什么是内存溢出?在哪些区域会发生内存溢出?
原理解析
内存溢出其实很简单,那就是,某个内存空间是固定的,当他满了之后,再往里面添加数据的时候。放不下,那么就会溢出 – 内存溢出
那么什么叫内存泄漏?举个例子,比如一堆对象在老年代里占用了某些内存,但是他始终不释放这些内存。那么就有可能引发内存溢出。
所以说,内存泄漏时内存溢出的一种原因。
运行一个Java系统就是运行一个JVM进程
首先的话呢,大家得先搞明白一个事情,就是我们平时说启动一个Java系统,其实本质就是启动一个JVM进程。
咱们就用最最基本的情况来给大家演示一下好了,比如说下面的一段代码,是每个Java初学者都会写的一段代码:

那么大家知道,当你在Eclipse或者Intellij IDEA中写好这个代码,然后通过IDE来运行这个代码的时候,会发生哪些事情吗?
首先,我们知道后缀为“.java”的源代码,这个代码是不能运行的。
所以第一步就是这份“java”源代码文件必须先编译成一个“.class”字节码文件,这个字节码文件才是可以运行的。接着对于这种编译好的字节码文件,比如HelloWorld.class,如果里面包含了main方法,接下来我们就可以用“java命令”来在命令行执行这个字节码文件了。
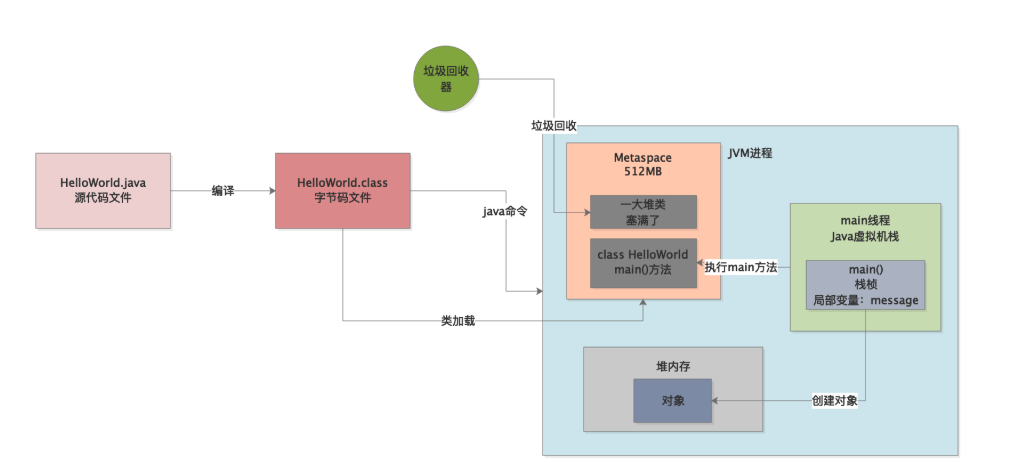
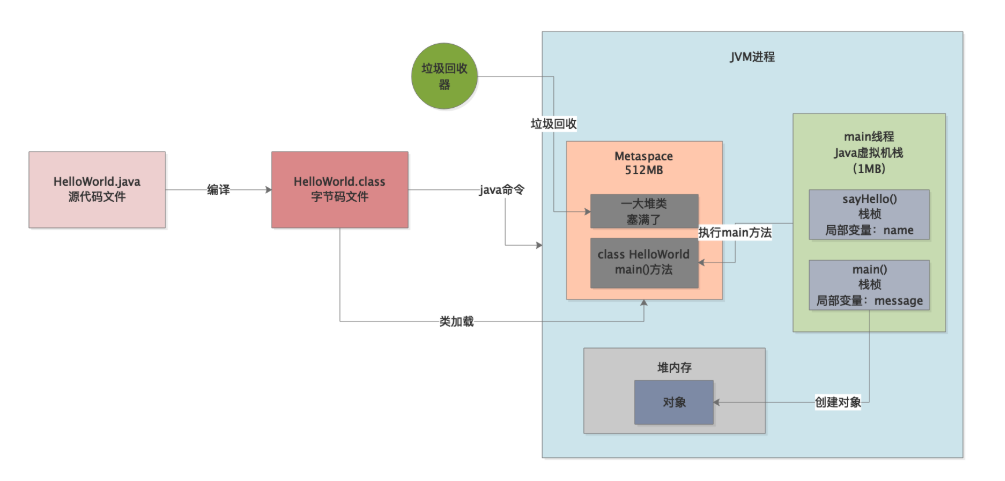
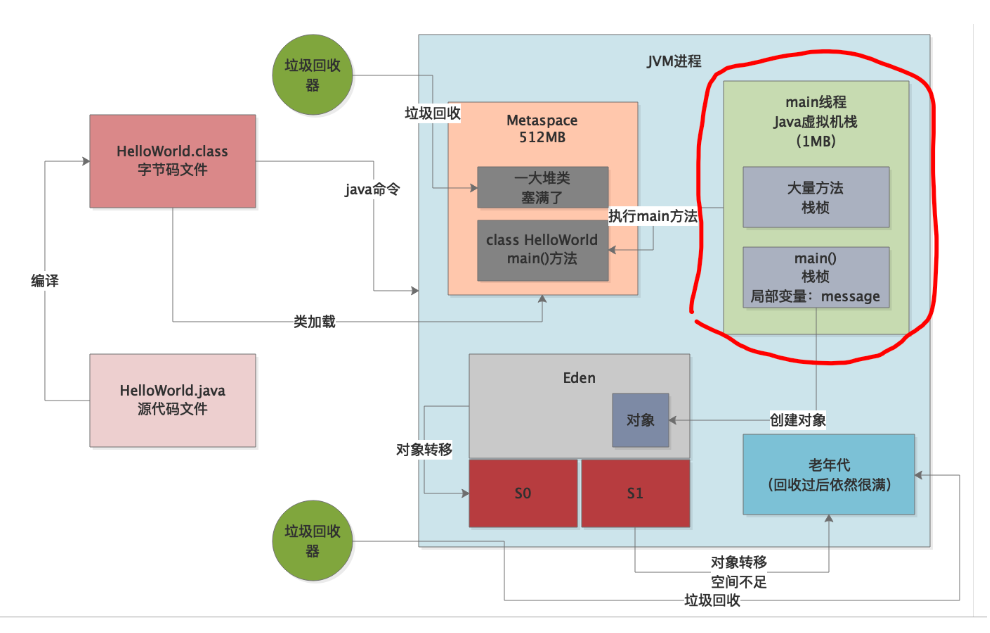
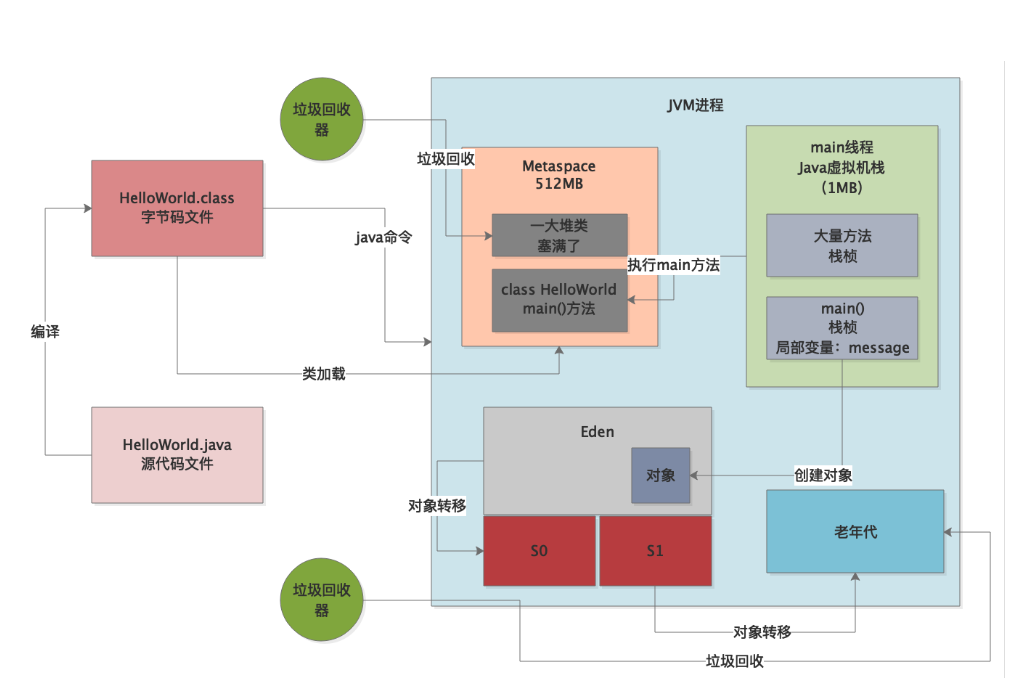
实际上一旦你执行“java命令”,相当于就会启动一个JVM进程。这个JVM进程就会负责去执行你写好的那些代码,如下图所示。
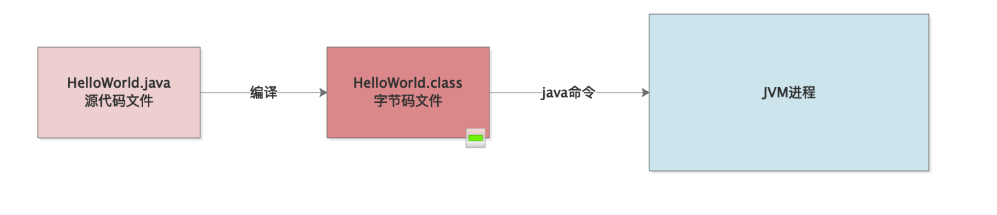
所以首先要清楚第一点,运行一个Java系统,本质上就是启动一个JVM进程,这个JVM进程负责来执行你写好的一大堆代码。只要你的Java系统中包含一个main方法,接着JVM进程就会从你指定的这个main方法入手,开始执行你写的代码。
到底执行哪些代码:JVM得加载你写的类
下一个问题,JVM进程怎么执行你写的那些代码呢?
大家都知道,Java是一个面向对象的语言,所以最最基本的代码组成单元就是一个一个的类,平时我们说写Java代码,不就是写一个一个的类吗?是不是。
然后在一个一个的类里我们会定义各种变量,方法,数据结构,通过if else之类的语法,写出来各种各样的系统业务逻辑,这就是所谓的编程了。
所以JVM既然要执行你写的代码,首先当然得把你写好的类加载到内存里来啊!
所以JVM的内存区域里大家都知道,有一块区域叫做永久代,当然JDK 1.8以后都叫做Metaspace了,我们也用最新的说法好了。
这块内存区域就是用来存放你系统里的各种类的信息的,包括JDK自身内置的一些类的信息,都在这块区域里。
JVM有类加载器和一套类加载的机制,之前的章节已经说过,这里不再赘述,他会负责把我们写好的类从编译好的“.class”字节码文件里加载到内存里来,如下图。
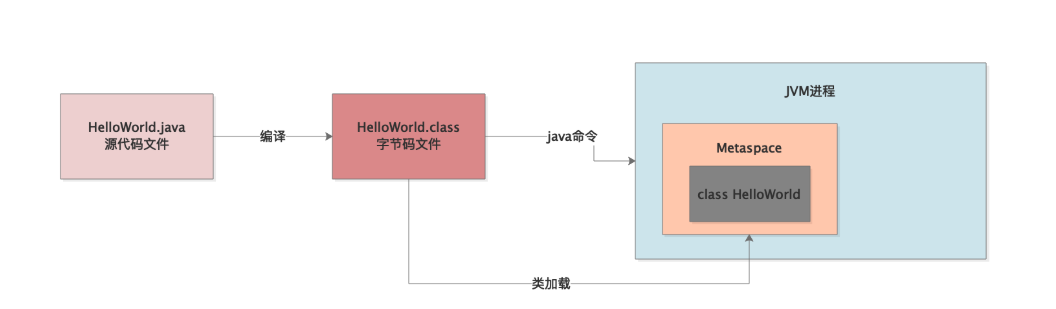
好,那么既然有这么一块Metaspace区域是用来存放类信息的,那是不是有可能在这个Metaspace区域里就会发生OOM?
没错,是有这种可能的。而且上面的文章《Metadata GC 引发的full gc 》就是因为元数据空间内存溢出而导致的full gc
Java虚拟机栈:让线程执行各种方法
大家都知道,我们写好的那些Java代码虽然是一个一个的类,但是其实核心的代码逻辑一般都是封装在类里面的各种方法中的
比如JVM已经加载了我们写好的HelloWorld类到内存里了,接着怎么执行他里面的代码呢?
Java语言中的一个通用的规则,就是一个JVM进程总是从main方法开始执行的,所以我们既然在HelloWorld中写了一个main()方法,那么当然得执行这个方法中的代码了。
但是等一等,JVM进程里的谁去执行main()方法的代码?
其实我们所有的方法执行,都必须依赖JVM进程中的某个线程去执行,你可以理解为线程才是执行我们写的代码的核心主体。
JVM进程启动之后默认就会有一个main线程,这个main线程就是专门负责执行main()方法的。
大家如下图所示。
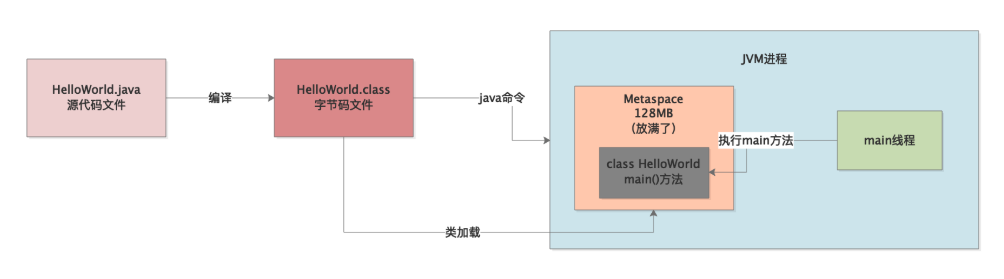 现在又有一个问题了,在main()方法里定义了一个局部变量,“message”,那么大家回忆一下,这些方法里的局部变量可能会有很多,那么这些局部变量是放在哪里的呢?
现在又有一个问题了,在main()方法里定义了一个局部变量,“message”,那么大家回忆一下,这些方法里的局部变量可能会有很多,那么这些局部变量是放在哪里的呢?
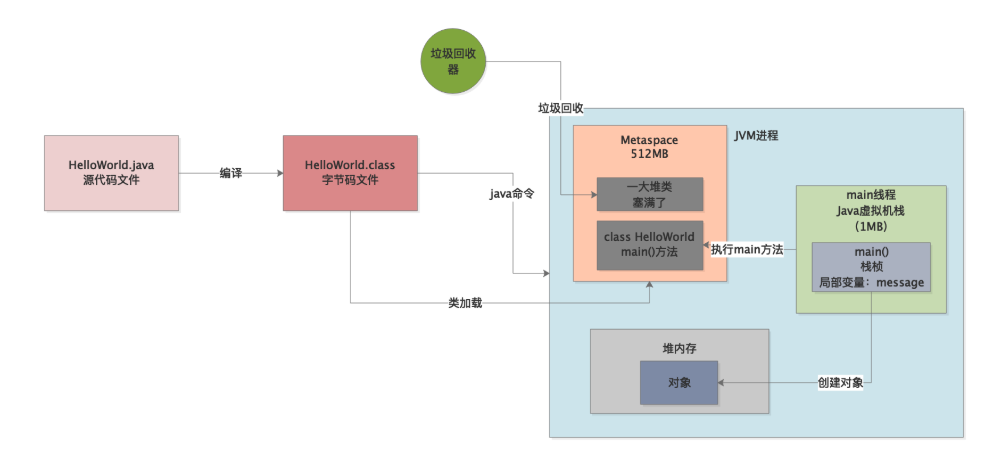
很简单,每个线程都有一个自己的虚拟机栈,就是所谓的栈内存。
然后这个线程只要执行一个方法,就会为方法创建一个栈桢,将栈桢放入自己的虚拟机栈里去,然后在这个栈桢里放入方法中定义的各种局部变量,如下图所示。
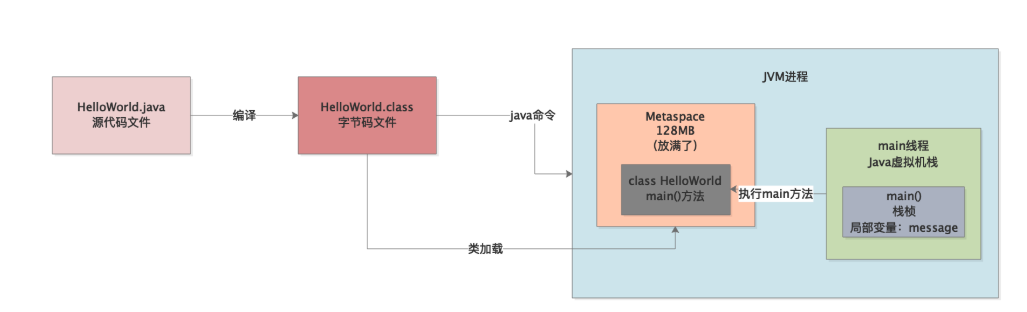 好,现在问题来了,大家如果还记得之前我们讲过的一个参数,应该都知道,我们是可以设置JVM中每个线程的虚拟机栈的内存大小的,一般是设置为1MB。
好,现在问题来了,大家如果还记得之前我们讲过的一个参数,应该都知道,我们是可以设置JVM中每个线程的虚拟机栈的内存大小的,一般是设置为1MB。
那么既然每个线程的虚拟机栈的内存大小是固定的,是否可能会发生虚拟机栈的内存溢出?
没错,所以第二块可能发生OOM的区域,就是每个线程的虚拟机栈内存。
堆内存:放我们创建的各种对象
最后我们知道,我们写好的代码里,特别在一些方法中,可能会频繁的创建各种各样的对象,这些对象都是放在堆内存里的,如下图所示。
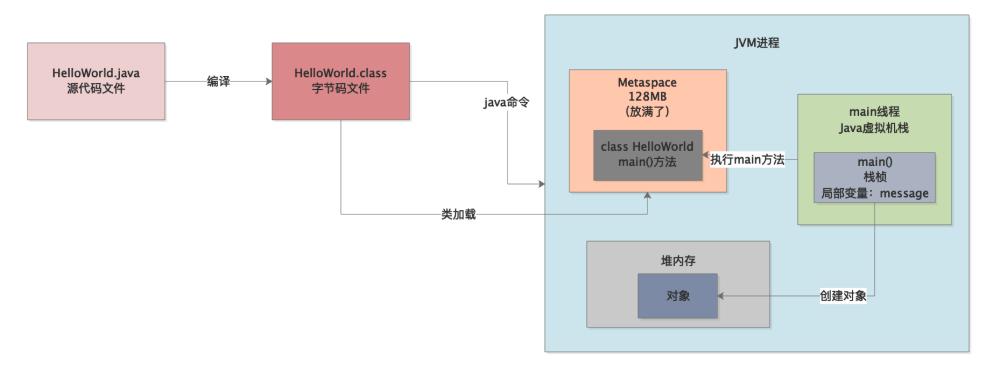
而且我们通过之前的学习,也都知道了一点,通常我们在JVM中分配给堆内存的空间其实一般是固定的。
既然如此,我们还不停在堆内存里创建对象,是不是说明,堆内存也有可能会发生内存溢出?
没错,第三块可能发生内存溢出的区域,就是堆内存空间!
本节总结
也就是说:元数据空间、java虚拟机栈、堆内存(老年代的oom)。这三块内存有可能发生内存溢出的。
Metaspace区域是如何因为类太多而发生内存溢出的?
原理解析
Metaspace区域是如何触发内存溢出的?
好,我们通过之前的学习都知道,在启动一个JVM时是可以设置很多参数的,其中有一些参数就是专门用来设置Metaspace区域的内存大小的,大家如果有遗忘的回顾一下之前的文章即可。
如下两个参数就是用来设置Metaspace区域大小的:
|
我们看下图,图中我们就限定了Metaspace区域的内存大小为512m。
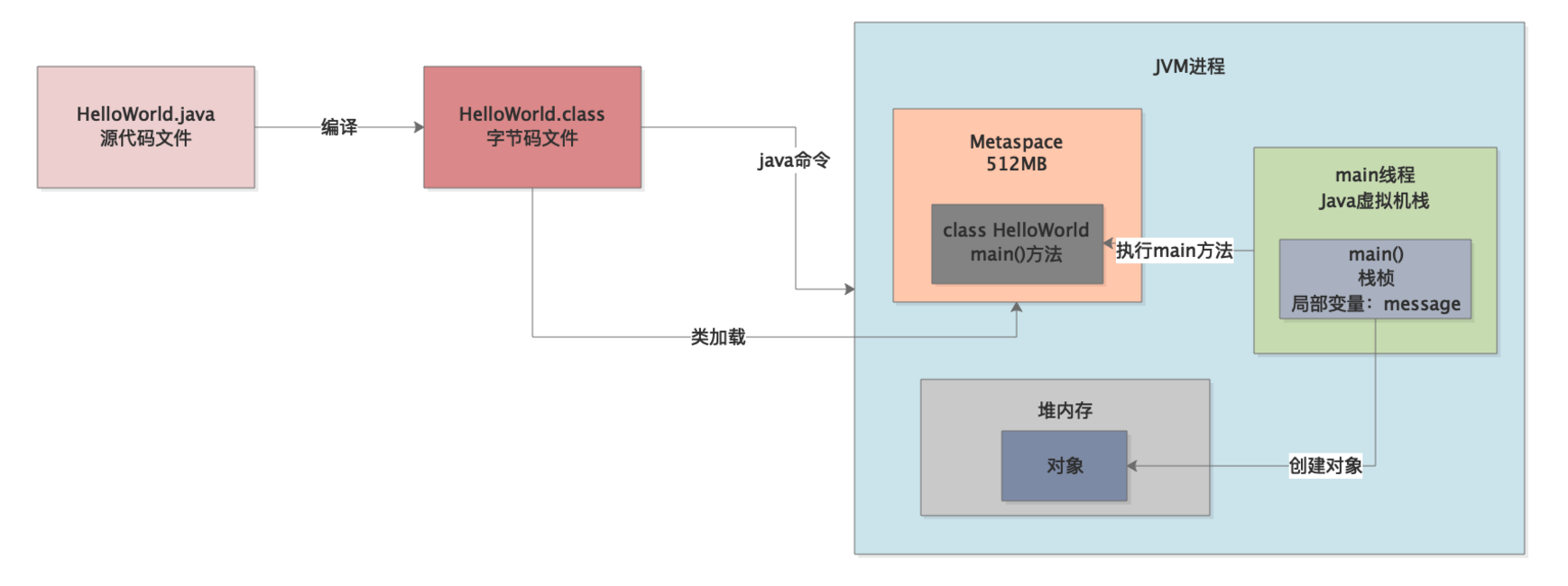
所以实际上来说,在一个JVM中,Metaspace区域的大小是固定的,比如512MB。
那么一旦JVM不停地加载类,加载了很多很多的类,然后Metaspace区域放满了,此时会如何?大家看下图。
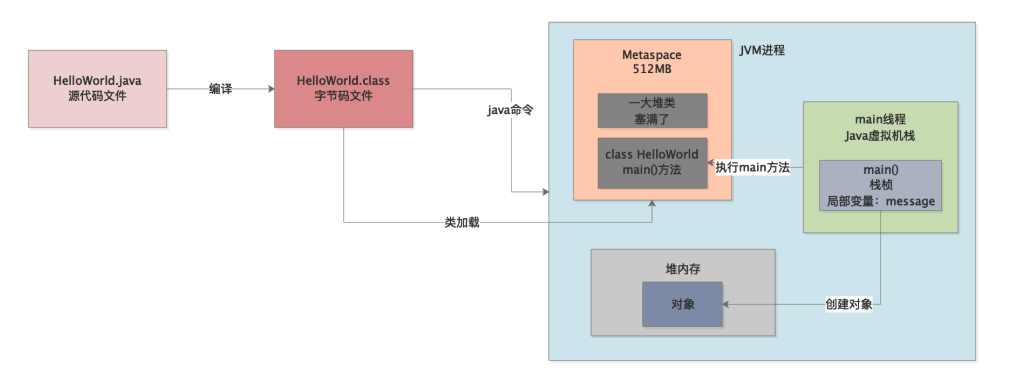
大家如果还记得之前我们说过的频繁Full GC触发的几个问题,其中之一就是Metaspace区域满就会触发Full GC,Full GC会带着一块进行Old GC就是回收老年代的,也会带着回收年轻代的Young GC。
当然,Full GC的时候,必然会尝试回收Metaspace区域中的类(记住,这里只是尝试,因为回收元数据空间的内存条件很多),如下图所示。
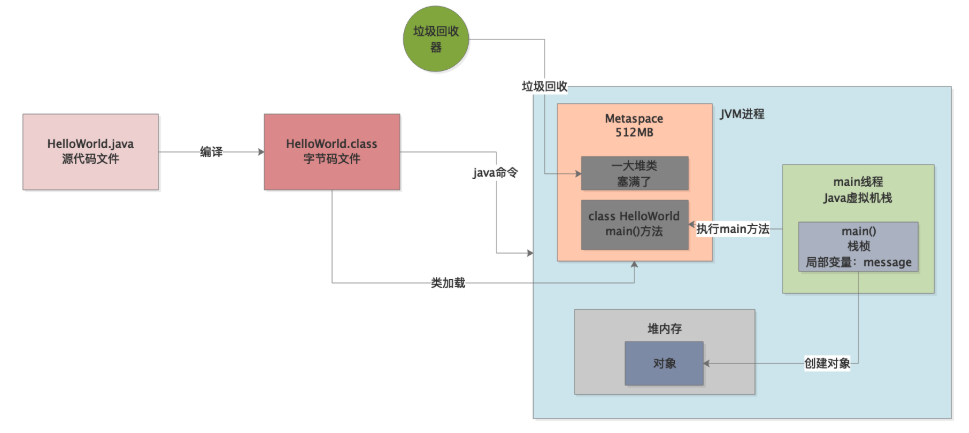
所以一旦Metaspace区域满了,此时会触发Full GC,连带着回收Metaspace里的类。
那么什么样的类才是可以被回收的呢?
这个条件是相当的苛刻,包括不限于以下一些:比如这个类的类加载器先要被回收,比如这个类的所有对象实例都要被回收,这个类的class对象没有被引用(三大条件),等等。
所以一旦你的Metaspace区域满了,未必能回收掉里面很多的类。
那么一旦回收不了多少类,此时你的JVM还在拼命的加载类放到Metaspace里去,你觉得此时会发生什么事情?
显而易见,一旦你尝试回收了Metaspace中的类之后发现还是没能腾出来太多空间,此时还要继续往Metaspace中塞入更多的类,直接就会引发内存溢出的问题。因为此时Metaspace区域的内存空间不够了。
一旦发生了内存溢出就说明JVM已经没办法继续运行下去了,此时可能你的系统就直接崩溃了,这就是Metaspace区域发生内存溢出的一个根本的原理。
到底什么情况下会发生Metaspace内存溢出?
平心而论,Metaspace这块区域一般很少发生内存溢出,如果发生内存溢出一般都是因为两个原因:
第一种原因,很多工程师他不懂JVM的运行原理,在上线系统的时候对Metaspace区域直接用默认的参数,即根本不设置其大小。
- 这会导致默认的Metaspace区域可能才几十MB而已,此时对于一个稍微大型一点的系统,因为他自己有很多类,还依赖了很多外部的jar包有有很多的类,几十MB的Metaspace很容易就不够了。
- 第二种原因,就是很多人写系统的时候会用cglib之类的技术动态生成一些类,一旦代码中没有控制好,导致你生成的类过于多的时候,就很容易把Metaspace给塞满,进而引发内存溢出。
对于第一种问题,通常来说,有经验的工程师上线系统往往会设置对应的Metaspace大小,推荐的值在512MB那样,一般都是足够的。
对于第二种问题,应避免无限制的动态生成类,后面会通过代码演示。
本节总结
大家以后只要记得,合理分配Metaspace区域(一般是给512M),同时避免无限制的动态生成类。一般这块区域其实都是比较安全的,不至于会触发内存溢出的。
疑问
有的人说,因为jdk1.8以后,元数据空间使用的是物理内存(电脑内存)而不是堆内存,实际上是不会发生内存溢出的,这种说法对不对?
答案是:不对,请看后面章节的事例
案例分析
首先我们回顾一下,metadata空间中什么样的类才是可以被回收的呢?
这个条件是相当的苛刻,包括不限于以下一些:
这个类的类加载器先要被回收
这个类的所有对象实例都要被回收
这个类的class对象没有被引用等等。
接下来我们通过cglib,动态的生成类,来模拟,metada内存溢出。
**到底什么是动态生成类?动态代理
可能有的人不太理解什么叫做动态生成类,其实很简单,我们平时正常情况下,类都是通过自己的双手一行一行代码写出来的,而且都是写的“.java”后缀的源代码文件,大家想想是不是这样?
大家回忆一下,平时我们自己写出来的类大致长什么样子?是不是一般都包含一些静态变量、实例变量、静态方法、实例方法,里面还有一大堆的业务逻辑?大致其实类就是这么个东西。
所以既然你双手都能写出来这种普普通通的类,那么当然是有办法可以借助一些方法在系统运行的时候,通过程序动态的生成出更多的类了,这是没有问题的。
所以一旦我们程序中拼命的生成大量的类,而且这些类还不能被回收,那么必然会最终导致Metaspace区域被占满,进而导致Metaspace内存溢出了。
接着我们就来实际看看代码层面上,动态生成类到底是怎么做的吧!
一段CGLIB动态生成类的代码示例
首先引入cglib依赖
|
接着我们就可以使用CGLIB来动态生成类了,大家看下面的代码:
|
首先我们可以看到我们在这里定义了一个类,代表了一个汽车,他有一个run()方法,执行的时候就会启动汽车,开始让汽车行驶。
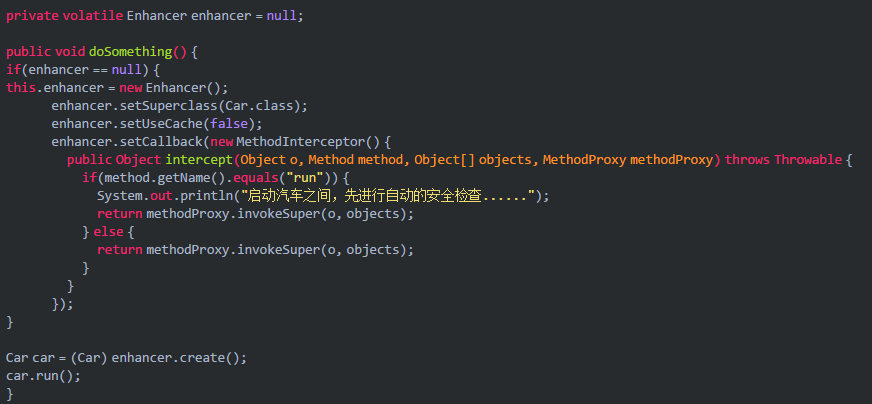
那么我们接着来看下面的代码片段,我们通过CGLIB的Enhancer类动态生成了一个Car类的子类。
注意,从这里开始,就是开始动态生成类了,大家要仔细看,看下面的代码片段:
|
你权且当做Enhancer是用来生成类的一个API吧,看到片段里我们给Enhancer设置了一个SuperClass没有?这里的意思就是说Enhancer生成的代理类是Car类的子类,Car类是生成类的父类。至于那个UseCache是什么意思,就先别管了。
既然Enhancer动态生成的类是Car的子类,那么是不是Car有的方法子类都有?所以子类是不是也有Car的run()方法?
答案是肯定的,但我们现在想要在调用子类的run()方法的时候做点手脚,如下面代码片段:
|
这个片段的意思是:如果你调用动态生成的子类对象的run()方法,会先被这里的MethodInterceptor拦截一下,拦截之后,各位看里面的代码,是不是判断了一下,如果你调用的Method是run方法,那么就先对汽车做一下安全检查。
安全检查做完之后,再通过“methodProxy.invokeSuper(o, objects);”调用父类Car的run()方法,去启动汽车,这行代码就会执行到Car类的run()方法里去了。
到此为止,我们就已经通过CGLIB的Enhancer生成了一个Car类的子类了,而且定义好了对这个子类调用继承自父类的run()方法的时候,先干点别的,再调用父类的run()方法。
这么一搞,是不是跟下面这种在IDE里手写一个Car的子类是类似的?
看看下面的手写版本的代码:

看看上面那个SafeCar作为Car的子类,是不是干了一样的事?
但是这个类需要你用双手提前写出来代码,而CGLIB Enhancer那种模式可以在系统运行期间动态的创建一个Car的子类出来,实现一样的效果。
看到这里,各位应该理解这个动态创建类了!
限制Metaspace大小看看内存溢出效果
接着我们可以设置一下这个程序的JVM参数,限制他的Metaspace区域比较小一点,如下所示,我们把这个程序的JVM中的Metaspace区域设置为仅仅10m:
|
接着我们可以在上述代码中做点手脚,大家看到上面的代码是有一个while循环的,所以他会不停的创建Car类的子类
接着大家用上述JVM参数来运行这个程序即可,可以看到如下所示的打印输出:
|
大家注意一下上述异常日志的两个地方,一个是在创建了637个类之后,10M的Metaspace区域就被耗尽了,接着就会看到异常中有如下的一个:
|
这个OutOfMemoryError就是经典的内存溢出的问题,而且他明确告诉你,是Metaspace这块区域内存溢出了。
而且大家可以看到,一旦内存溢出,本来在运行的JVM进程直接会崩溃掉,你的程序会退出,这就是真实的内存溢出的日志。
进阶分析 jvisualvm工具和堆内存镜像分析
为了便于观察我们把,metaspace增加10倍,并设置在oom的时候,
为了便于观察,我们通过增加10倍的metaspace(便于启动jvisualvm工具观察,否则程序运行太快就结束了),同时在oom的时候导出堆内存快照便于分析。
完整jvm参数如下:
|
dump出来的堆内存快照,他会用你的PID进程id作为文件名字。
然后打开jdk的bin目录下的jvisualvm.exe 工具,运行程序。程序输出日志:
|
可以看到,一共动态创建了8209个Car类的子类。
首先查看打印出来的gc1.log日志
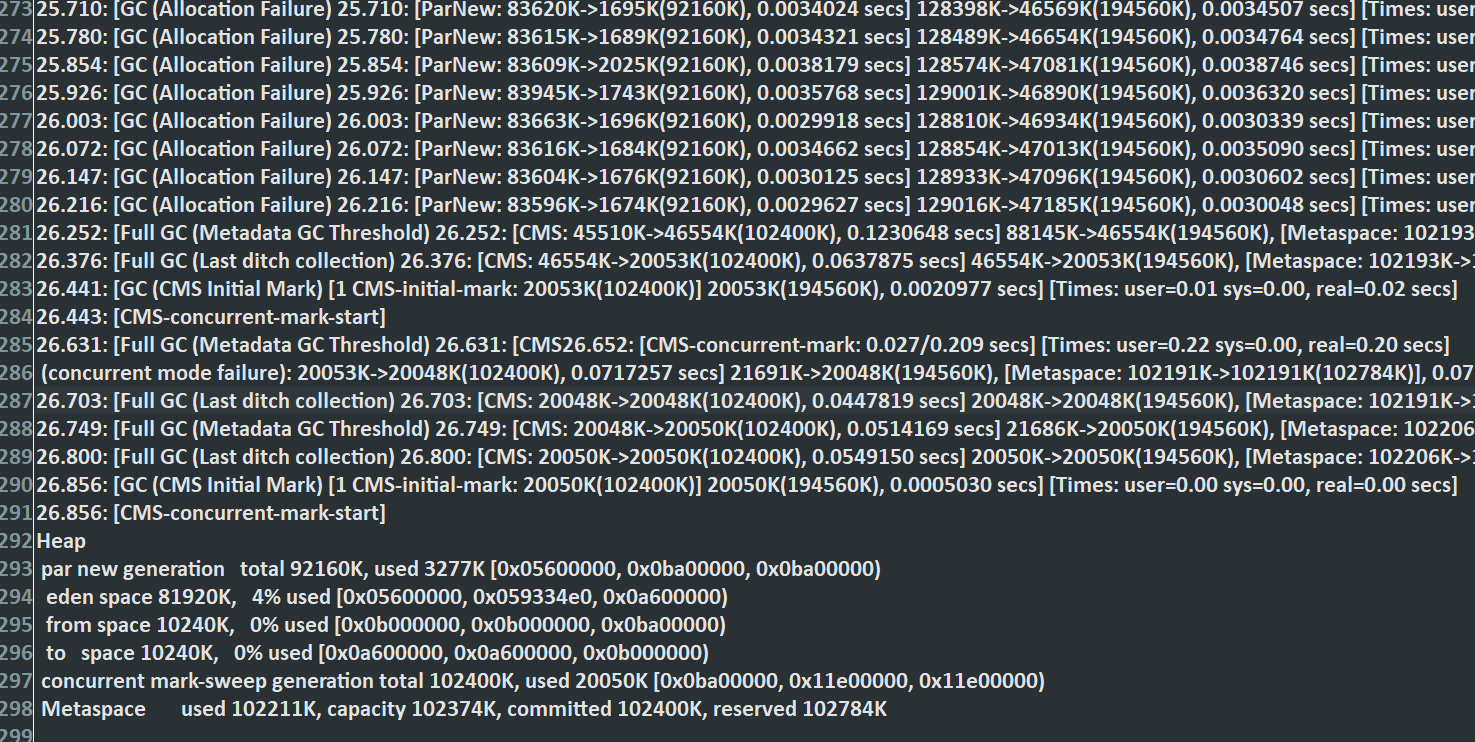
可以看到,进行了多次的ygc,因此上述代码不光是动态生成类,本身他也是对应很多对象的,因此你在while(true)循环里不停的创建对象,当然会塞满Eden区,从而发生了ygc。
0.771: [Full GC (Metadata GC Threshold) 0.771: [CMS: 0K->2161K(349568K), 0.0721349 secs] 20290K->2161K(506816K), [Metaspace: 9201K->9201K(1058816K)], 0.0722612 secs] [Times: user=0.12 sys=0.03, real=0.08 secs]
接着我们来看这次GC,这就是Full GC了,而且通过“Metadata GC Threshold”清晰看到,是Metaspace区域满了,所以触发了Full GC。
这个时候看下面的日志,20290K->2161K(506816K),这个就是说堆内存(年轻代+老年代)一共是500MB左右,然后有20MB左右的内存被使用了,这个必然是年轻代用的。
然后Full GC必然会带着一次Young GC,因此这次Full GC其实是执行了ygc了,所以回收了很多对象,剩下了2161KB的对象,这个大概就是JVM的一些内置对象了。
然后直接就把这些对象放入老年代,为什么呢,因为下面的日志:[CMS: 0K->2161K(349568K), 0.0721349 secs]
这里明显说了,Full GC带着CMS进行了老年代的Old GC,结果人家本来是0KB,什么都没有,然后从年轻代转移来了2161KB的对象,所以老年代变成2161KB了。
接着看日志: [Metaspace: 9201K->9201K(1058816K)]
此时Metaspace区域已经使用了差不多9MB左右的内存了,此时明显是发现离我们限制的10MB内存很接近了,所以触发了Full GC,但是对Metaspace GC后发现类全部存活了,因此还是剩余9MB左右的类在Metaspace里。
0.843: [Full GC (Last ditch collection) 0.843: [CMS: 2161K->1217K(349568K), 0.0164047 secs] 2161K->1217K(506944K), [Metaspace: 9201K->9201K(1058816K)], 0.0165055 secs] [Times: user=0.03 sys=0.00, real=0.01 secs]
接着又是这次Full GC,人家也说的很清晰了,Last ditch collection
就是说,最后一次拯救的机会了,因为之前Metaspace回收了一次但是没有类可以回收,所以新的类无法放入Metaspace了。
所以再最后试一试Full GC,能不能回收掉一些
结果如下:[Metaspace: 9201K->9201K(1058816K)], 0.0165055 secs]
Metaspace区域还是无法回收掉任何的类,几乎还是占满了我们设置的10MB左右。
0.860: [GC (CMS Initial Mark) [1 CMS-initial-mark: 1217K(349568K)] 1217K(506944K), 0.0002251 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
0.860: [CMS-concurrent-mark-start]
0.878: [CMS-concurrent-mark: 0.003/0.018 secs] [Times: user=0.05 sys=0.01, real=0.02 secs]
0.878: [CMS-concurrent-preclean-start]
Heap
par new generation total 157376K, used 6183K [0x00000005ffe00000, 0x000000060a8c0000, 0x0000000643790000)
eden space 139904K, 4% used [0x00000005ffe00000, 0x0000000600409d48, 0x00000006086a0000)
from space 17472K, 0% used [0x00000006086a0000, 0x00000006086a0000, 0x00000006097b0000)
to space 17472K, 0% used [0x00000006097b0000, 0x00000006097b0000, 0x000000060a8c0000)
concurrent mark-sweep generation total 349568K, used 1217K [0x0000000643790000, 0x0000000658cf0000, 0x00000007ffe00000)
Metaspace used 9229K, capacity 10146K, committed 10240K, reserved 1058816K
class space used 794K, capacity 841K, committed 896K, reserved 1048576K
接着就直接JVM退出了,退出的时候就打印出了当前内存的一个情况,年轻代和老年代几乎没占用,但是Metaspace的capacity是10MB,使用了9MB左右,无法再继续使用了,所以触发了内存溢出。
通过观察jvisualvm可以得到。
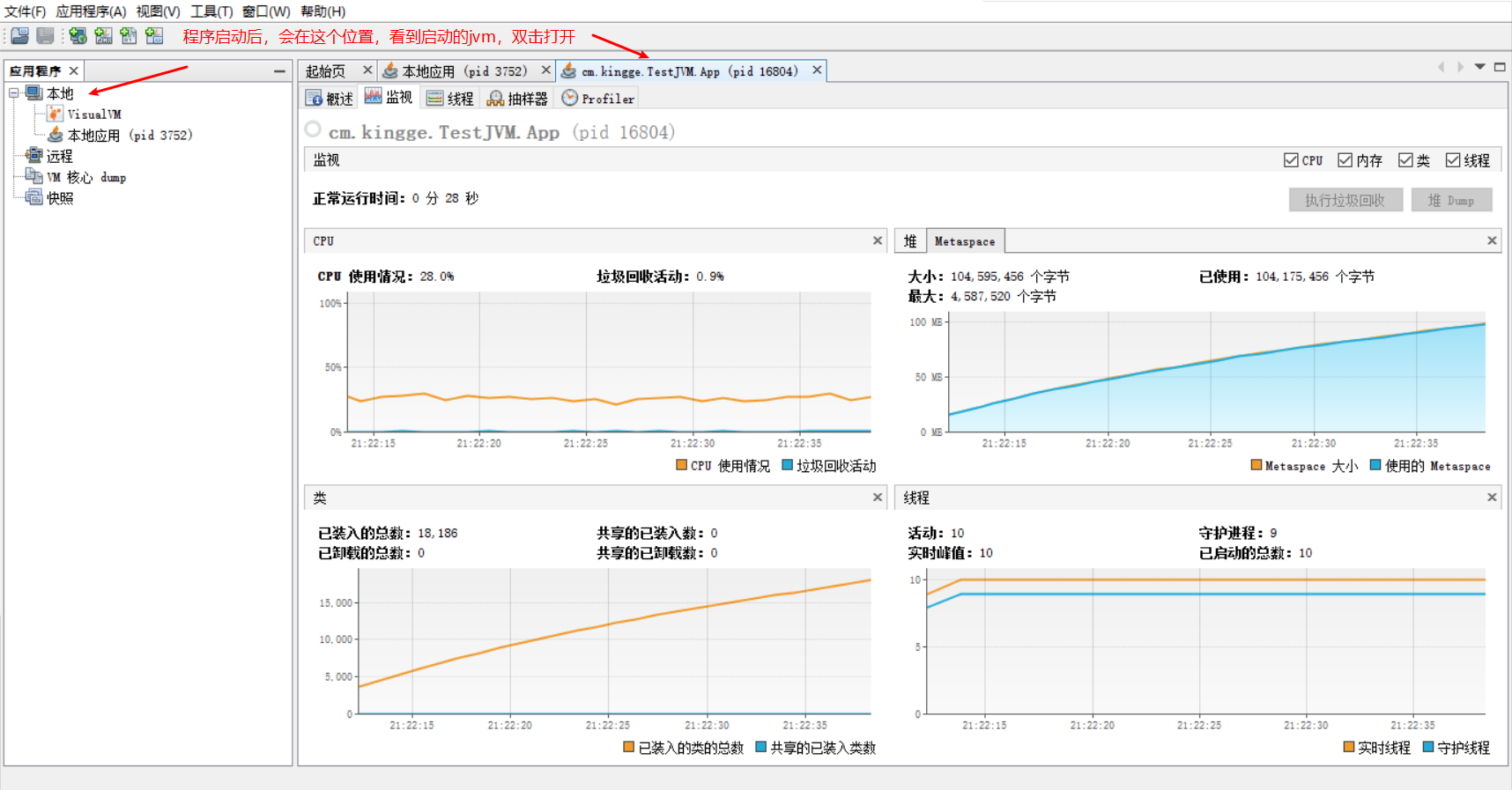
观察Metaspace区域,可以看到他的空间使用一直上涨,直到最大值100M,然后发生了OOM。持续的装入了18186个类在metaspace中。而且没有卸载,所以这个就是为什么OOM的原因。
打开生成的java_pid16804.hprof 堆内存快照。
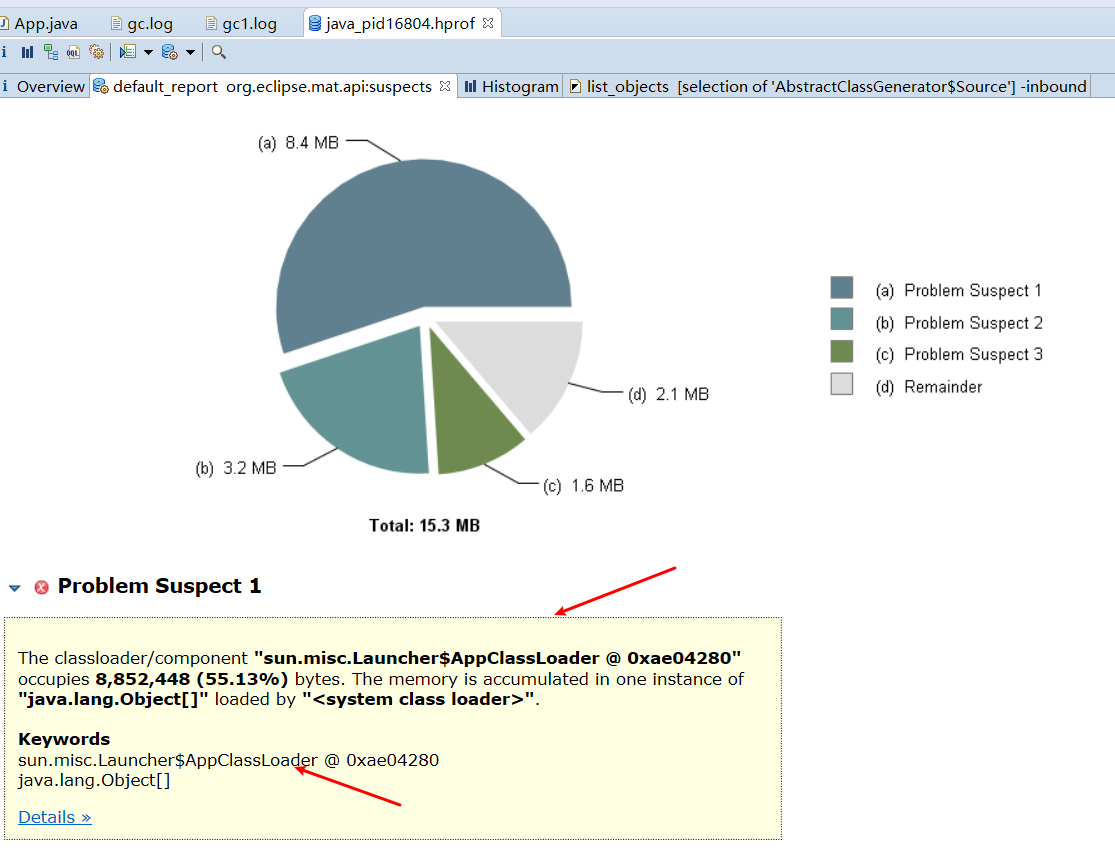
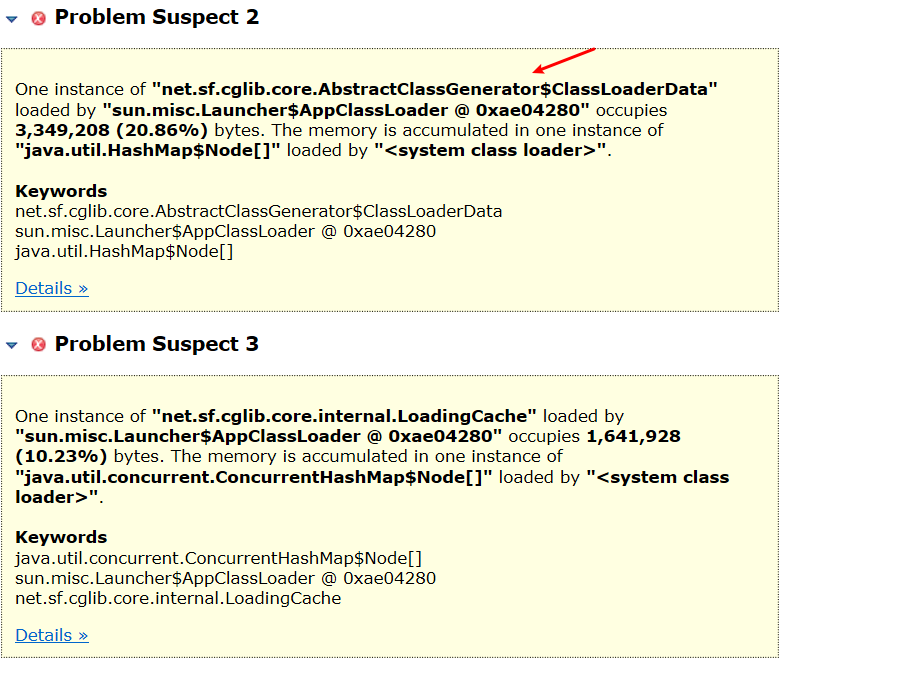
从这里可以看到实例最多的就是AppClassLoader,点击detail。
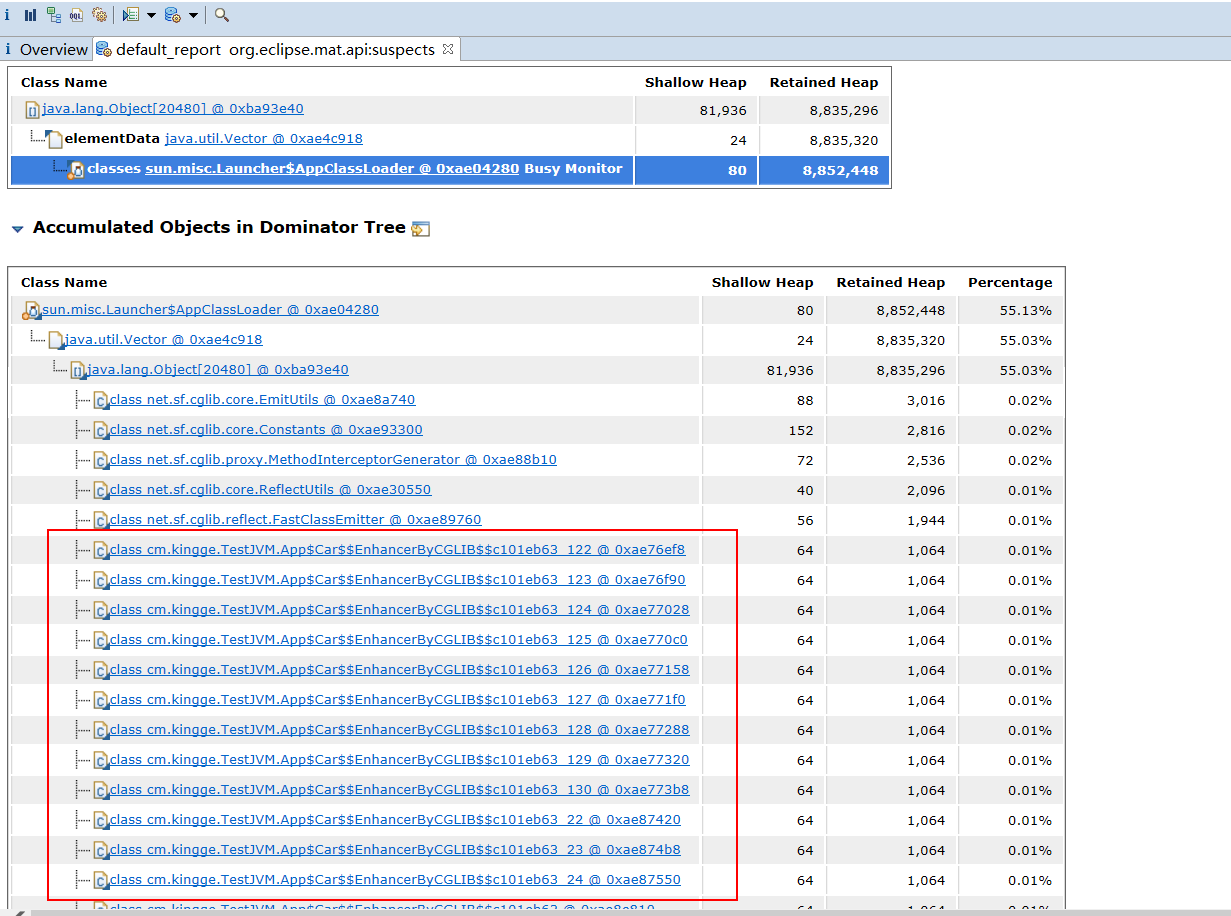
为什么这里有一大堆咱们自己的App中动态生成出来的Car$$EnhancerByCGLIB的类呢?
看到这里就真相大白了,上图已经清晰告诉我们,是我们自己的哪个类里搞出来了一大堆的动态生成的类,所以填满了Metaspace区域。
每次的while循环虽然结束了,但是cglib内部还是保留着Car.class的引用,所以导致没有回收掉,一直在增长。
所以此时直接去代码里排查动态生成类的代码即可。
解决方式
解决这个问题的办法也很简单,直接对Enhancer做一个缓存,只有一个,不要无限制的去生成类就可以了。
比如你用CGLIB的Enhancer针对某个类动态生成了一个子类,这个子类你完全可以缓存起来,下次直接用这个已经生成好的子类来创建对象就可以了。没必要每次调用都创建一次enhancer和一个Car子类。
类似下面这样:
其实这个类只要生成一次就可以了,下次来直接用这个动态生成的类创建一个对象就可以了。
java虚拟机栈溢出,无限制的调用方法是如何让线程的栈内存溢出的?
原理解析
因为在JVM加载了我们写的类到内存里之后,下一步就是去通过线程执行方法,此时就会有方法的入栈出栈相关的操作,那么我们来分析一下线程的栈内存到底是因为什么原因会导致溢出呢?
而且我们可以通过 -Xss来指定一个java虚拟机栈的内存,一般是1M。足够用了。
但是这里有个疑问,jvm总的能够分配的java虚拟机栈的内存是多少呢?有没有类似的-Xss这样的参数来进行设置呢?答案是没有。但是我们可以通过这个方式得到一个近似值:操作系统给进程分配的最大大小,减去堆内存(-Xmn)和永久代内存(-MetadataSize)再减去操作系统用掉的某部分内存,就是可分配的Java虚拟机栈的总内存大小。
那么启动的jvm支持创建多少个线程呢(估计)?那就是:可分配的Java虚拟机栈的总内存/1M。所以我们估计一下,假设-Xss设置为1M,那么能够分配多少个线程就等同于,可分配的Java虚拟机栈的总内存大小。
一个线程调用多个方法的入栈和出栈
大家先回顾一下之前我们画好的图,那个图是一个相对较为完整的JVM运行原理图,如下所示。
现在我们来看下面的代码:
|
按照我们之前所说的,JVM启动之后,HelloWorld类被加载到了内存里(metadata空间)来,然后就会通过main线程执行main()方法,此时在main线程的虚拟机栈里,就会压入main()方法对应的栈桢,里面就会放入main()方法中的局部变量。
大家看看上面的图,在图里是不是有main线程的虚拟机栈和main()方法的栈桢的概念?
而且我们还知道一个概念,就是我们是可以手动设置每个线程的虚拟机栈的内存大小的,一般来说现在默认都是给设置1MB。
所以看下图,main线程的虚拟机栈内存大小一般也是固定的。
现在回过头思考一下上面的代码,代码中是不是在main()方法中又继续调用了一个sayHello()方法?
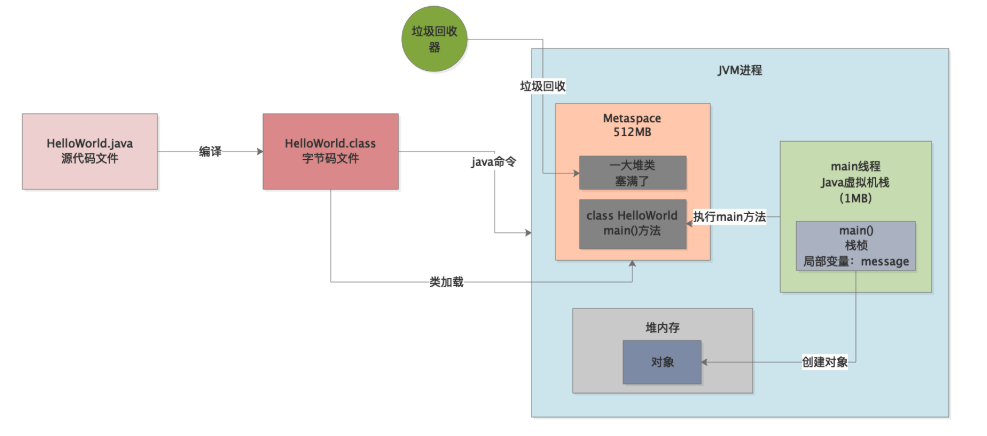
而且sayHello()方法中也会自己的局部变量,所以此时会继续将sayHello()方法的栈桢压入到main线程的虚拟机栈中去,如下图。
接着sayHello()方法如果运行完毕之后,就不需要为这个方法在内存中保存他的一些局部变量之类的东西了,此时就会将sayHello()方法对应的栈桢从main线程的虚拟机栈里出栈,如下图。
再接着,一旦main()方法自己本身也运行完毕,自然会将main()方法对应的栈桢也从main线程的虚拟机栈里出栈,这里我们就不在图里表示出来了。
也就是说,每个方法执行完成后,都会出栈,每个栈帧里面方法局部变量都会被销毁。
一个重要的概念:每次方法调用的栈桢都是要占用内存的
在这里,要给大家明确一个重要的概念,那就是每个线程的虚拟机栈的大小是固定的,比如可能就是1MB,然后每次这个线程调用一个方法,都会将本次方法调用的栈桢压入虚拟机栈里,这个栈桢里是有方法的局部变量的。
虽然说一些变量和其他的一些数据占用不了太大的内存,但是大家要记得,每次方法调用的栈桢实际上也是会占用内存的!
这是非常关键的一点,哪怕一个方法调用的栈桢就占用几百个字节的内存,那也是内存占用!
到底什么情况下会导致JVM中的栈内存溢出?
既然明确了上述前提之后,那么大家思考一下,到底什么情况下JVM中的栈内存会溢出呢?
其实非常简单,既然一个线程的虚拟机栈内存大小是有限的,比如1MB,那么假设你不停的让这个线程去调用各种方法,然后不停的把方法调用的栈桢压入栈中,是不是就会不断的占用这个线程1MB的栈内存?
如下图所示
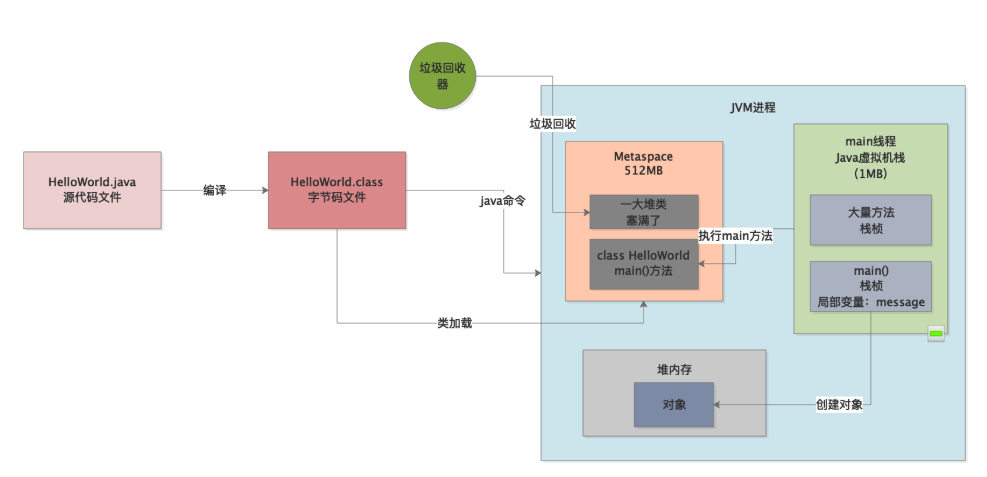
那么如果不停的让线程调用方法,不停的往栈里放入栈桢,此时终有一个时刻,大量的栈桢会消耗完毕这个1MB的线程栈内存,最终就会导致出现栈内存溢出的情况。
一般什么情况下会发生栈内存溢出?
那么一般什么情况下会发生栈内存溢出呢?
通常而言,哪怕你的线程的虚拟机栈内存就128KB,或者256KB,通常都是足够进行一定深度的方法调用的。
但是如果说你要是走一个递归方法调用,那就不一定了,看下面的代码。

一旦出现上述代码,一个线程就会不停的调用同一个方法,即使是同一个方法,每一次方法调用也会产生一个栈桢压入栈里,比如说对sayHello()进行100次调用,那么就会有100个栈桢压入中。
所以如果疯狂的运行上述代码,就会不停的将sayHello()方法的栈桢压入栈里,最终一定会消耗掉线程的栈内存,引发内存溢出。
所以一般来说,其实引发栈内存溢出,往往都是代码里写了一些bug才会导致的,正常情况下发生的比较少。
案例分析
重新分析一下JVM中的栈内存
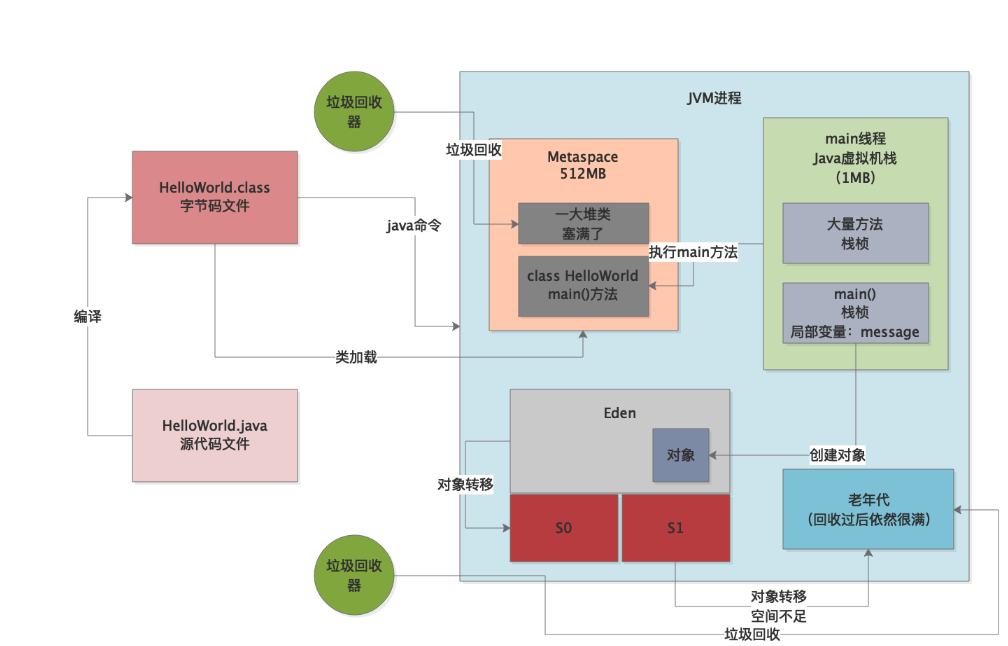
咱们先来简单的回顾一下JVM的整体运行原理,大家不要忘记下面这张图,必须牢牢印刻在自己的脑海里。
既然大家已经对Metaspace这块区域的内存溢出理解的很深刻了,那么接着我们来回顾一下栈内存这块区域的内存溢出。
讲到这里我们先带着大家来思考一下,JVM进程到底会占用机器上多少内存?
先不考虑一些细小的其他内存区域,就仅仅考虑一下最核心的几块就可以了,包括了:Metaspace区域,堆内存区域,各个线程的栈内存区域。
Metaspace区域我们一般会设置为512MB左右的大小,这个大小只要你代码里没有自己胡乱生成类,一般都是绝对足够存放你一个系统运行时需要的类的。
堆内存大小,之前在分析GC的时候给大家大量的分析过,堆内存一般分配在机器内存的一半就差不多了,毕竟还要考虑其他人对内存的使用。
那么最后一块内存区域我们之前一直没怎么给大家说过,就是栈内存区域。
其实大家考虑一个最基本的线上机器配置,比如4核8G的线上机器,其中512MB给了Metaspace,4G给了堆内存(其中包括了年轻代和老年代),剩余就只有3G左右内存了,要考虑到操作系统自己也会用掉一些内存。
那么剩余你就认为有一两个GB的内存可以留给栈内存好了。
通常来说,我们会设置每个线程的栈内存就是1MB,假设你一个JVM进程内包括他自带的后台线程,你依赖的第三方组件的后台线程,加上你的核心工作线程(比如说你部署在Tomcat中,那就是Tomcat的工作线程),还有你自己可能额外创建的一些线程,可能你一共JVM中有1000个线程。
那么1000个线程就需要1GB的栈内存空间,每个线程有1MB的空间。
所以基本上这套内存模型是比较合理的,其实一般来说,4核8G机器上运行的JVM进程,比如一个Tomcat吧,他内部所有的线程数量加起来在几百个是比较合理的,也就占据几百MB的内存,线程太多了,4核CPU负载也会过高,也并不好。
所以Metaspace区域+堆内存+几百个线程的栈内存,就是JVM一共对机器上的内存资源的一个消耗。
所以大家这里也能理解一个道理,你要是给每个线程的栈内存分配过大的空间,那么会导致机器上能创建的线上数量变少,要是给每个线程的栈内存相对较小,能创建的线程就会比较多一些。
当然一般来说,现在都建议给栈内存在1MB就可以了。
回顾一下栈内存溢出的原理
接着我们来回顾一下栈内存溢出的原理,其实特别的简单,大家看下图中画红圈的地方,其实每个线程的栈内存是固定的,要是你一个线程不停的无限制的调用方法,每次方法调用都会有一个栈桢入栈,此时就会导致线程的栈内存被消耗殆尽。
但是通常而言你的线程不至于连续调用几千次甚至几万次方法,对不对?一般发生这种情况,只有一个原因,就是你的代码有bug,出现了死循环调用,或者是无限制的递归调用,最后连续调用几万次之后,栈内存就溢出了,没法放入更多的方法栈桢了。
用一段代码示范一下栈内存溢出
下面大家先看一段代码:
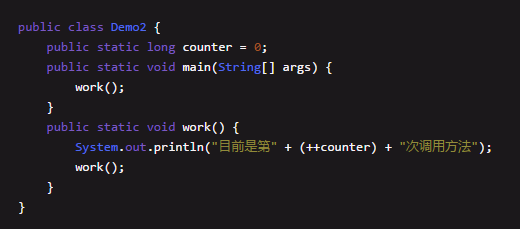
上面的代码非常简单,就是work()方法调用自己,进入一个无限制的递归调用,陷入死循环,也就是说在main线程的栈中,会不停的压入work()方法调用的栈桢,直到1MB的内存空间耗尽。
另外大家需要设置这个程序的JVM参数如下:-XX:ThreadStackSize=1m(等同于-Xss1M),通过这个参数设置JVM的栈内存为1MB。
完整jvm参数如下:
|
接着大家运行这段代码,会看到如下所示的打印输出:
|
也就是说,当main线程调用了5675次work方法之后(也就意味着在main线程创建的Java虚拟机栈中一共创建了5675个栈帧),他的栈里压入了5675个栈桢,最终把1MB的栈内存给塞满了,引发了栈内存的溢出。大家看到StackOverflowError,就知道是线程栈内存溢出了。
本文总结
本文带着大家用代码实验了一下栈内存的溢出,大家可以看到1MB的栈内存可以让你连续调用5000次以上的方法,其实这个数量已经很多了,除了递归方法以外,一般根本不可能出现方法连续调用几千次的。
所以大家就知道,一般这种栈内存溢出是极少在生产环境出现的,即使有,一般都是代码中的bug导致的.
对象太多了!堆内存实在是放不下,只能内存溢出!
原理解析
1、前文回顾
之前的文章已经分析了Metaspace和栈内存两块内存区域发生内存溢出的原理,同时给出了一些较为常见的引发他们内存溢出的场景,一般只要代码上注意一些,不太容易引发那两块区域的内存溢出。
其实真正最容易引发内存溢出的就是堆内存,说白了就是平时我们系统创建出来的对象实在是太多了,最终就导致了系统的内存溢出!
2、从对象在Eden区分配开始讲起
如果要把这大量的对象是如何导致堆内存溢出的给讲清楚,那就得从系统运行,在Eden区创建对象开始讲起了。
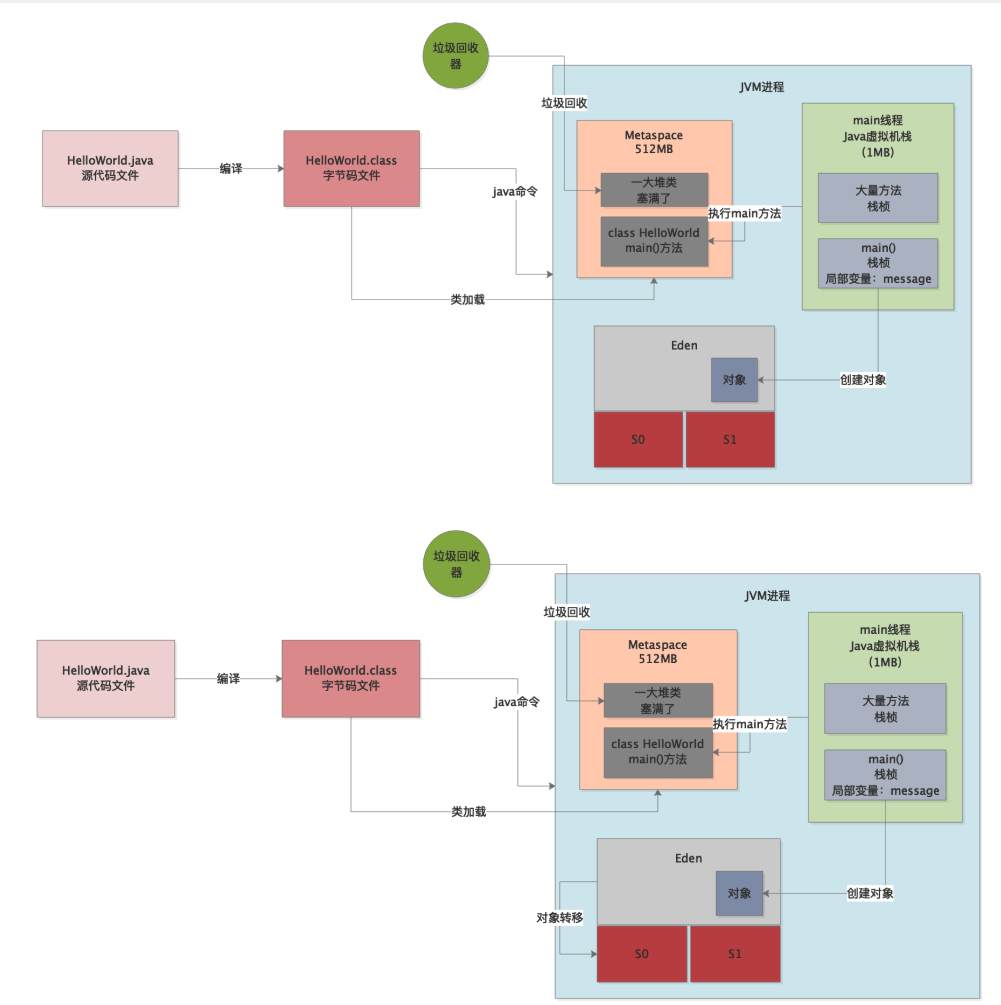
咱们都知道,平时系统运行的时候一直不停的创建对象,然后大量的对象会填满Eden区
一旦Eden区满之后,就会触发一次Young GC,然后存活对象进入S区。
如下图所示
3、高并发场景下导致ygc后存活对象太多
当然因为各种各样的情况,一旦出现了高并发场景,导致ygc后很多请求还没处理完毕,存活对象太多,可能就在Survivor区域放不下了,此时就只能进入到老年代里去了,老年代很快就会放满了。
一旦老年代放满了就会触发Full GC,如下图所示。
`我们假设ygc过后有一批存活对象,Survivor放不了,此时就等着要进入老年代里,然后老年代也满了,那么就得等着老年代进行CMS GC,必须回收掉一批对象,才能让年轻代里存活下来的一批对象进去。
但是呢,不幸的事情发生了,老年代GC过后,依然存活下来了很多的对象!如下图所示。
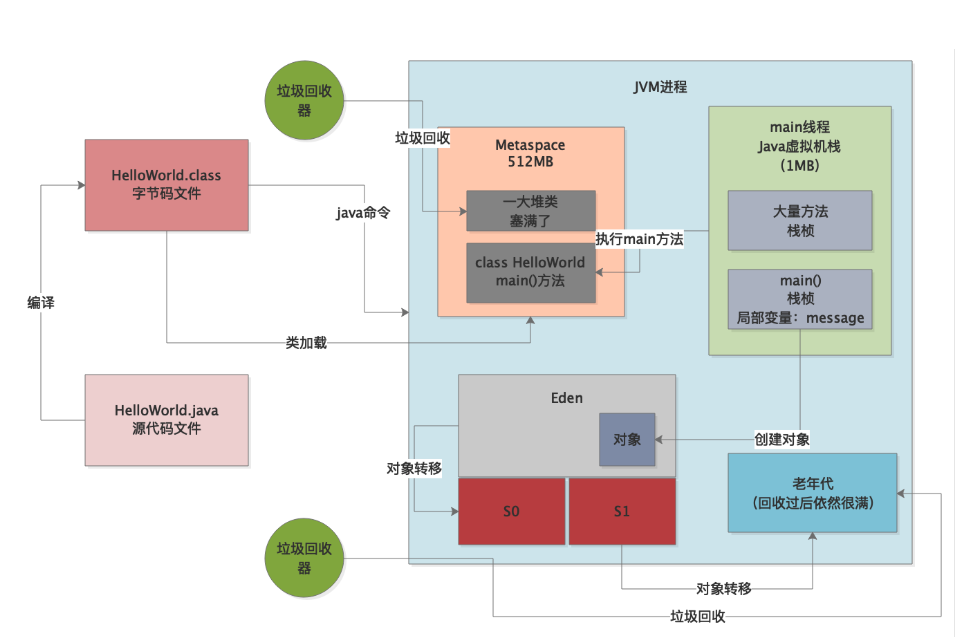
这个时候如果年轻代还有一批对象等着放进老年代,人家GC过后空间还是不足怎么办?
还能怎么办!只能是内存溢出了!如下图所示!
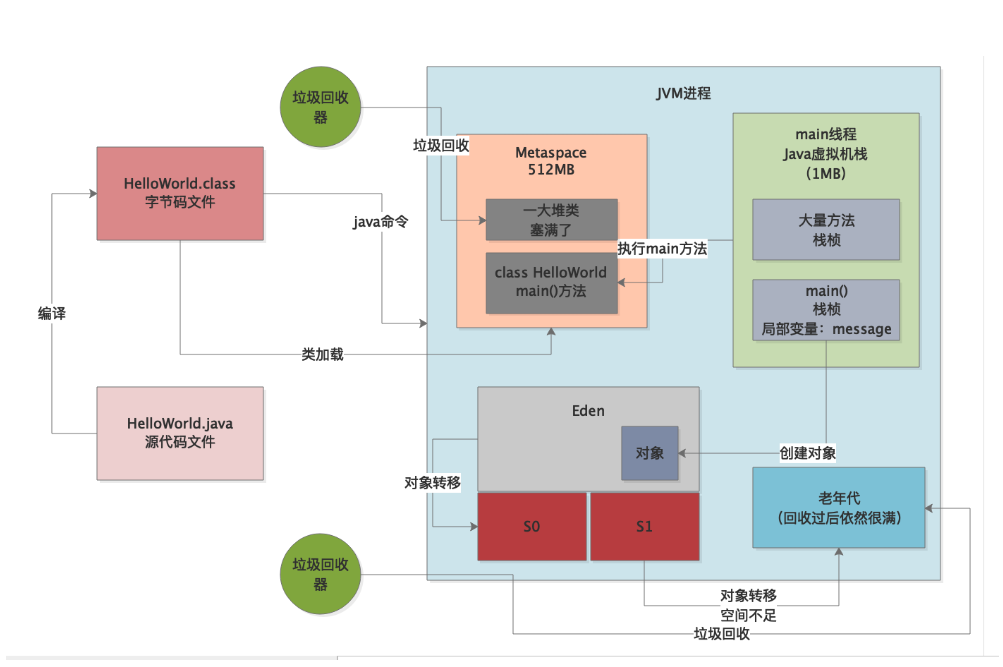
所以这个时候,老年代都已经塞满了,你还要往里面放东西,而且触发了Full GC回收了老年代还是没有足够内存空间,你坚持要放?那只能给你一个内存溢出的异常了!JVM跑不动了,崩溃掉。
这个就是典型的堆内存实在放不下过多对象的内存溢出的一个典型范例。
4、什么时候会发生堆内存的溢出?
发生堆内存溢出的原因其实总结下来,就一句话:
有限的内存中放了过多的对象,而且大多数都是存活的,此时即使GC过后还是大部分都存活,所以要继续放入更多对象已经不可能了,此时只能引发内存溢出问题。
所以一般来说发生内存溢出有两种主要的场景:
- 系统承载高并发请求,因为请求量过大,导致大量对象都是存活的,所以老年代要继续放入新的对象实在是不行了,此时就会引发OOM系统崩溃。这种时候,一般是增加机器内存或者增加机器进行负载均衡。
- 系统有内存泄漏的问题,就是莫名其妙弄了很多的对象,结果对象都是存活的,没有及时取消对他们的引用,导致触发GC还是无法回收,此时只能引发内存溢出,因为内存实在放不下更多对象了
因此总结起来,一般引发OOM,要不然是系统负载过高,要不然就是有内存泄漏的问题。
案例解析
1、前文回顾
不过说实话,Metaspace区域和栈内存的溢出,一般都是极个别情况下才会发生的,并不是一种普遍的现象。
但是堆内存溢出的场景,就是非常普遍的现象了,一旦要是系统负载过高,比如并发量过大,或者是数据量过大,或者是出现了内存泄漏的情况,很容易就导致JVM内存不够用了,就会堆内存溢出,然后系统崩溃。
2、回顾一下堆内存溢出的一个典型场景
首先还是来一张完整的JVM运行原理图,里面包含了对象的分配,GC的触发,对象的转移,各个环节如何触发内存溢出的,大家一定要牢记这张图。
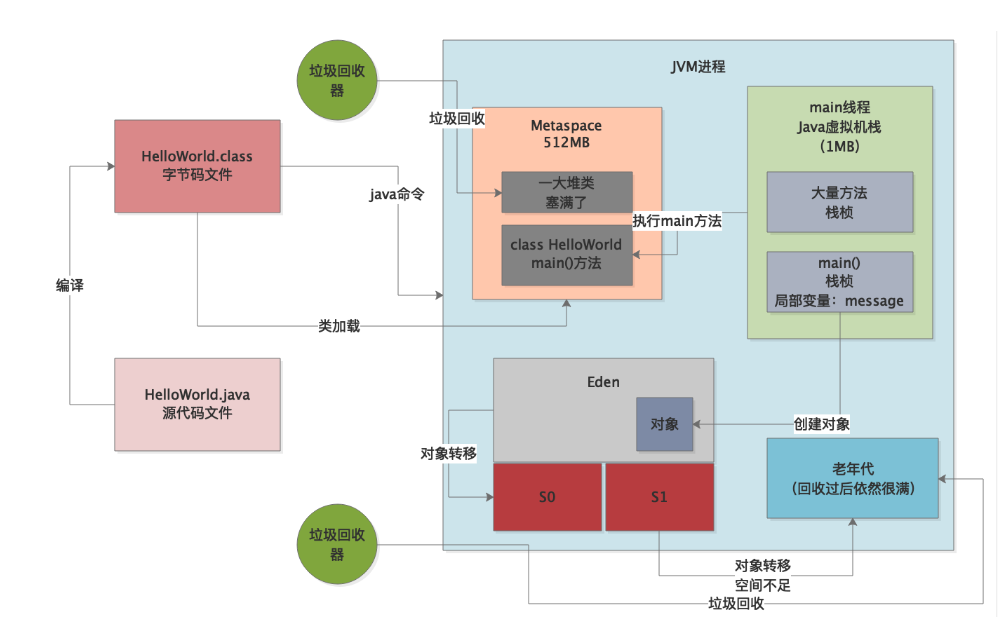
接着我们就来回顾一下一个典型的堆内存溢出的场景:
假设现在系统负载很高,不停的运转和工作,不停的创建对象塞入内存里,刚开始是塞入哪里的?
当然是年轻代的Eden区了。
但是因为系统负载实在太高了,很快就把Eden区塞满了,这个时候触发ygc。
但是ygc的时候发现不对劲,因为似乎Eden区里还有很多的对象都是存活的,而且survivor区域根本放不下,这个时候只能把存活下来的大批对象放入老年代中去。
就这么来几次ygc之后,每次ygc后都有大批对象进入老年代,老年代很快就会塞满了,而且最重要的是这里的对象还大多都是存活的。
所以接下来一次ygc后又要转移一大批对象进入老年代,先触发full gc,但是full gc之后老年代里还是塞满了对象,如下图红圈所示。
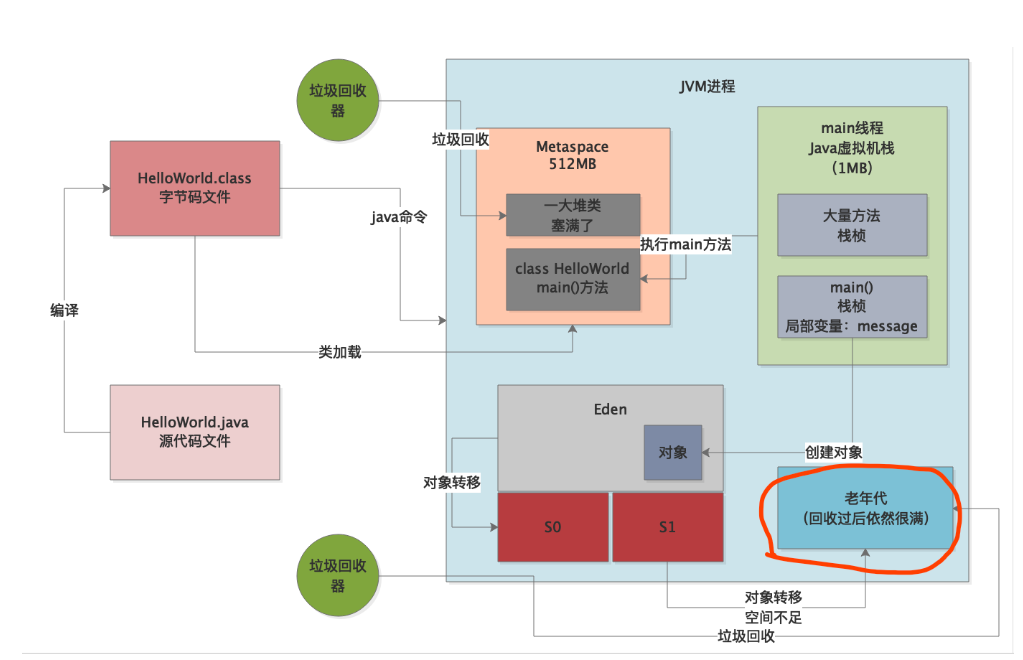
这个时候ygc后存活下来的对象哪怕在full gc之后还是无法放入老年代中,此时就直接报出堆内存溢出了。
所以堆内存溢出的场景就是这样子,非常的简单。
3、用示例代码来演示堆内存溢出的场景
我们来看下面这段代码:
|
代码很简单,就是在一个while循环里不停的创建对象,而且对象全部都是放在List里面被引用的,也就是不能被回收。
大家试想一下,如果你不停的创建对象,Eden区满了,他们全部存活会全部转移到老年代,反复几次之后老年代满了。
然后Eden区再次满了,ygc后存活对象再次进入老年代,此时老年代先full gc,但是回收不了任何对象,因此ygc后的存活对象就一定是无法进入老年代的。
所以我们用下面的JVM参数来运行一下代码:-Xms10m -Xmx10m,我们限制了堆内存大小总共就只有10m,这样可以尽快触发堆内存的溢出。
采用的JVM参数如下:
|
我们在控制台打印的信息中可以看到如下的信息:
当前创建了第360145个对象
Exception in thread “main” java.lang.OutOfMemoryError: Java heap space
所以从这里就可以看到,在10M的堆内存中,用最简单的Object对象搞到老年代被塞满大概需要36万个对象。然后堆内存实在放不下任何其他对象,此时就会OutOfMemory了,而且告诉了你是Java heap space,也就是堆空间发生了内存溢出的。
4.用MAT分析内存快照
采用MAT打开内存快照之后会看到下图:
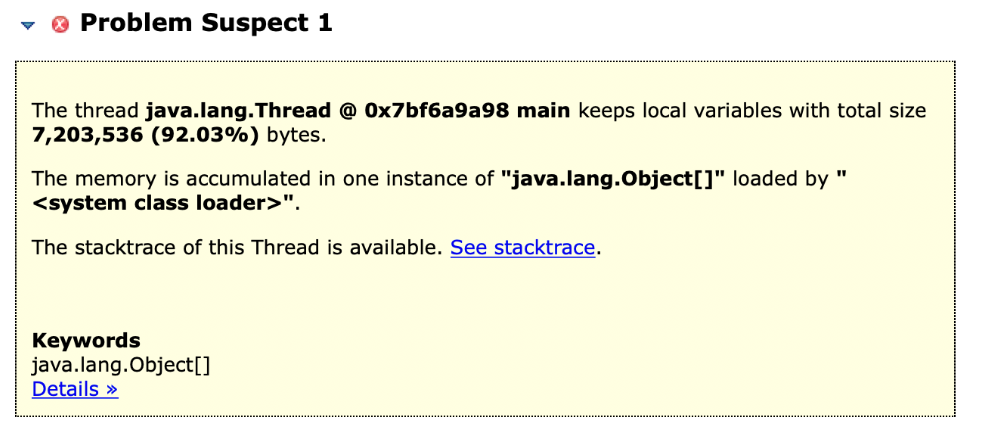
这次MAT非常简单,直接在内存泄漏报告中告诉我们,内存溢出原因只有一个!那就是这个问题,因为他没提示任何其他的问题。
我们这次来给大家仔细分析一下MAT给我们的分析报告。
首先看下面的句子:The thread java.lang.Thread @ 0x7bf6a9a98 main keeps local variables with total size 7,203,536 (92.03%) bytes。
这个意思就是main线程通过局部变量引用了7230536个字节的对象,大概就是7MB左右。
考虑到我们总共就给堆内存10MB,所以7MB基本上个已经到极限了,是差不多的。
我们接着看:The memory is accumulated in one instance of “java.lang.Object[]” loaded by “
这句话的意思就是内存都被一个实例对象占用了,就是java.lang.Object[]。
我们肯定不知道这个是什么东西,所以得往下看,点击Details
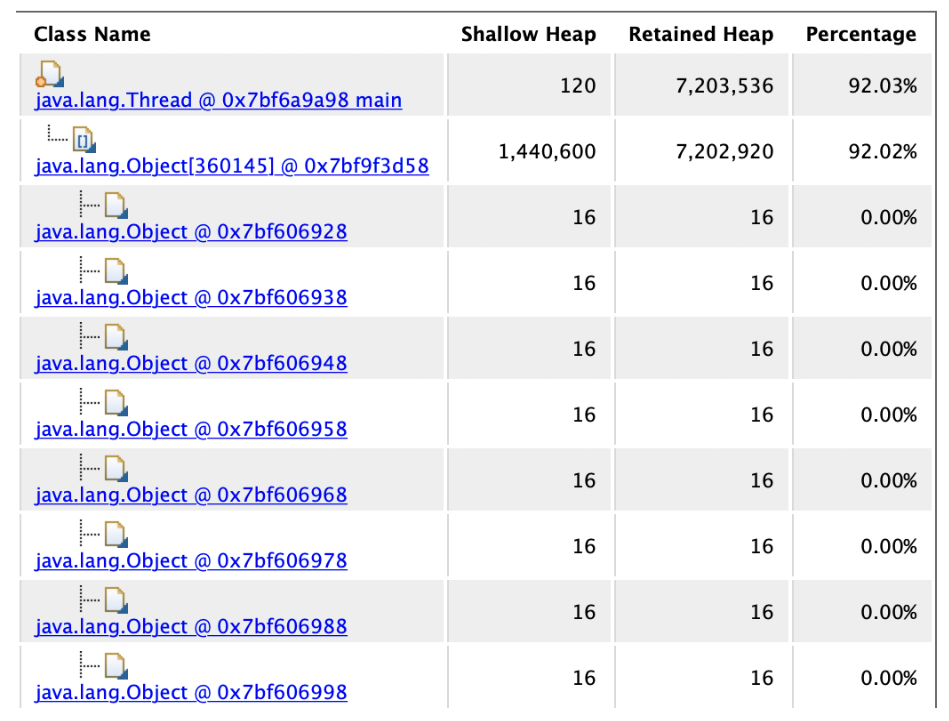
在Details里我们能看到这个东西,也就是占用了7MB内存的的java.lang.Object[],他里面的每个元素在这里都有,我们看到是一大堆的java.lang.Object。那么这些java.lang.Object不就是我们在代码里创建的吗?
至此真相大白,我们已经知道,就是一大堆的Object对象占用了7MB的内存导致了内存溢出。
接着下一个任务就是知道这些对象是怎么创建出来的,那么我们怎么找呢?回到之前的上一级页面,各位看下图。
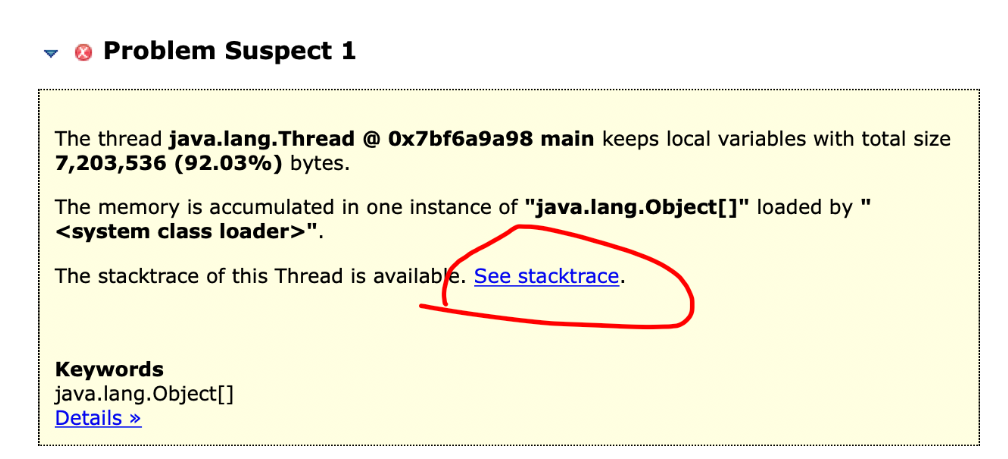
这个是说可以看看创建那么多对象的线程,他的一个执行栈,这样我们就知道这个线程执行什么方法的时候创建了一大堆的对象。
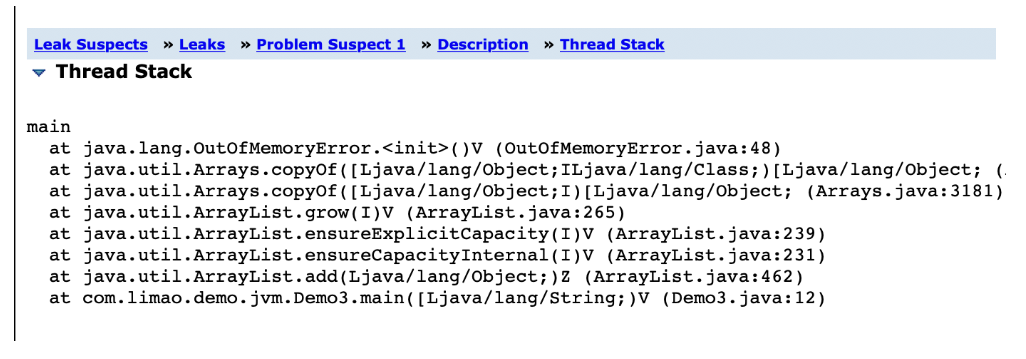
大家看上面的调用栈,其实说的很明显了,在Demo3.main()方法中,一直在调用ArrayList.add()方法,然后此时直接引发了内存溢出。所以我们只要在对应代码里看一下,立马就知道怎么回事了。
接下来优化对应的代码即可,就不会发生内存溢出了。
5、本文总结
今天的文章带着大家分析了一下,堆内存溢出的问题如何分析和定位
其实很简单,一个是必须在JVM参数中加入自动导出内存快照,一个是到线上看一下日志文件里的报错,如果是堆溢出,立马用MAT分析内存快照。
MAT分析的时候一些顺序和技巧,还有思路,也教给大家了,先看占用内存最多的对象是谁,然后分析那个线程的调用栈,接着就可以看到是哪个方法引发的内存溢出了。接着优化代码即可。

