基础概念
为什么使用消息队列?
MQ出现的原因/优点
在回答这个问题之前,我们想一下,在没有消息队列之前我们的多个业务相互调用时他的逻辑实现是怎么样的?
画个图:
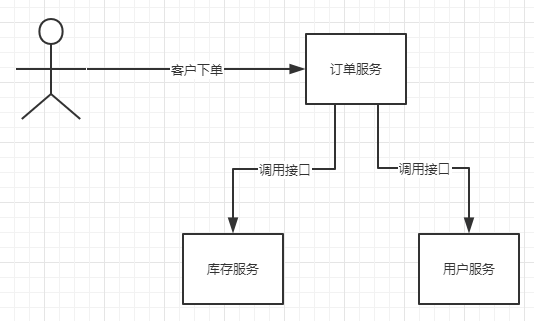
这是一个很普通的业务调用,也是我们写的比较多的。整个业务逻辑是这样的,客户下订单,调用订单服务生成订单,那么在生成订单的时候,会去调用库存服务减少库存,再去调用用户服务查询用户信息。
这样咋一看没有什么问题,但是如果后面订单服务业务改进,需要在下订单的同时,需要查询优惠券服务,查询下订单时所使用的优惠券信息。那么这个时候,你必然要修改订单服务,然后增加调用的代码逻辑。
如下图:
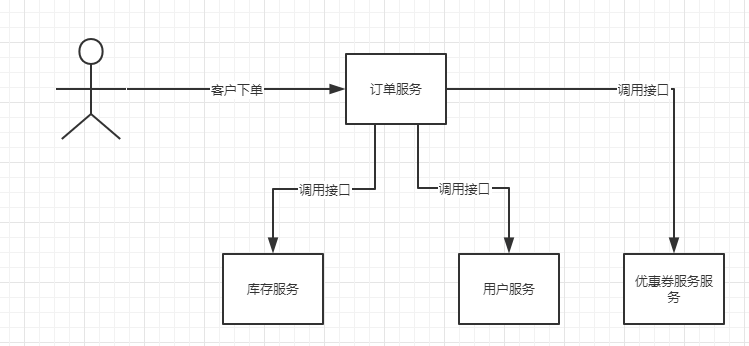
而且后面如果订单服务还需要去调用其他服务,那么你就还需要疯狂的修改订单服务。
而且,例如后面业务改进,订单服务不需要再调用优惠券服务了?那么你又得在订单服务中移除该服务。
非但如此,订单服务要时时刻刻考虑调用的库存服务、用户服务等等系统如果挂了咋办?我要不要重发?我要不要把消息存起来????
总而言之,订单服务所需要承载的责任太重了,而且需要负责的东西太多,这就是耦合。
那么MQ的第一个作用就体现出来了:解耦
上面的服务使用MQ后:
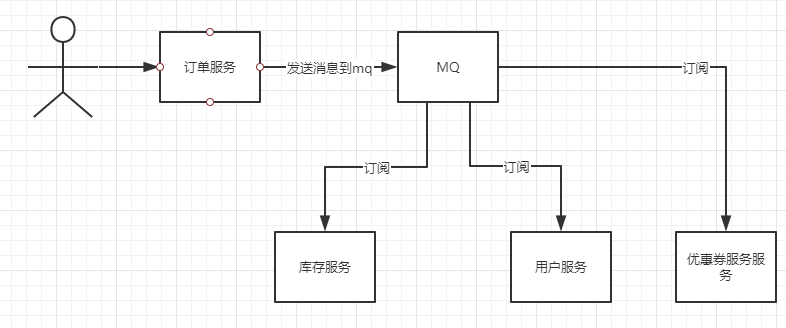
那么经过改进后,整个订单服务就舒服多了,也清净了。订单服务处理完用户下单请求后,只需要发送一条消息到MQ中,代表我下单了,然后整个订单服务就结束了,不需要同步等待库存服务等等其他服务的响应。
库存服务,只需要订阅MQ的主题,然后完成自己的业务逻辑即可。
那么MQ还有其他什么优点呢?
其实在上面我已经说出来了,你有没有发现,在上面的例图中,我们引入了MQ,使得订单服务不再需要同步等待调用其他服务的返回结果。
所以MQ的第二个优点就是:异步
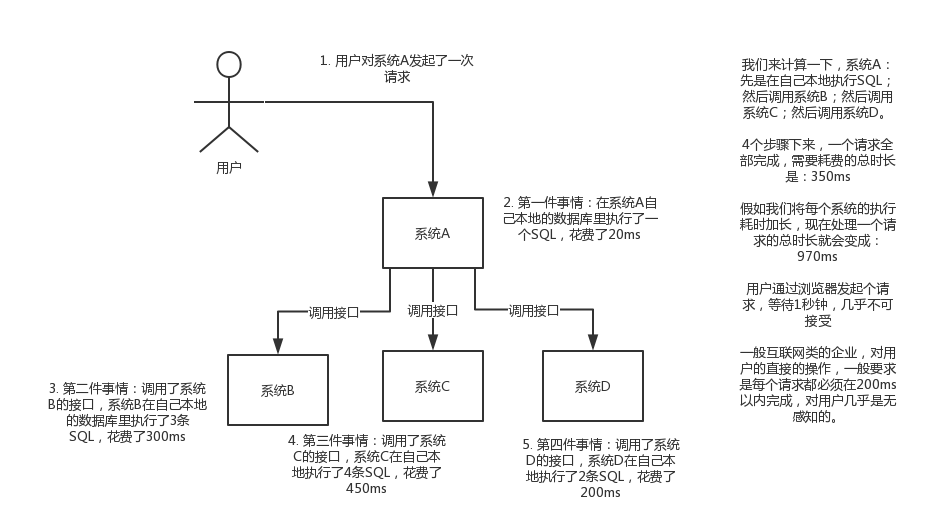
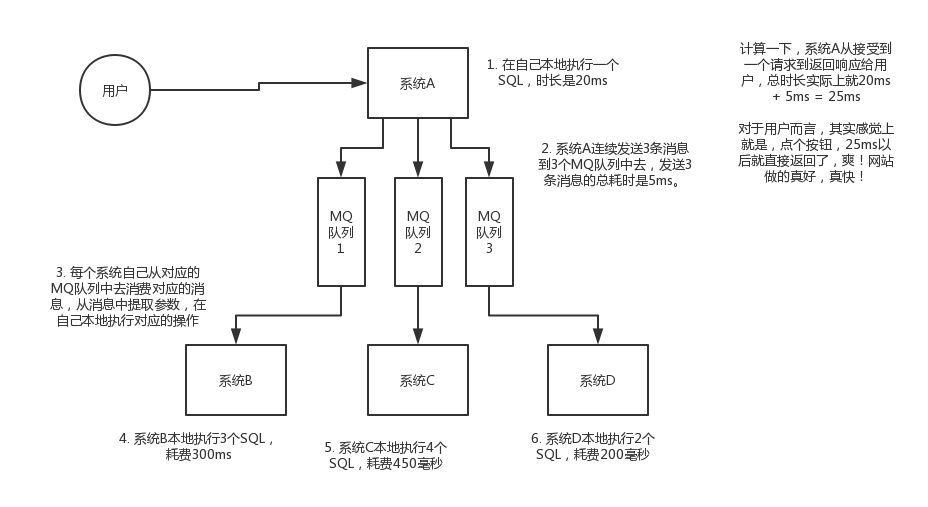
画个图来说明一下,A系统接收一个请求,需要在自己本地写库,还需要在BCD三个系统写库,自己本地写库要3ms,BCD三个系统分别写库要300ms、450ms、200ms。最终请求总延时是3 + 300 + 450 + 200 = 953ms,接近1s,用户感觉搞个什么东西,慢死了慢死了。
未使用MQ前
使用MQ后
MQ的第三个优点:削峰
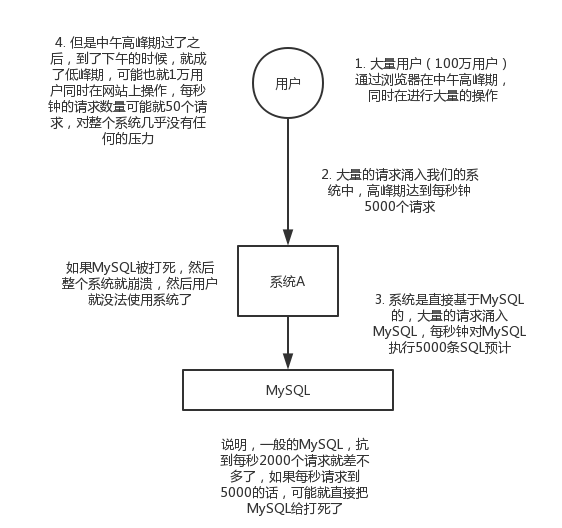
每天0点到11点,A系统风平浪静,每秒并发请求数量就100个(qps=100)。结果每次一到11点~1点,每秒并发请求数量突然会暴增到1万条。但是系统最大的处理能力就只能是每秒钟处理1000个请求啊。。。尴尬了,系统会死。。。
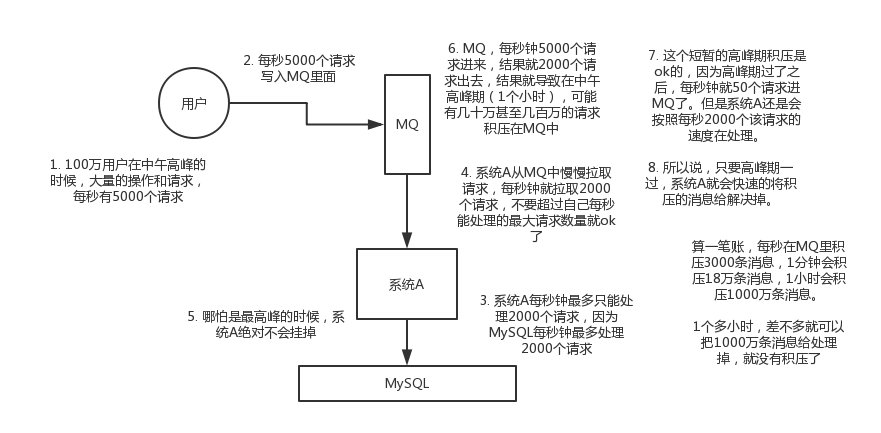
**所以MQ充当的角色类似于一个水库。汛期来临时水库首当其冲,起到缓冲作用,避免大量水流冲击下游。这个时候水库只需要开放部分出口,然后水流慢慢的留向下游,最后把水库里的水慢慢消耗最终接近平缓即可。**
未用MQ前?
使用mq后
总而言之: 队列的常见使用场景吧,其实场景有很多,但是比较核心的优点有3个:解耦、异步、削峰
MQ缺点
缺点呢?显而易见的
- 系统可用性降低:系统引入的外部依赖越多,越容易挂掉,本来你就是A系统调用BCD三个系统的接口就好了,人ABCD四个系统好好的,没啥问题,你偏加个MQ进来,万一MQ挂了咋整?MQ挂了,整套系统崩溃了,你不就完了么。(需要保证MQ高可用 - 增加系统复杂程度)
- 系统复杂性提高:硬生生加个MQ进来,你怎么保证消息没有重复消费?怎么处理消息丢失的情况?怎么保证消息传递的顺序性?头大头大,问题一大堆,痛苦不已,搞什么捏。(消息可靠性和消费幂等性)
- 一致性问题:A系统处理完了直接返回成功了,人都以为你这个请求就成功了;但是问题是,要是BCD三个系统那里,BD两个系统写库成功了,结果C系统写库失败了,咋整?你这数据就不一致了。(分布式事务/数据最终一致性)
所以消息队列实际是一种非常复杂的架构,你引入它有很多好处,但是也得针对它带来的坏处做各种额外的技术方案和架构来规避掉,最好之后,你会发现,妈耶,系统复杂度提升了一个数量级,也许是复杂了10倍。但是关键时刻,用,还是得用的。。。但是得想好。
https://www.showdoc.cc/rmq?page_id=1796661553395018
怎么解决数据的一致性
分布式事务 - 强一致性
数据最终一致性 - 弱一致性
CAP理论
2000年7月,加州大学伯克利分校的Eric Brewer教授在ACM PODC会议上提出CAP猜想。Brewer认为在设计一个大规模的分布式系统时会遇到三个特性:一致性(consistency)、可用性(Availability)、分区容错(partition-tolerance),而一个分布式系统最多只能满足其中的2项。2年后,麻省理工学院的Seth Gilbert和Nancy Lynch从理论上证明了CAP。之后,CAP理论正式成为分布式计算领域的公认定理。
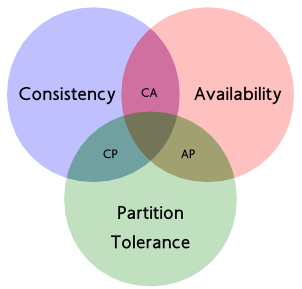
C:数据一致性(强一致性),集群中同一数据的多个副本是否实时相同。(一致性也分为,强一致性和弱一致性)
A:可用性,指系统提供的服务必须一直处于可用的状态,对于用户的每一个操作请求总是能够在有限的时间内返回结果。
P:分区容错性,也就是如果出现网络震荡的时候,服务集群不能够全部挂掉,保证高可用。将同一服务分布在多个系统中,从而保证某一个系统宕机,仍然有其他系统提供相同的服务。
在分布式系统中,P肯定要保证的。
为什么要保证p呢?
当业务量猛增,单个服务器已经无法满足我们的业务需求的时候,就需要使用分布式系统,使用多个节点提供相同的功能(需要部署服务集群),从而整体上提升系统的性能,这就是使用分布式系统的第一个原因。那么分区容错性就必须满足。
那么我们只能在C和A中二选一,为什么A和C不能够同时选择呢?举个简单例子。我们在部署了五个订单服务,组成了集群。有一天需求修改了,那么需要更新这五个订单服务。这个时候,我们为了保证客户还是能够访问系统,那么就升级部分服务器,也就意味着,必然存在客户调用了新旧订单服务。那么这个时候数据肯定是不一致的。反之亦然,为了保证数据一致性,我们关闭五个服务器,然后更新后再重启,那么在这期间服务对外是不可用的,无法保证系统可用性。
例如我们在使用springcloud的Eureka服务注册中心时,他实现的机制就是 AP,能够保证服务的使用。
DUbbo的服务注册中心采用的是Zookeeper,那么因为zookeeper集群(选举机制),他实现的机制是CP(但是他的C数据一致性是,数据弱一致性,也就是存在某个时间salve的数据是不一致的–因为zk 的是更新操作是采取投票过半机制决定本次更新是否成功。)
所以具体的业务场景采用不同的策略,不过大多数互联网项目采用的是AP机制,以能够保证服务的使用为主。 因为在大谈用户体验的今天,如果业务系统时常出现“系统异常”、响应时间过长等情况,这使得用户对系统的好感度大打折扣。所以可用性还是要保证的
BASE理论
CAP理论告诉我们一个悲惨但不得不接受的事实——我们只能在C、A、P中选择两个条件。而对于业务系统而言,我们往往选择牺牲一致性来换取系统的可用性和分区容错性。不过这里要指出的是,所谓的“牺牲一致性”并不是完全放弃数据一致性,而是牺牲强一致性换取弱一致性
BASE理论是对CAP理论的延伸,核心思想是即使无法做到强一致性(Strong Consistency,CAP的一致性就是强一致性),但应用可以采用适合的方式达到最终一致性(Eventual Consitency)。
BASE是Basically Available(基本可用)、Soft state(软状态)和Eventually consistent(最终一致性)三个短语的缩写。
- BA:基本可用(Basically Available)
指分布式系统在出现不可预知故障的时候,允许损失部分可用性。
- S:软状态( Soft State)
指允许系统中的数据存在中间状态,并认为该中间状态的存在不会影响系统的整体可用性。
- E:最终一致( Eventual Consistency)
强调的是所有的数据更新操作,在经过一段时间的同步之后,最终都能够达到一个一致的状态。因此,最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性。
base理论的核心就是,经过一段时间后,能够保证数据的强一致性,在这之前,数据的一致性不是那么的强调。
举个简单的例子,例如在双十一购物中心,某件商品的点赞数量我们需不需要它实时的显示数量?很明显是不需要的,我们显示的数量可以使几个小时之前的。我们只需要在双十一过后,再去统计出最终该商品的点赞数量,然后显示即可。
其实大部分最终一致性是通过消息队列的方式实现的。例如我们对商品的点赞,发送一条消息到消息队列,然后消息消费者消费消息,实现点赞数量增加。这样的流程肯定会存在一定的延时,但是最终结果肯定是正确的,所以实现了最终一致性。
rocketmq事务消息
设么是事务消息?先看案例场景
例如下图的场景:生成订单记录 -> MQ -> 增加积分
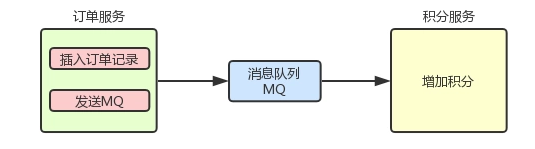
我们是应该先 创建订单记录,还是先 发送MQ消息 呢?
- 先发送MQ消息:这个明显是不行的,因为如果消息发送成功,而订单创建失败的话是没办法把消息收回来的。因为发送消息后,下游消费者,已经消费提交。
- 先创建订单记录:如果订单创建成功后MQ消息发送失败 抛出异常,因为两个操作都在本地事务中所以订单数据是可以 回滚 的。
上面的 方式二 看似没问题,但是 网络是不可靠的!如果 MQ 的响应因为网络原因没有收到,所以在面对不确定的结果只好进行回滚;但是 MQ 端又确实是收到了这条消息的,只是回给客户端的 响应丢失 了!
所以 事务消息 就是用来保证 本地事务 与 MQ消息发送 的原子性!
原理
图一
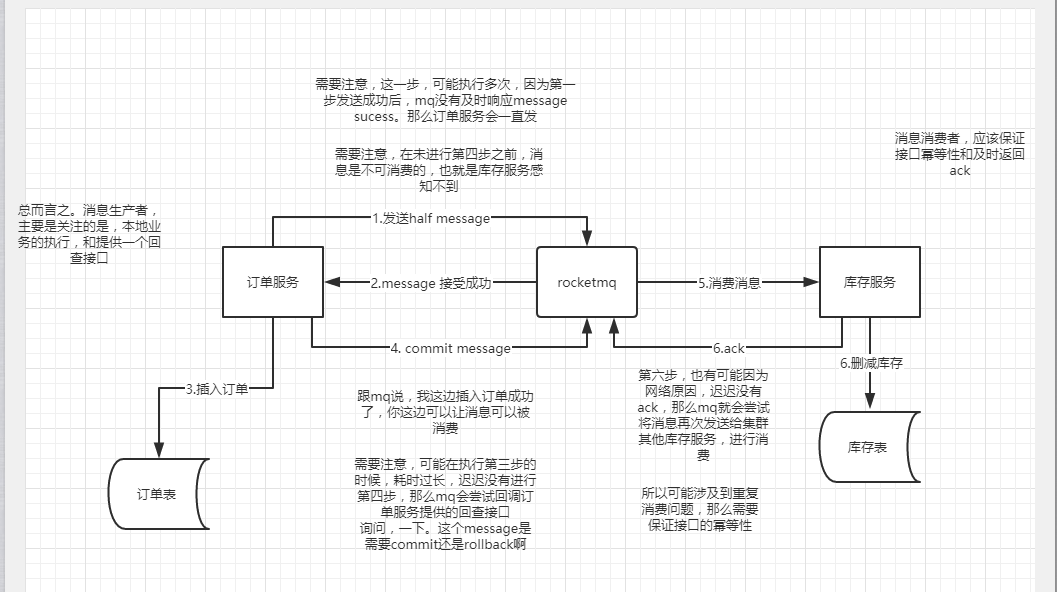
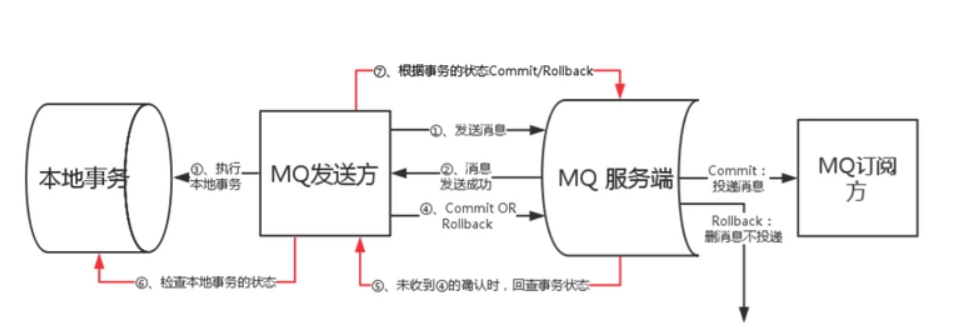
主要的逻辑分为两个流程:
- 事务消息发送及提交:
- 发送
half消息 MQ服务端响应消息写入结果- 根据发送结果执行
本地事务(如果写入失败,此时half消息对业务 不可见,本地逻辑不执行) - 根据本地事务状态执行
Commit或者Rollback(Commit操作生成消息索引,消息对消费者 可见)
- 发送
- 回查流程:
- 对于长时间没有
Commit/Rollback的事务消息(pending状态的消息),mq服务端发起一次 回查 Producer收到回查消息,检查回查消息对应的本地事务状态- 根据本地事务状态,重新
Commit或者Rollback
- 对于长时间没有
逻辑时序图
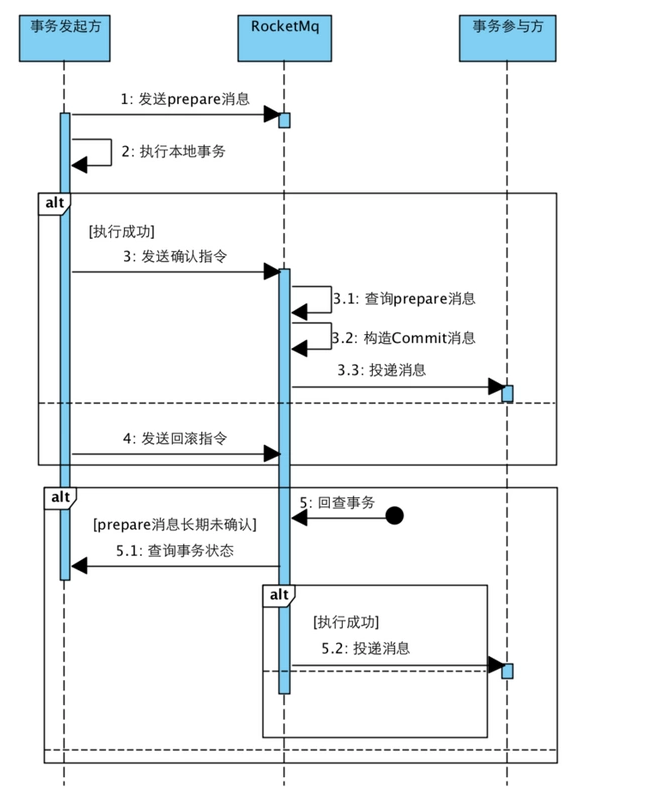
rocketmq事务消息的弊端
根据图1,你会发现,存在一个问题,那就是假设库存服务成功消费到了消息,但是删减库存失败。那么因为删除失败也是属于业务的一部分,那么他就会返回ack消息给,mq。那么整个流程结束。
从上面的原理可以发现 事务消息 仅仅只是保证本地事务和MQ消息发送形成整体的 原子性,而投递到MQ服务器后,并无法保证消费者一定能消费成功!
如果 消费端消费失败 后的处理方式,建议是记录异常信息然后 人工处理,并不建议回滚上游服务的数据(因为两者是 解耦 的,而且 复杂度 太高)
我们可以利用 MQ 的两个特性 重试 和 死信队列 来协助消费端处理:
- 消费失败后进行一定次数的
重试 - 重试后也失败的话该消息丢进
死信队列里 - 另外起一个线程监听消费
死信队列里的消息,记录日志并且预警!
因为有 重试 所以消费者需要实现 幂等性
总而言之,rocketmq实现事务消息的两个核心概念:两阶段提交、事务状态定时回查
我要做什么?项目介绍
因为我们知道rocketmq是原生支持事务消息的,但是如果项目中,最初选型的时候,并没有选用rmq,而是选用了其他的MQ,例如rabbitmq,activemq,kafka等等,但是又想保证最终一致性事务呢?
那么我们仿照上面rmq的事务消息的原理,来自己实现一个提供事务消息的项目工程。
那么这个项目我决定命名为RTM(滑稽脸)。
RTM( Reliable transaction message )是基于可靠消息的最终一致性的分布式事务解决方案。
框架定位
RTM本身不生产消息队列,只是消息的搬运工。
RTM框架提供消息预发送、消息发送、消息确认、消息恢复、消息管理等功能,结合成熟的消息中间件,解决分布式事务,达到数据最终一致性。
RTM解决的问题
引入消息中间件的场景
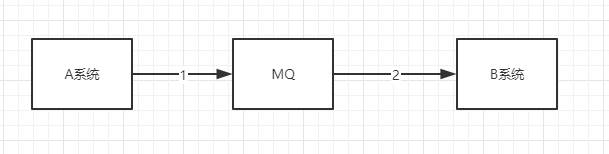
存在问题,1处和2处,可能因为网络原因,导致数据一致性的问题产生,也就是无法保证A系统和B系统数据的一致性,无法保证。
举个例子,A系统发送完消息到MQ后,在执行自己业务过程中出现异常,本地事务回滚。但是此时消息已经发到MQ,下游服务B系统已经消费消息,B系统执行完自己的业务。那么此时A系统失败,B系统成功。这样就造成了整个业务流不是原子的,存在数据不一致性。
上面的场景还存在着很多数据不一致性的场景。这里就不一一列举,下面在讲解到RTM的细节时会一一说明。
引入RTM后的场景
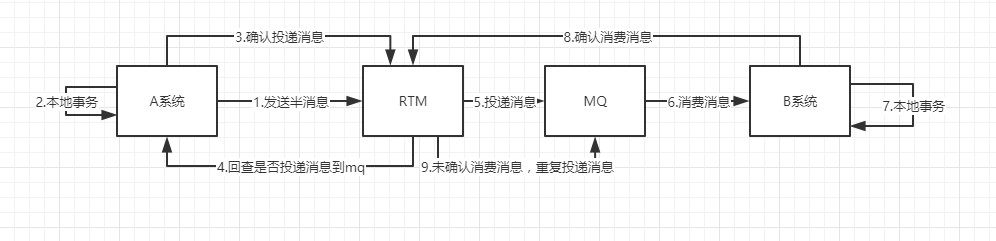
可以看到我们在RTM中引进了,rocketmq的事务消息的概念,RTM在这里仅仅只是作为一个协调者,协调上下游服务的业务操作。确保了是上下游服务能够保证数据的一致性,达到数据最终一致性,符合BASE理论。
RTM提供了,发送半消息、半消息确认、消息发送到MQ、消息消费确认、消息重复投递等等功能。
RTM详细流程介绍
通过上面的阐述,我们大概知道了RTM在分布式系统中的地位,协调者。但是至于他的请求流程,怎么保证数据一致性,下面我们拉一一说明。
我们将从三个方面来说明
- 正常使用流程
- 消息发送到RTM,RTM成功投递流程
- RTM确认消费者成功消费流程
正常流程
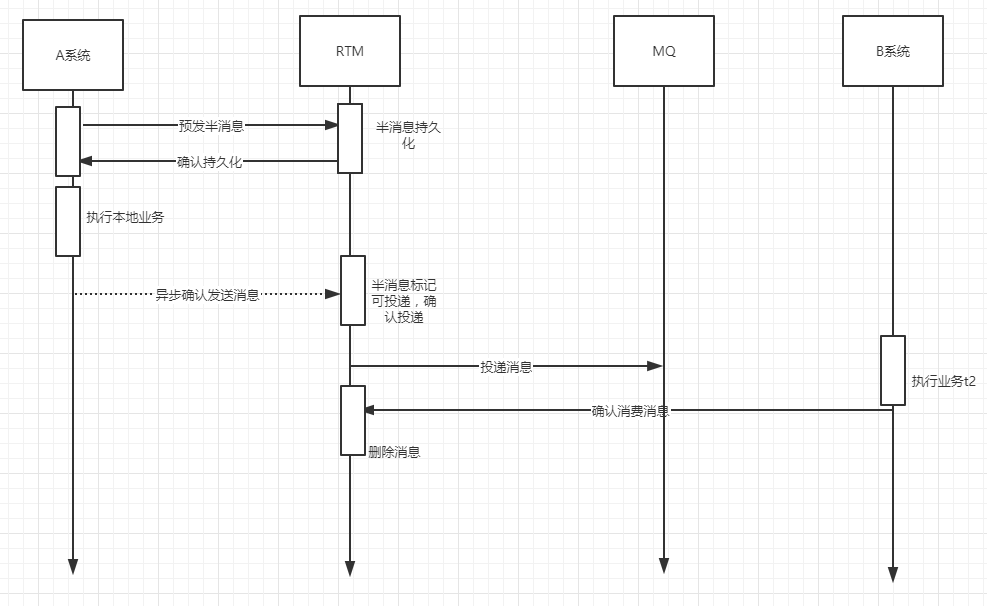
梳理一下流程:
(1)首先A系统在执行业务之前,先投递半消息到RTM,RTM持久化成功后(这里使用mysql),发送成功消息给A系统,紧接着A系统执行本地业务。(一般这段逻辑需要开启本地事务,这样可以保证了消息发送成功后再执行本地业务,消息发送失败那么也就没有必要执行A系统本地业务了)
(2)接着A系统在执行完本地业务后,异步发送确认消息给RTM,然后RTM标记半消息为确认可投递,接着RTM会把消息发送给MQ。
(3)系统B收到MQ的消息,然后执行自己的业务逻辑,之后再调用RTM接口,确认消息已经消费,接着RTM会把该消息从数据库中删除。到这里整个流程结束
解释几个问题。
在步骤二中,为什么需要异步通知RTM消息可投递。
我们反过来想,如果用同步会发生什么?首先来看一下A系统调用RTM系统的伪代码
- (rollbackFor = RuntimeException.class)//开启事务public void addOrder(Order order) {// 1.调用RMQ,创建预发送消息String msgID = rtmService.addHalfMessage(order);// 2.执行业务。。。。。// 3.同步调用RTM,确认发送消息rtmService.confirmHalfMessage(msgID);}
假设在第三处,调用RTM时,因为网络延迟或者其他原因,导致confirmHalfMessage()抛出异常,那么addOrder()方法回滚,A系统执行失败。但是实际上RTM还是调用成功了,也就是意味着RTM会往MQ发送消息,然后B系统收到消息后成功执行。那么此时A、B系统的数据是不一致性。
所以这里需要异步调用RTM,确认消息。目的就是解耦,保证了A系统的正常执行。
但是如果使用异步后?出现A系统成功执行,但是调用RTM确认消息发送失败时,怎么处理呢?这个问题RTM会提供回查机制,确认半消息是删除还是确认投递。
总结
可以看到整个RTM正常流程下是能够保证数据的一致性的,满足base理论。
消息发送到RTM,RTM成功投递流程
上面我们只是把整个RTM使用的正常流程梳理了一遍,但是在使用过程中肯定会出现很多问题,出现问题的同时可能还会造成数据的不一致性问题,那么怎么保证数据的一致性呢?出现问题怎么解决呢?
接下来我们来看一下,A系统在跟RTM通信这个阶段出现问题怎么解决?怎么保证数据一致性?
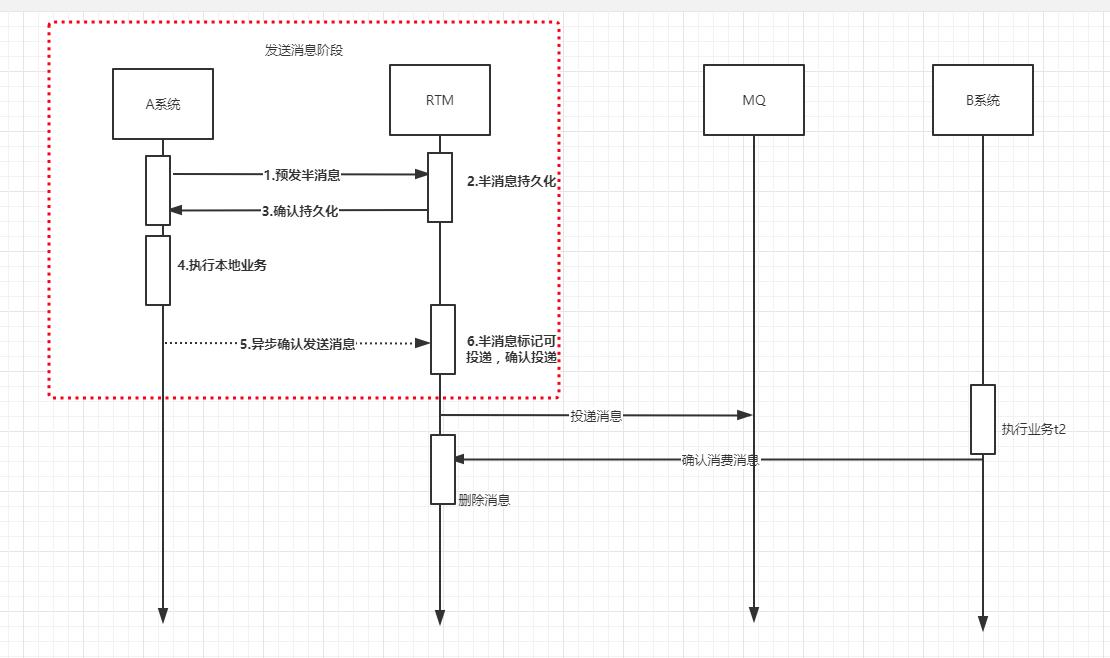
接下来我们就来分析一下如果上面这六步如果出现了问题,那么RTM是怎么解决的,只要保证了这六步的正确性,那么我们也就保证了消息发送阶段的一致性。
1处发送异常,A系统发送半消息失败。那么因为A系统还没执行本业务(没有执行到4处),而且RTM系统也没有持久化半消息。那么此时不会产生数据不一致,那么RTM系统不需要做处理。
- (rollbackFor = RuntimeException.class)//开启事务public void addOrder(Order order) {//A系统调用RTM,伪代码// 1.调用RMQ,创建预发送消息String msgID = rtmService.addHalfMessage(order);//上面1处,实际上就是对应这里的代码段,假设这里发生异常,因为addOrder()方法添加了事务,所以addORder()执行失败。数据一致性没有问题。// 2.执行业务。。。。。// 3.同步调用RTM,确认发送消息rtmService.confirmHalfMessage(msgID);}
- 2发生异常,RTM持久化半消息失败。同理,因为A系统还没执行本业务(没有执行到4处),而且RTM系统也没有持久化半消息。那么此时不会产生数据不一致,那么RTM系统不需要做处理。
3.处发生异常,RTM持久化消息成功。但是A系统还没执行本业务(没有执行到4处),这个时候数据不一致。那么RTM提供回查机制,RTM的会有定时器定时检查RTM系统中没有确认的消息,向A系统发起请求,请求检查A系统业务状态,如果执行业务失败,那么RTM删除持久化的半消息,否则A系统执行业务成功,那么RTM确认投递消息到MQ。
什么情况下执行2处代码成功,但是上游却报异常呢?例如A系统设定调用 rtmService.addHalfMessage(order)的超时时间是5s,(也就是说在5s内addHalfMessage方法要给我响应,否则我就抛异常),但是addHalfMessage()方法执行需要7s,那么很明显A系统执行addHalfMessage()方法就会超时,然后A系统请求超时抛异常,A系统业务执行失败。但是A系统报异常并不影响RTM继续执行addHalfMessage()的逻辑,此时过了7s,addHalfMessage()执行成功。RTM成功持久化半消息。
所以我们A系统需要提供回查的接口给RTM系统调用,让给RTM系统确认半消息是删除还是投递。
- 4处发生异常,也就是A系统执行本地业务失败。此时RTM系统已经持久化半消息,那么数据是不一致的。
- 怎么解决?跟解决上面的问题三一样,也是需要RTM的回查机制,进行回查A系统确定当前持久化的半消息是删除还是投递。
- 5处发生异常,A系统业务执行成功。但是RTM系统的半消息没有确认投递,数据不一致。
- 解决办法,还是需要RTM系统的回查功能,进行回查A系统确定当前持久化的半消息是删除还是投递。
- 6处发生异常,A系统业务执行成功,RTM确认投递消息失败,数据不一致。
- 解决办法,还是需要RTM系统的回查功能,进行回查A系统确定当前持久化的半消息是删除还是投递。
总结
我们发现,除了一二处的异常,未产生数据不一致,不需要RTM系统进行干预外,3456处的异常需要RTM系统的回查机制进行确认RTM系统已经持久化的半消息是删除 还是投递。
这个时候,我们就应该得出,RTM系统需要具备一个定时回查A系统的模块
分析到这里,我们发现。
- 上游系统A需要提供一个查询本地业务执行结果的接口。
- RTM系统提供,创建半消息接口,确认半消息接口,定时回查A系统业务功能
RTM确认消费者成功消费流程
我们上面解决了上游系统跟RTM系统交互的可靠性,那么RTM系统跟下游系统的数据一致性,在呢么解决呢?请看流程图。
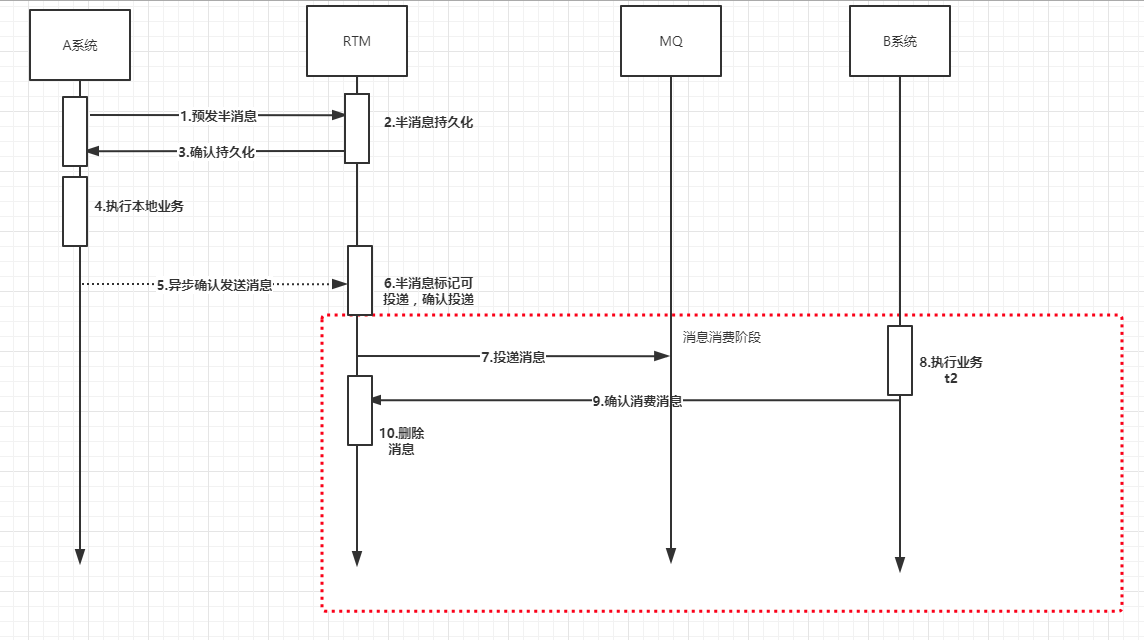
同理我们来分析,下面这几处的如果出现了异常RTM系统是如何处理的?
- 7处发生异常,RTM系统的确认是否消费功能,会定时检查RTM系统中已经确认可以投递的消息(也即是经过操作6之后的消息),如果存在,那么就会重新投递到MQ中。(也就是说,B系统必须保证接口服务的幂等性,因为可能存在重复消费)
- 8处发生异常,同理RTM系统也会通过确认是否消费功能,定时重发RTM系统中未被B系统确认消费的消息。
- 9处发生异常,同理RTM系统也会通过确认是否消费功能,定时重发RTM系统中未被B系统确认消费的消息。
- 10处发生异常,同理RTM系统也会通过确认是否消费功能,定时重发RTM系统中未被B系统确认消费的消息。
总而言之,如果下游B系统如果没有向RTM系统确认消费消息,那么RTM系统就会通过定时器反复向MQ重发消息。(B系统必须保证接口服务的幂等性,因为可能存在重复消费)
超时重试次数和重试时间
但是有个问题,那就是,无限次重发么? 隔几秒发一次呢?
关于这个问题,我们可以仿照Rocketmq的重试逻辑,重试多次次后,那么就标记消息为死亡。(类似于rocketmq的死信队列)
同时重试的时间间隔,也是采取递增的方式。例如重复通知时间间隔(单位:分钟) 举例: [0, 1, 4, 10, 30, 60] 第一次立即通知,如果业务方没有返回成功,则1分钟后再次通知。如果业务方还是没有返回成功,则4分钟后再次通知(此时距离第一次通知已经过了5分钟)。以此类推。那么这里一共可以重试几次呢?7次。 七次后还是没有得到下游B系统的确认消费通知,那么就标记当前消息为死亡。
那么消息死亡后怎么办?
消息重试次数超过限制次数后,消息就会被移动到死亡表中,然后你可以在后台进行人工重试。
总结
经过上面的分析,我们知道,RTM系统需要提供一个接口,给下游服务B系统,确认消费成功。
到这里,我们RTM系统一共需要哪些接口服务,我们再总结一下:
- 上游系统A需要提供一个查询本地业务执行结果的接口。
RTM系统提供,创建半消息接口,确认半消息接口,定时回查A系统业务功能
RTM系统提供,确认消费成功接口,定时重发消息功能,定时
RTM项目总结
经过上面的总结,我想你应该对于RTM系统的定位,已经流程都已经有了一个比较充分的了解。那么我们接下来就总结一下实现RTM项目所需要的功能模块。
项目模块
首先上游系统需要提供什么?
需要提供一个可以查询本地事务结果的接口,方便RTM回查上游系统业务结果,来决定持久化在RTM的半消息是删除还是确认投递。
RTM系统需要提供什么?
(1)message-lifecycle-management模块(消息生命周期管理模块)
- 创建半消息的接口
- 提供上游系统在进行本地业务之前进行调用添加半消息。
- 确认半消息投递接口
- 提供给上游系统在执行成功本地业务后,调用该接口,实现确认半消息为可投递,并投递消息到MQ中。
- 确认消息消费接口
- 提供给下游系统,在成功消费MQ中的消息后,调用确认消息已经消费。
(2)period-check-message模块(定时检查消息模块)
- 定时回查上游系统业务处理结果接口功能
- RTM系统定时调用,确认是否需要投递消息到MQ
- 定时检查RTM持久化的消息是否已经被下游系统消费功能
- RTM系统定时调用,如果没有被消费,那么重复投递到MQ中
- 定时检查RTM持久化的消息是否超过投递次数(也即是重复发送到mq次数达到上限,需要标记消息为死亡)
- RTM系统定时调用,同时把消息移动到死亡表中
- 定时检查RTM持久化的消息是否已经被下游系统消费(如果是那么把已经消费的消息从系统中移除,放到消息历史表中)
- RTM系统定时调用
也就是说,这个模块需要提供四个定时器。
下游系统需要提供什么?
不需要提供什么,但是需要保证消息消费的幂等性。
数据库表(第一版)
第一版,因为时间关系,暂时没有提供前台界面,进行管理消息,后面有时间了,会加上去。
(1)数据库rtm
创建数据库rtm
|
(2)数据库表
消息表
|
确认消费消息表(历史表)也就是保存的是msg_status==2的消息
|
超时死亡消息表 - 保存的是msg_d_status==1的消息
|
项目代码模块结构
RTM项目使用环境
依赖环境
| 环境 | 版本 | 说明 |
|---|---|---|
| JDK | 1.8 | |
| MySQL | 5.7.25 | |
| Zookeeper | 3.4.14 | |
| kafka | 5.15.6 | 因为原先上下游系统使用的是kafka,所以这里接入的就是kafka(如果是其他的mq则接入你自己的mq即可) -可选 |
| Maven | 3.3.9 |
RTM代码实现
父工程 rtm
接口层 rtm-api
保存rtm,对外暴露的接口
依赖 rtm-pojo
实现三个接口:
|
实体类 rtm-pojo
保存rtm项目的实体类
根据mybatis-reverse,逆向生成数据库表对应的实体类和mapper、xml文件。
工具层 rtm-common
消息生命周期管理服务 rtm-mlm
message-lifecycle-management模块(消息生命周期管理模块) - 的简写,mlm
定时检查消息模块 rtm-pcm
period-check-message模块(定时检查消息模块) - 简写,pcm
github地址
https://github.com/JeremyKinge/rtm.git
怎么使用rtm
目前rtm只提供了,dubbo版本,那么也就是在使用时,你需要配置dubbo环境。
上游系统怎么使用?
只需要在业务类中,通过dubbo的方式注入rtm服务即可。
|
例如你的业务逻辑如下:订单支付后,需要给用户增加积分
|
下游系统怎么用?
根据上面的例子,下游会去mq订阅积分消息,那么需要在处理订阅的消息方法中。下游服务在处理完消息后,调用:
|
完成确认消息已经消费即可。
需要注意的是:下游消费服务时,需要注意保证消息幂等性,因为可能因为网络等等原因,可能rtm会重发消息。
RTM项目亮点
0.首先是给没有提供事务消息机制的mq提供了事务消息的方式
1.超时重试机制,类似rocketmq,根据时间递增间隔重试
2.死亡消息,可以在后台进行重发,手动干预
3.消息重试,采取线程池的方式,根据线程池的coresize大小(避免线程递增到maxsize),去数据库中取相应数量需要重复发送搭到mq的消息。
4.重发消息时,从重发次数大到小进行重发(例如,RTM支持的最大重试次数是7。那么就先查重发次数是6的消息,处理完后。再接着查重发次数是5的消息),保证了优先处理快要到重试次数上限的消息,优先处理。
总结
也就是说rtm系统 在兼有rocketmq事务消息的同时,能够保证下游系统一定能消费消息(提供消费失败一定次数和时间间隔重试以及记录超过重试次数的消息),从而保证了数据的最终一致性,同时提供管理界面,管理已经超过重发次数上限的消息,重新发送。
所以说,当你的项目架构在最初的技术选型时,并没有使用rocketmq,那么又想保证数据最终一致性,那么就可以引入rtm系统,非常方便快捷。
RTM项目存在的缺点
1.目前没有支持多种mq的版本(现在只是实现了对接kafka版本)
2.分布式集群的搭建测试
3.项目模块的拆分还不够清晰,例如rtm-pcm模块,可以拆分成两个模块,一个是rtm-pcm-api模块(提供接口,他的实现类在rtm-pcm中),一个是rtm-pcm模块(真正的业务放到这里)
4.rtm-pcm或者rtm-web 模块过于依赖rtm-mlm模块,导致前两者,都需要在application.yaml中配置跟rtm-mlm相同的数据库数据源信息(因为前两者使用了rtm-mlm的mapper调用数据库。)。后面考虑由rtm-mlm提供数据库操作接口,让前两者通过dubbo的方式调用mapper调用数据库。 而不用直接使用rtm-mlm的mapper去调用。
在前两者移除 rtm-mlm依赖,依赖rtm-mlm-api
也就是说在增加一个rtm-mlm-api模块。里面提供操作数据库的接口,rtm-mlm实现接口。

