如果实时性要求的不高的怎么解决?三级缓存架构的技术方案
如果是做实时性要求不高的数据,比如说商品的基本信息,等等,我们采取的是三级缓存架构的技术方案,就是说由一个专门的数据生产的服务,去获取整个商品详情页需要的各种数据,经过处理后,将数据放入各级缓存中,每一级缓存都有自己的作用。
注意事项
1、大型缓存全量更新问题
(1)网络耗费的资源大
(2)每次对redis都存取大数据,对redis的压力也比较大
(3)redis的性能和吞吐量能够支撑到多大,基本跟数据本身的大小有很大的关系
如果数据越大,那么可能导致redis的吞吐量就会急剧下降。
2、缓存维度化解决方案
维度:商品维度,商品分类维度,商品店铺维度。
不同的维度,可以看做是不同的角度去观察一个东西,那么每个商品详情页中,都包含了不同的维度数据。
如果不维度化,就导致多个维度的数据混合在一个缓存value中,那么这个就是大value了。
但是不同维度的数据,可能更新的频率都大不一样。
比如说,现在只是将1000个商品的分类批量调整了一下,但是如果商品分类的数据和商品本身的数据混杂在一起
那么可能导致需要将包括商品在内的大缓存value取出来,进行更新,再写回去,就会很坑爹,耗费大量的资源,redis压力也很大,所以就需要对商品的信息进行维度化。
维度化:将每个维度的数据都存一份,比如说商品维度的数据存一份,商品分类的数据存一份,商品店铺的数据存一份。
那么在不同的维度数据更新的时候,只要去更新对应的维度就可以了。
总而言之,我们可以把一个商品页拆分成多个维度,然后分别缓存在redis中,这样当我们要获取某个商品页时,分别去查询这几个维度的数据。然后再组装起来,就形成了我们需要的商品页,这样的好处就是避免redis中大value的存在,提高吞吐量。而且对于某个维度的更新能够做到不影响其他维度(如果是以前的大value形式,整个商品页缓存在redis中,那么如果我仅仅是只想更新商品店铺信息,那么这个时候就需要更新整个redis中的商品页,这样效率太低。分维度后,那么我们只需要去redis中更新店铺维度的信息即可,其他维度不需要变动)
三级缓存架构的技术方案怎么实现?
通常而言我们获取商品信息,那么流程就是直接发送请求到商品服务,然后获取直接返回。
那么为了增加系统的吞吐量,就有必要修改这种模式的请求。这个时候就需要三级缓存架构。
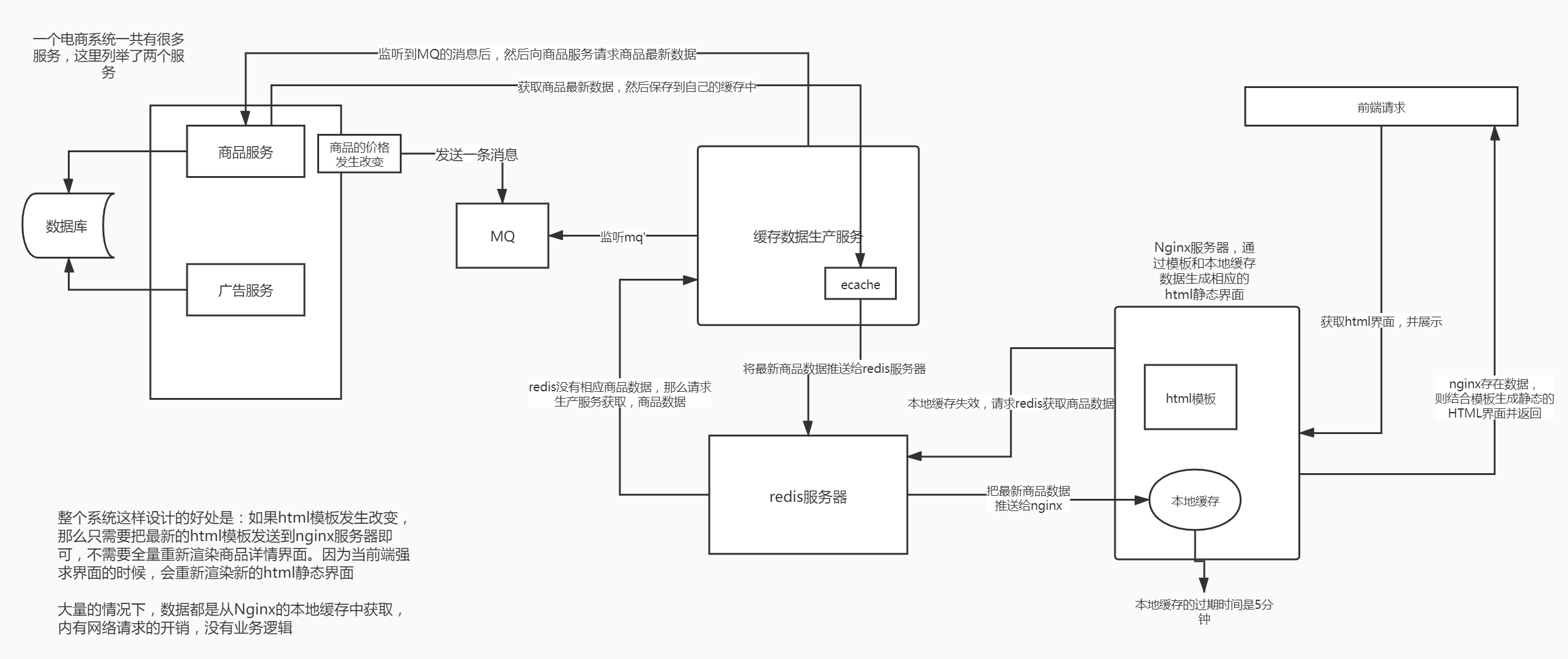
那么这个时候就需要多加一个服务:商品详情页缓存数据生产服务。那么最终客户端的请求是先落到缓存生产服务,如果缓存服务不存在(也就意味着一级缓存和二级缓存失效),才会去请求商品服务获取商品信息,然后再更新一级缓存和二级缓存。
加入商品服务某件商品属性发生了改变,那么就会往mq中发送更改后的商品信息,那么缓存服务就会订阅到这条消息,然后重建缓存(更新一级缓存和二级缓存)。
商品详情页缓存数据生产服务的工作流程分析
(1)监听多个kafka topic,每个kafka topic对应一个服务(简化一下,监听一个kafka topic)
(2)如果一个服务发生了数据变更,那么就发送一个消息到kafka topic中
(3)缓存数据生产服务监听到了消息以后,就发送请求到对应的服务中调用接口以及拉取数据,此时是从mysql中查询的。
(4)缓存数据生产服务拉取到了数据之后,会将数据在本地缓存中写入一份,就是ehcache中。(一级缓存)(防止redis二级缓存失效,所有请求打到数据库)
(5)同时会将数据在redis中写入一份。(二级缓存)
这个时候,你会发现,我们上面说的只是实现了两层的缓存,不是说有三层缓存么?那么第三层是什么呢?第三级缓存是,nginx。
那么nginx的第三级缓存怎么做呢?
采用双层的架构:分发层+应用层,双层nginx
分发层nginx,负责流量分发的逻辑和策略,这个里面它可以根据你自己定义的一些规则,比如根据productId去进行hash,然后对后端的nginx数量取模。
将某一个商品的访问的请求,就固定路由到一个nginx后端服务器上去,保证说只会从redis中获取一次缓存数据,后面全都是走nginx本地缓存了。
后端的nginx服务器,就称之为应用服务器; 最前端的nginx服务器,被称之为分发服务器。
看似很简单,其实很有用,在实际的生产环境中,可以大幅度提升你的nginx本地缓存这一层的命中率,大幅度减少redis后端的压力,提升性能。
如果没有分发层,我们想象一下,会怎么样?可能多个对同一个商品id的请求,会分别落到不同的nginx上面,那么这样就会造成,没有高效的利用之前已经从redis获取并缓存到nginx上的商品信息。也就是说会造成多个nginx上面都会有同一份商品信息,这样造成了资源浪费和命中率的下降。
所以我们需要将多同样的商品id的请求,以后都落到同个nginx,那么只需要首次去redis请求商品信息,并缓存到当前nginx,以后同样的商品id的请求,都可以直接命中nginx中首次获取的商品信息。那么分发层的作用就体现在这里了
我们分发层或者应用层,因为需要书写一些逻辑,那么就需要用到lua脚本,因为我们要用nginx+lua去开发,所以会选择用最流行的开源方案,就是用OpenResty。openresty框架整合了nginx+lua打包在一起,而且提供了包括redis客户端,mysql客户端,http客户端在内的大量的组件。所以比较方便。
那么整个三级架构的图形如下:
所以说,整个三级缓存的架构如下(假设nginx1是分发层,nginx2和nginx3是应用层)。
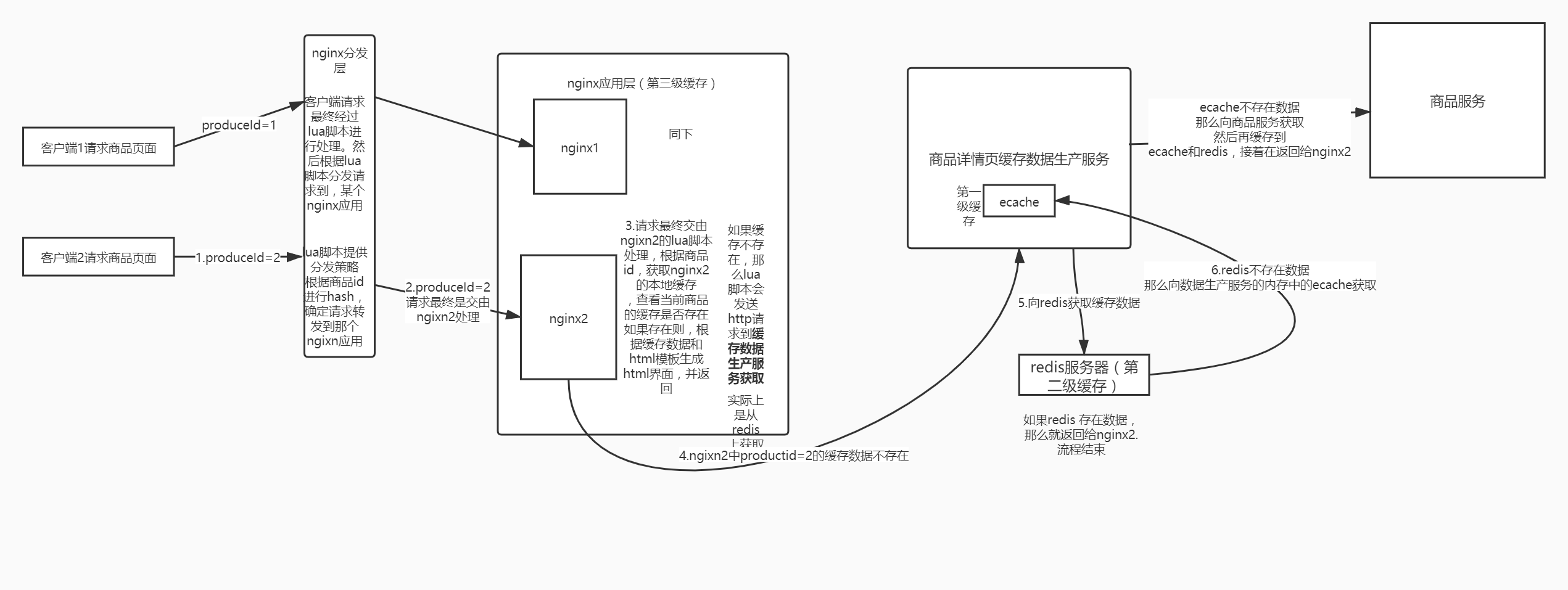
那么在nginx应用层的缓存数据,我们是可以设置过期时间的,例如时设置个6分钟。
存在问题
(1)当部署多个缓存数据生产服务,假设商品服务修改了商品信息,那么就会发送一个更新请求给mq,那么多个缓存数据生产服务就会收到消息,那么这几个服务,都会对redis和ecache进行更新。那么问题来了,可能就会存在旧数据被新数据覆盖问题,而且还有个问题那就是同一个mq更新请求,多个服务重复的进行了redis和ecache更新。
(2)这里还有个问题:就是如果你的数据在nginx -> redis -> ehcache三级缓存都不在了,可能就是被LRU(因为nginx、reddis、ehcache是会有策略进行数据清理的,当内存你不够用时,就会根据lru策略进行清理)清理掉了。
这个时候缓存服务会重新去商品服务拉数据,然后再去更新到ehcache和redis中。
这个过程就是缓存重建的过程
那么在这个过程也会有上面问题1的问题。
那么怎么解决上诉两个问题呢?
使用分布式锁,来解决,在同一个时刻,对于同一个商品的更新redis和ehcache只有一个线程执行。其他线程等待锁。
每次更新需要比对一下已有的Redis数据的版本,跟自己要更新的数据的版本,那个是最新的,如果不是最新的那么放弃更新,如果是最新的则更新。
通过分布式锁和数据版本,来控制新旧数据的覆盖问题和多个线程更新缓存的问题。
(3)问题3,如果查询的redis和ehcache都不存在,那么怎么取请求商品服务获取数据呢?如果多个线程同时访问,那么怎么解决多个请求都打到商品服务的问题呢?
其实也可以使用加分布式锁的形式。
三级缓存的实现总结
nginx+redis+ehcache
缓存冷启动问题怎么解决? - 缓存预热
什么叫缓存冷启动?:例如项目第一次上线,那么redis中是不存在数据的,那么当有请求过来时,都会打到mysql上面,那么mysql可能会直接崩溃。又或者是redis因为某种原因宕机,然后重启后,数据又恢复失败,最终有请求过来时,都会打到mysql上面,那么mysql可能会直接崩溃。
所以核心就是,redis中不存在数据,所有请求都会打到mysql。
解决方案:缓存预热
(1)提前给redis中灌入部分数据,再提供服务
(2)肯定不可能将所有数据都写入redis,因为数据量太大了,第一耗费的时间太长了,第二根本redis容纳不下所有的数据
(3)需要根据当天的具体访问情况,实时统计出访问频率较高的热数据
(4)然后将访问频率较高的热数据写入redis中,肯定是热数据也比较多,我们也得多个服务并行读取数据去写,并行的分布式的缓存预热
(5)然后将灌入了热数据的redis对外提供服务,这样就不至于冷启动,直接让数据库裸奔了
那么这个方案的最终实现是:基于storm实时热点统计的分布式并行缓存预热**
实现流程分析
1、nginx+lua将访问流量上报到kafka中
要统计出来当前最新的实时的热数据是哪些,我们就得将商品详情页访问的请求对应的流浪,日志,实时上报到kafka中。因为我们知道,客户端的请求,都是先经过nginx的分发层和应用层(上面的三级缓存架构)。
然后直接通过在nginx的应用层lua脚本(这个脚本我们可以沿用之前三级缓存中nginx2应用层中的product.lua)构造一个kafka的 producer,然后发送商品id到kafka中,完成数据的采集.
注意:在上面的三级缓存架构中,应用层使用了两个nginx,那么这个两个nginx对应的lua脚本必须都需要书写上面的逻辑,确保所有的客户端的请求都能够通知到kafka。
2、storm从kafka中消费数据,实时统计出每个商品的访问次数,访问次数基于LRU内存数据结构的存储方案
优先用storm内存中的一个LRUMap去存放,性能高,而且没有外部依赖
我之前做过的一些项目,不光是这个项目,还有很多其他的,一些广告计费类的系统,storm
否则的话,依赖redis,我们就是要防止redis挂掉数据丢失的情况,就不合适了; 用mysql,扛不住高并发读写; 用hbase,hadoop生态系统,维护麻烦,太重了
其实我们只要统计出最近一段时间访问最频繁的商品,然后对它们进行访问计数,同时维护出一个前N个访问最多的商品list即可
热数据,最近一段时间,可以拿到最近一段,比如最近1个小时,最近5分钟,1万个商品请求,统计出最近这段时间内每个商品的访问次数,排序,做出一个排名前N的list
计算好每个task大致要存放的商品访问次数的数量,计算出大小
然后构建一个LRUMap,apache commons collections有开源的实现,设定好map的最大大小,就会自动根据LRU算法去剔除多余的数据,保证内存使用限制
即使有部分数据被干掉了,然后下次来重新开始计数,也没关系,因为如果它被LRU算法干掉,那么它就不是热数据,说明最近一段时间都很少访问了
代码实现
每个task(具体实现是:ProductCountBolt对象)都会有一个LRU对象,private LRUMap<Long, Long> productCountMap = new LRUMap<Long, Long>(1000);,里面保存了,这个task处理过的商品的数量,LRUMap的key就是商品id,value是访问这个商品的数量。
3、每个storm task启动的时候,基于zk分布式锁,将自己的id写入zk同一个节点中。
逻辑在com.roncoo.eshop.storm.bolt.ProductCountBolt#initTaskId中,通过创建一个zk节点,保存了所以参与商品topN计算的task任务的id。(**方便后期我们进行缓存预热的时候,从zk中取出这个节点的值,然后遍历这些id,然后根据这个id,再去zk中取出这个id对应的task保存的他自己计算的topN数据**)
4、每个storm task(具体实现是:ProductCountBolt对象里面的ProductCountThread线程)负责完成自己这里的热数据的统计,每隔一段时间,就遍历一下task的LRUmap,然后维护一个前3个商品的list,更新这个list。
5、写一个后台线程,每隔一段时间,比如1分钟,都将排名前3的热数据list,同步到zk中去,存储到这个storm task对应的一个znode中去。
具体实现是:ProductCountBolt对象里面的ProductCountThread线程
6、我们需要一个服务,比如说,代码可以跟缓存数据生产服务放一起,但是也可以放单独的服务(服务可能部署了很多个实例)。
每次服务启动的时候,就会去拿到一个storm task的列表(也就是我们上面第3步在zk创建的znode,里面保存了所以参与商品topN计算的task任务的id),遍历这个list然后根据taskid,一个一个的去尝试获取taskid对应的znode的zk分布式锁。(避免如果部署多个缓存预热服务时,重复预热问题 )
如果能获取到分布式锁的话,那么就将那个storm task对应的热数据的list取出来。遍历这个list,取出商品id
然后根据商品id将数据从mysql中查询出来,写入缓存中,进行缓存的预热(写入redis和ehcache)。
具体实现,请看代码:com.kingge.produce.cache.prewarm.CachePrewarmThread
缓存热点问题
热点缓存问题:促销抢购时的超级热门商品可能导致系统全盘崩溃的场景(秒杀、抢购)。
他跟缓存预热是不一样的,缓存热点强调的是,瞬间的对缓存中某个商品的访问次数异常的高。
热点数据,热数据,不是一个概念
有100个商品,前10个商品比较热,都访问量在500左右,其他的普通商品,访问量都在200左右,就说前10个商品是热数据,统计出来。
预热的时候,将这些热数据放在缓存中去预热就可以了。
热点,前面某个商品的访问量,瞬间超出了普通商品的10倍,或者100倍,1000倍。
那么怎么解决呢?
基于nginx+lua+storm的热点缓存的流量分发策略自动降级解决方案
流程也是跟上面的数据预热一样,但是有些许区别。
(1)通过storm识别出热点数据
怎么识别?
|
(2)storm这里,首先先发个请求给nginx分发器层,让他缓存一下某个商品的id是热点数据,这样我们就可以在分发层判断一下如果是热点数据,那么就不再需要根据商品idhash分发到应用层,而是采取堆积负载均衡策略发送到所有应用层nginx。,然后接着直接把热点数据直接通过http请求发送到所有的应用层nginx上,nginx上用lua脚本去处理这个请求。然后把热点数据都缓存到所有ngixn应用层。
分发层需要做的事情
例如stom后端程序发送到分发层的请求是:http://192.168.31.227/hot?productId=123
1.那么就需要在nginx分发层,建立一个lua脚本处理hot请求。
|
2.紧接着修改分发层ngix的分发lua脚本
|
应用层nginx需要做的事情
假设stom发送给应用层nginx的请求是:http://192.168.31.187/hot?productId=123&productInfo={price=123;name=123}
其中productInfo保存了,热点商品数据的信息,这部分信息是需要当前应用层nginx缓存到本地的。
1.那么就需要在nginx应用层,建立一个lua脚本处理hot请求,缓存热点数据到本地
|
经过上面ngixn分发层和应用层的改造,我们成功在ngixn层,缓存好了热点数据。这样当热点数据的访问量剧增时,也能够很好的hold住。
(3)流量分发nginx的分发策略降级
流量分发nginx,加一个逻辑,就是每次访问一个商品详情页的时候,如果发现它是个热点,那么立即做流量分发策略的降级。(以前我们的分发策略是:hash策略,同一个productId的访问都同一台应用nginx服务器上)
但是如果识别出访问的商品id是热点数据,那么降级成对这个热点商品,流量分发采取随机负载均衡发送到所有的后端应用nginx服务器上去(因为我们在第二步,已经把热点数据都分别缓存到了所有应用层的nginx)**。
避免说大量的流量全部集中到一台机器,50万的访问量到一台nginx,5台应用nginx,每台就可以承载10万的访问量。
(5)storm还需要保存下来上次识别出来的热点list
下次去识别的时候,这次的热点list跟上次的热点list做一下diff,看看可能有的商品已经不是热点了。
热点的取消的逻辑,发送http请求到流量分发的nginx上去,取消掉对应的热点数据,从nginx本地缓存中,删除。
详情代码实现
参见com.kingge.produce.storm.bolt.ProductCountBolt.HotProductFindThread
|

