivor区肯定会放入一些存活对象,老年代可能会增长一些对象占用。所以这里的关键,就是观察老年代的对象增长速率。
从一个正常的角度来看,老年代的对象是不太可能不停的快速增长的,因为普通的系统其实没那么多长期存活的对象。如果你发现比如每次Young GC过后,老年代对象都要增长几十MB,那很有可能就是你一次Young GC过后存活对象太多了。
存活对象太多,可能导致放入Survivor区域之后触发了动态年龄判定规则进入老年代,也可能是Survivor区域放不下了,所以大部分存活对象进入老年代。
最常见的就是这种情况。如果你的老年代每次在Young GC过后就新增几百KB,或者几MB的对象,这个还算情有可缘,但是如果老年代对象快速增长,那一定是不正常的。
所以通过上述观察策略,你就可以知道每次Young GC过后多少对象是存活的,实际上Survivor区域里的和进入老年代的对象,都是存活的。
你也可以知道老年代对象的增长速率,比如每隔3分钟一次Young GC,每次会有50MB对象进入老年代,这就是年代对象的增长速率,每隔3分钟增长50MB。
接下来看个例子:
jvm参数:
|
java代码
|
大概意思其实就是,每秒钟都会执行一次loadData()方法,他会分配4个10MB的数组,但是都立马成为垃圾,但是会有data1和data2两个10MB的数组是被变量引用必须存活的,此时Eden区已经占用了六七十MB空间了,接着是data3变量依次指向了两个10MB的数组,这是为了在1s内触发Young GC的。
接着我们基于jstat分析程序运行的状态,启动程序后立马采用jstat监控其运行状态可以看到如下的信息:
|

接着我们一点点来分析这个jvm的运行状态。首先我们先看如下一行截图:
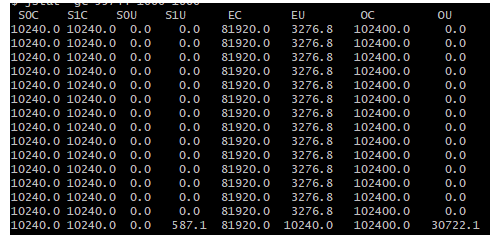
前面没有变化是因为,sleep30秒没有结束,还未进入代码逻辑。sleep30秒结束后,注意观察ygc的变化,jstat命令每输出一行日志,ygc的值就会增加1(符合代码的,1s进行一次ygc)
在这里最后一行,可以清晰看到,程序运行起来之后,突然在一秒内就发生了一次Young GC,这是为什么呢?
很简单,按照我们上述的代码,他一定会在一秒内触发一次Young GC的。
Young GC过后,我们发现S1U,也就是一个Survivor区中有587KB的存活对象,这应该就是那些未知对象了。
然后我们明显看到在OU中多出来了30MB左右的对象,因此可以确定,在这次Young GC的时候,有30MB的对象存活了,此时因为Survivor区域放不下,所以直接进入老年代了。
我们接着看下面的截图:
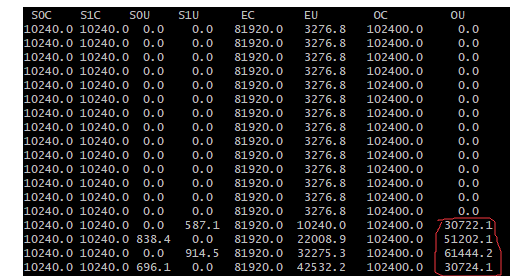
大家看上图中红圈的部分,很明显每秒会发生一次Young GC,都会导致20MB~30MB左右的对象进入老年代
因为每次Young GC都会存活下来这么多对象,但是Survivor区域(survivor才20M)是放不下的,所以都会直接进入老年代。
此时看到老年代的对象占用从30MB一路到60MB左右,此时突然在60MB之后下一秒,明显发生了一次Full GC,对老年代进行了垃圾回收,因为此时老年代重新变成30MB了。
为啥会这样?
很简单,老年代总共就100MB左右,已经占用了60MB了,此时如果发生一次Young GC,有30MB存活对象要放入老年代的话,你还要放30MB对象,明显老年代就要不够了,此时必须会进行Full GC,回收掉之前那60MB对象,然后再放入进去新的30MB对象。
所以大家可以看到,按照我们的这段代码,几乎是每秒新增80MB左右,触发每秒1次Young GC,每次Young GC后存活下来20MB~30MB的对象,老年代每秒新增20MB~30MB的对象,触发老年代几乎三秒一次Full GC。
Young GC太频繁,而且每次GC后存活对象太多,频繁进入老年代,频繁触发老年代的GC。
那么Young GC和Full GC的耗时呢?看下图:

大家看上图,有没有发现Young GC特别坑爹,28次Young GC,结果耗费了180毫秒,平均下来一次Young GC要6毫秒左右。但是14次Full GC才耗费34毫秒,平均下来一次Full GC才耗费两三毫秒。这是为什么呢?
很简单,按照上述程序,每次Full GC都是由Young GC触发的,因为Young GC过后存活对象太多要放入老年代,老年代内存不够了触发Full GC,所以必须得等Full GC执行完毕了,Young GC才能把存活对象放入老年代,才算结束。这就导致Young GC也是速度非常慢。
对JVM性能进行优化
接着我们按照之前学习的思路对JVM进行优化,很简单,他最大的问题就是每次Young GC过后存活对象太多了,导致频繁进入老年代,频繁触发Full GC
我们只需要调大年轻代的内存空间,增加Survivor的内存即可,看如下JVM参数:
|
我们把堆大小调大为了300MB,年轻代给了200MB,同时“-XX:SurvivorRatio=2”表明,Eden:Survivor:Survivor的比例为2:1:1,所以Eden区是100MB,每个Survivor区是50MB,老年代也是100MB。
接着我们用这个JVM参数运行程序,用jstat来监控其运行状态如下:

在上述截图里,大家可以清晰看到,每秒的Young gC过后,都会有20MB左右的存活对象进入Survivor,但是每个Survivor区都是50MB的大小,因此可以轻松容纳,而且一般不会过50%的动态年龄判定的阈值。
我们可以清晰看到每秒触发Yuong GC过后,几乎就没有对象会进入老年代,最终就600KB的对象进入了老年代里,其他就没有对象进入老年代了。
再看下面的截图:
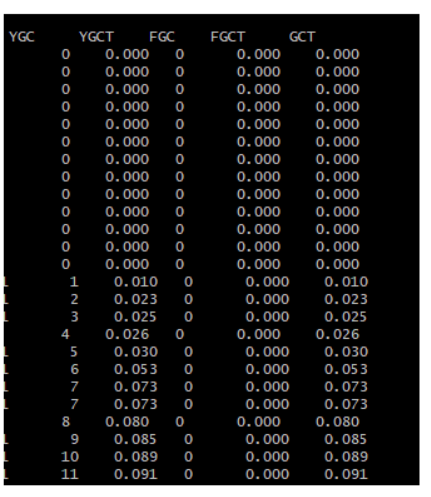
我们可以看到,只有Young GC,没有Full GC,而且11次Young GC才不过9毫秒(11/(0.091*1000) =9ms ),平均一次GC1毫秒都不到,没有Full GC干扰之后,Young GC的性能极高。
所以,其实这个案例就优化成功了,同样的程序,仅仅是调整了内存分配比例,立马就大幅度提升了JVM的性能,几乎把Full GC给消灭掉了。
Full GC的触发时机和耗时
只要知道了老年代对象的增长速率,那么Full GC的触发时机就很清晰了,比如老年代总共有800MB的内存,每隔3分钟新增50MB对象,那么大概每小时就会触发一次Full GC。
然后可以看到jstat打印出来的系统运行起劲为止的Full GC次数以及总耗时,比如一共执行了10次Full GC,共耗时30s,每次Full GC大概就是需要耗费3s左右。
需要摸清系统这些参数值
按照上述我们介绍的思路,把以下jvm运行情况全部摸出来:
- 新生代对象增长的速率
- Young GC的触发频率
- Young GC的耗时
- 每次Young GC后有多少对象是存活下来的
- 每次Young GC过后有多少对象进入了老年代
- 老年代对象增长的速率
- Full GC的触发频率
- Full GC的耗时
这有了解了系统的这些参数,那么才能根据机器的配置更好的配置jvm的参数。

